7. InstructGPT 详读
InstructGPT 详读
本文并非全部翻译,但尽可能的保持文章原意。有逻辑的描述论文的思路,实验。并加了一些理解与例子的备注,如果需要快速了解本文精华内容,可以参考另外一篇总结性文章。
Abstract
-
问题背景:只让语言模型变大,并不能更好的让它按用户的意图办事。模型规模再大,也可能胡说八道、输出有害内容或者根本没帮上忙。—— 模型和人类想法 没有对齐。
-
提出方法:本文探索了一条新路:用人类的反馈 微调模型(fine-tuning models with human feedback),让模型更好地对齐用户意图、适应各种任务。
- 首先:收集人工编写的指令(prompts)和用户API提交的指令,再加上人工演示的理想回答,用这些数据对GPT-3做监督微调。
- 然后:让人类给不同模型输出结果打分,收集“排名数据”,用人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)再做一轮微调。
- 这种通过 人类反馈微调 得到的模型,被命名为InstructGPT。
-
实验结论
- 在人类真实评价中,即使InstructGPT参数只有1.3B,也比超大号的175B GPT-3更受欢迎。
- InstructGPT在减少虚假、有害内容上表现更好,在公开NLP任务上几乎没有性能损失。
-
意义与前景:虽然InstructGPT还会犯一些简单错误,但实验证明,“用人类反馈来微调大模型”是一条让AI更懂人、更合用户心意的可行路线。
1. Introduction
大语言模型(LMs)可以通过给定一些任务示例作为输入来执行多种NLP 任务。然而,这些模型经常表现出一些不期望的行为,比如编造事实、生成有偏见或有害的文本,或根本不遵循用户指令。
根本原因在于,现有语言模型的训练目标是预测下一个词,而不是遵循用户的意图。大语言模型的目标更多地是在网络语料上进行语言生成,而不是按用户的要求生成准确且有帮助的内容。
因此,我们认为语言建模目标是“未对齐”的,需要调整目标方向,特别是在这些模型应用于许多实际场景时,行为“对齐”用户意图显得尤为重要。
我们通过训练语言模型,使其按照用户的意图执行任务,取得了进展。这包括明确的意图,如遵循指令,以及隐含的意图,如保持真实、不偏见、不有害等。
定义模型目标:
- 希望语言模型是有用的(它们应该帮助用户完成任务)
- 诚实的(它们不应编造信息或误导用户)
- 无害的(它们不应对人类或环境造成身体、心理或社会上的伤害)
核心方法:使用来自人类反馈的强化学习对GPT-3进行微调,让其遵循更广泛的书面指令。
- 第一阶段:雇佣人员来标注数据,基于其在筛选测试中的表现来选取合适的标签员。这是微调的第一步,确保数据质量。
- 第二阶段:通过收集人类写的示范数据,包括OpenAI API上提交的提示语(英文)和标签员编写的指令,来训练基准模型。这样做可以帮助我们了解理想输出的表现。
- 第三阶段:收集更多的人工标注数据,进行模型输出之间的比较,进一步完善模型的行为。
