1. The Thurstone Model
The Thurstone Model
声明:本文为本人毕业研究报告《The Exploration of Pairwise Comparison in Football Application》中的部分内容摘录与整理,仅用于学习与交流。
Introduction
The method of paired comparisons, originally proposed by Thurstone [1], is a cornerstone of psychometrics and preference modeling. It provides a statistical framework for inferring psychological scales from pairwise choices or judgments.
Thurstone’s model is a method for sensory difference testing that ranks various stimuli on a perceptual scale for comparative analysis. In this model, a set of stimuli denoted as
The sensation continuum
The following model formulation encapsulates a concise mathematical summary of Frederick Mosteller’s [2] idea, transforming his conceptual research into a structured mathematical model.
Model Foundation
Given
and are jointly normally distributed with parameters: - Mean of
is for . - Variance of
is for all .
- Mean of
- The correlation between
and is denoted by and assumed to be the same for all pairs where and .
For each
where the joint mean
and the joint covariance matrix
with
Remark:
Thurstone’s original Case V assumed zero correlation () among stimuli, but Mosteller [2] demonstrated that Case V also holds if all pairwise correlations are merely equal, i.e., for all . This relaxed condition is more reasonable in practical data analysis.
For further explanation of Model Foundation. The covariance of two random variables
where
The correlation coefficient between
where
Since
Thus,
where
The joint covariance matrix is defined as:
Note that
Now, we know the foundation of the model. However, there is an issue that has to be solved while building the model. Let’s look at Figure 1: there is
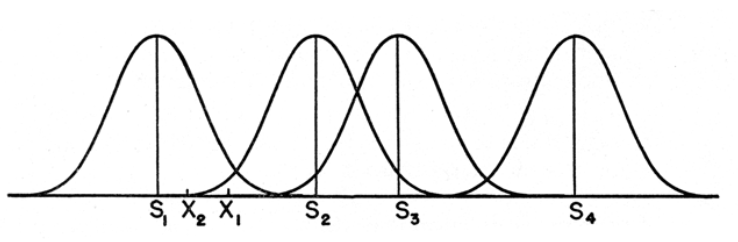
Therefore, when comparing two stimuli, individuals are required to make a definitive choice between them, so there is no tie in comparison. This binary (yes/no) outcome is crucial for determining the probability (
The assumption is that in an idealized scenario, researchers know the exact proportion of times one stimulus is perceived as stronger than another. This knowledge allows them to precisely calculate the spacing of stimuli on the sensation continuum, reflecting not just the order in which stimuli are ranked but also the magnitude of differences between them.
Objective
Our aim is to determine the relative spacings of a set of stimuli, denoted by
Note:
The scale valuesare only determined up to a linear transformation (i.e., they are relative positions), reflecting the inherent arbitrariness of the zero point and scale in psychological measurement.
Model Formulation 1
Let
The probability of preference
where
is the difference in sensations between stimuli and . defines the variance of the difference in sensations.
The integral calculates the area under the curve of the PDF for
To simplify for
Given
Example 1
Consider a football scenario where we want to assess which of two players, Player A and Player B, might perform better in terms of goal scoring in a specific match based on their past performance. Assume their goal-scoring abilities are normally distributed sensations
Let:
So,
To find
Using a standard normal distribution table,
So, Player A has a 61.79% chance to score more than Player B.
Application:
The Thurstone model is widely used in product taste testing, consumer preference studies, psychological ranking tasks, and any context requiring conversion of paired choice data into a latent scale.
Model Derivation 1
Assume two normally distributed random variables
- Mean of
:
- Variance of
:
A random variable
Apply to
Compute the probability
Now, to normalize variance, set:
This aligns the distribution with the standard normal
So, change of variable for the integration:
Conclusion
To sum up, the Thurstone model [2] is based on the idea of a continuum where each item (or stimulus) has a location that represents its "strength" or preference level. The probability of preferring stimulus
However, the Thurstone framework actually includes several "cases":
- Case V: Assumes equal variances and equal (often zero) correlations (as discussed here).
- Cases III and IV: Allow for unequal variances and/or unequal correlations; they are mathematically more general but computationally more complex [1,2].
However, the Thurstone model, while complex in its probabilistic approach to preference analysis, is limited by its dependence on a normal distribution and a constant correlation between stimuli. These assumptions may not hold in real-world scenarios, making the model computationally intensive and less suitable for large datasets or environments requiring quick decisions.
The simplified equation represents the prototype of the Bradley-Terry model [3], which resolves these issues by simplifying the distribution assumptions into a simple ratio-based model, enhancing both computational efficiency and applicability.
References
- [1] L.L. Thurstone. Psychophysical analysis. American Journal of Psychology, 38:368–389, 1927.
- [2] Frederick Mosteller. Remarks on the method of paired comparisons: I. The least squares solution assuming equal standard deviations and equal correlations. Psychometrika, 16(1):3–9, 1951.
- [3] Ralph Allan Bradley. Some statistical methods in taste testing and quality evaluation. Biometrics, 9(1):22–38, 1953.
- [4] J. P. Guilford. Psychometric Methods. McGraw-Hill Book Co., 1936.
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付