- 第四阶段:训练一个奖励模型(Reward Model, RM),用于预测标注人员更偏好的模型输出。最后,我们将这个 RM 作为奖励函数,结合PPO算法对初始的监督学习模型进行微调。微调后的模型名称:InstructGPT。
- 如图展示过程,这个微调过程专注于满足特定群体(如标签员和研究员)的偏好,而不是广泛的“人类价值观”概念,后续会进一步探讨这一点。
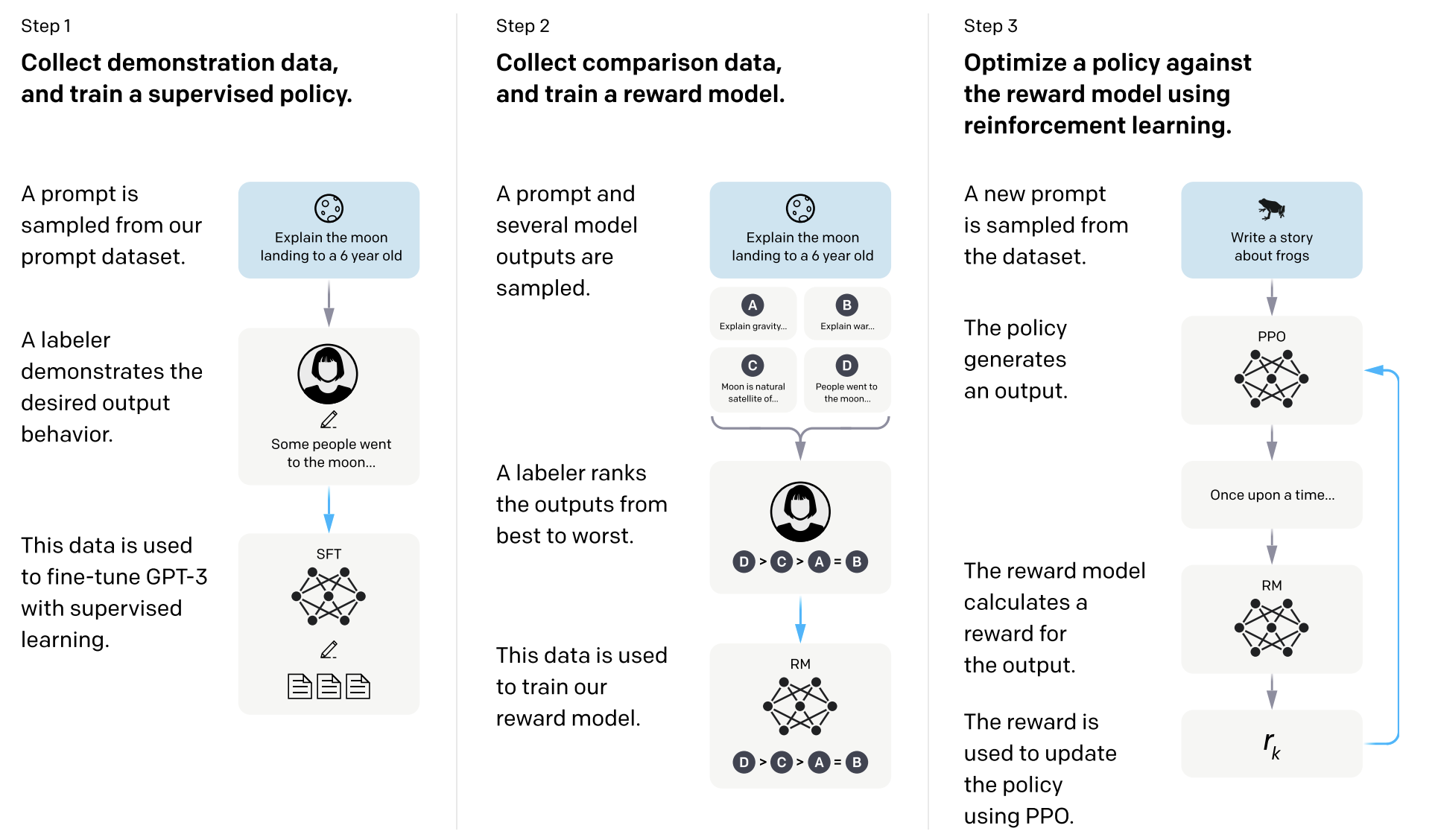
Step 1:收集示范数据,训练监督模型
- 从prompt数据集中随机抽取一个指令(比如“用6岁小孩能懂的话解释登月”)。
- 标注员写出理想的回答(比如“有些人去了月球…”)。
- 用这些高质量的“人类演示”数据,做GPT-3的监督微调(SFT,Supervised Fine-Tuning)。
- 目的:让模型先学会“照着人类做”怎么答题。
Step 2:收集比较数据,训练奖励模型
- 用同样的prompt(比如“用6岁小孩能懂的话解释登月”),让多个模型输出不同答案(A、B、C、D)。
- 标注员把这些答案从好到坏排个序(比如
)。 - 用这些“人类偏好排序”数据训练一个奖励模型(Reward Model,RM),让RM学会“猜出”人类会喜欢哪个答案。
- 目的:奖励模型相当于一个“裁判”,用来给新生成的答案打分。
Step 3:用奖励模型做强化学习
- 再来一个新prompt(比如“写个关于青蛙的故事”)。
- 让模型(policy)生成输出(比如“一只青蛙从前有个梦想…”)。
- 奖励模型(RM)对这个答案打分,输出奖励值
。 - 利用PPO算法(Proximal Policy Optimization),根据奖励值更新模型,让它下次输出得分更高的答案。
- 目的:通过“试错+打分+学习”,让模型不断进步,更贴合人类喜好。
先让模型学会人类怎么做(监督微调),
再让它知道什么样的答案更受欢迎(奖励模型),
最后用强化学习,不断调整自己,让输出越来越“人味儿”(PPO模型)。
标签员更喜欢InstructGPT的输出
- 结论:即使InstructGPT参数只有1.3B,也比175B的GPT-3更受欢迎
- 原因:架构相同,唯一不同点是InstructGPT用人类反馈做了微调。
- 细节:在测试集上,标签员在85% ± 3%的情况下更喜欢InstructGPT(vs 175B GPT-3的few-shot设置下是71% ± 4%)。
InstructGPT的“诚实度”比GPT-3提升
- TruthfulQA基准测试:InstructGPT回答得更真实、更有信息量,正确率约是GPT-3的2倍。
- 不仅如此:在一些非针对性选择的问题子集上表现同样优秀。
- 闭域任务(Closed-domain):InstructGPT编造信息的概率比GPT-3低很多(幻觉率21% vs 41%)。
- 一句话:InstructGPT胡说八道(幻觉hallucination)的次数直接砍半!
有害内容(toxicity)略有改善,偏见(bias)没变
- 测试方式:用RealToxicityPrompts数据集,自动+人工一起评测。
- 结果:InstructGPT比GPT-3生成有害内容的概率低约25%。
- 局限性:
- 在要求模型“尊重”时,InstructGPT并没有比GPT-3更好。
- 偏见方面(用Winogender和CrowSPairs测试),InstructGPT没啥改进。
公开NLP数据集上的性能下降可以被控制
- 问题:在用人类反馈强化学习(RLHF)微调时,InstructGPT在某些公开NLP任务(如SQuAD、DROP、HellaSwag、WMT翻译)上的表现比GPT-3差(叫做“alignment tax”,对齐成本)。
- 解决办法:作者通过调整PPO更新方式(比如混合一些让模型更贴合原始预训练分布的数据),可以大幅减少这类性能下降,同时不损失人类偏好分数。
模型泛化到新标签员(Held-out Labelers)
- 实验结果 :使用一组从未参与训练的全新标签员对模型输出进行评估,结果显示他们也倾向于更喜欢 InstructGPT 生成的结果,这与训练中使用的标签员的偏好一致。
- 局限性 :尽管如此,仍需进一步研究模型在更广泛用户群体中的泛化能力,尤其是在不同用户对“理想输出”存在分歧的情况下,模型会如何表现。
举个例子来说明:
假设你训练了一个语言模型来回答问题,比如写一篇关于“是否应该吃肉”的议论文。
情况一:用户 A(素食主义者)
他希望模型写出一篇反对吃肉的文章,强调环保、动物权利和健康饮食。情况二:用户 B(肉食爱好者)
他希望模型写出中立甚至支持吃肉的文章,强调营养均衡、文化传统和食品自由。这两个用户对“理想输出”有完全不同的看法。这时候,模型就会面临一个难题:
- 如果偏向 A,B 会不满意;
- 如果偏向 B,A 又会觉得模型立场偏颇;
- 如果保持中立,可能两方都不满意。
它指出当前模型(如 InstructGPT)虽然在多数情况下可以生成高质量、符合人类偏好的回答,但在面对主观性强、意见分歧大的问题时,其泛化能力仍然存在不确定性。
公开NLP数据集不代表真实用法
- 发现:用人类偏好数据微调的InstructGPT,和在公开NLP任务集(如FLAN、T0)上微调的GPT-3做对比,发现:
- 在API真实用户任务分布上,公开NLP集微调的模型略差于SFT基线,标签员明显更喜欢InstructGPT。
- InstructGPT在API用户的实际任务中胜率(73.4%±2%)远高于T0(26.8%±2%)和FLAN(29.8%±2%)。
泛化能力:新任务/语言也能对齐
- 实验:InstructGPT不仅能做微调集里常见的任务,还能做如代码总结、回答编程问题、处理多语言指令等新任务(虽然这些任务在微调数据中很稀少)。
- 对比:GPT-3虽然也能做这些任务,但需要更多技巧性prompt,且通常执行指令的能力不如InstructGPT。
依然会犯低级错误
- 缺点:模型有时还是会,
- 没按指令来
- 编造事实
- 简单问题回答太啰嗦
- 没识别出假设错误的指令
提醒:AI没变成完美助理,还在进化路上。
2. Related work
1. 对齐和从人类反馈中学习的研究
- RLHF最早不是给大语言模型设计的,而是用在机器人训练(比如仿真环境下的机器人、Atari游戏等)。
- 后来,这套技术才被引入到大语言模型微调(比如做摘要、对话、翻译、语义解析、故事生成、评论生成、证据抽取等任务)。(引用一大堆论文。)
- 现在,RLHF被用来增强GPT-3类模型的prompt响应能力,让模型在各种NLP任务中更贴合用户需求。
- 还有一些工作在文本环境下对齐智能体行为(比如给定规范性先验,让智能体行动更“合规”)。
- 本文就是直接把RLHF用来对齐大语言模型在各种NLP任务上的行为,是“人类反馈对齐技术”的一次大规模实战应用。
- 近期也有不少论文在讨论 “什么才算对齐”。(Gabriel 2020)
- 有人系统梳理了对齐失败会带来的坏处,比如生成有害内容、玩规则漏洞等(Kenton等2021)。
- 还有人提出用“语言助手”做对齐测试平台,研究对齐基线和可扩展性(Askell等2021)。
2. 训练语言模型遵循指令(Instruction Following)
- 这类工作一般把大模型在各种带有指令的数据集上做微调,然后用其他NLP任务评测模型泛化能力。
- 实验上大家关注点不同:训练/测试用的数据、指令格式、预训练模型大小等。
- 一致结论:只要让模型在多种指令类任务上微调,模型在未见过的新任务(zero-shot/few-shot)上的表现都会提升。
- 还有一类研究关注用自然语言指令控制机器人/导航智能体,即在仿真环境里让模型学会“听指令走路”。
3. 评估和缓解语言模型的“有害行为”
- 很多研究在总结/揭示大模型在真实世界的风险,比如:
- 生成有害内容(toxic)、偏见输出(biased)、泄露隐私、生成虚假信息(misinformation),甚至被用于恶意用途等。
- 现在也有很多基准数据集,专门用来量化评测这些风险(toxicity、stereotypes、social bias等)。
- 难点:想通过技术手段让大模型变“更好”,结果可能会产生副作用,比如让模型更少输出有害内容的同时,也让它更难表达“弱势群体”的内容(训练数据偏见带来的问题)。
4. 如何调控大模型,减少有害输出
- 微调在小规模、价值导向的数据集上,可以提升模型遵守特定价值观的能力,但会略微降低整体性能。
- 过滤预训练数据,去掉容易引发有害输出的内容,让模型学不到“危险话术”,代价是部分任务表现下降。
- 对话/生成安全性提升手段包括:数据过滤、屏蔽某些词/n-gram、加入安全控制token、人工循环采集等。
- 降低偏见与有害输出的方法包括:词嵌入正则化、数据增强、分布均匀化、不同优化目标、因果分析等。
- 有研究尝试用第二个(较小)语言模型“驾驭”主模型,或变体方法来进一步减少有害内容。
3. Methods and experimental details
3.1 High-level methodology
- 如Intro里面讲的详细例子
- 以一个预训练语言模型为起点,准备一套prompts和一支受过训练的人工标注团队。
- 方法分为三步:
- Step 1: 收集人类演示数据,并用其训练监督模型
- 标注员针对prompts演示理想输出,用这些数据对GPT-3进行监督微调。
- Step 2: 收集对比数据,并训练奖励模型
- 收集同一输入下不同模型输出的偏好排序数据,训练奖励模型预测人类更喜欢的输出。
- Step 3: 使用PPO强化学习优化模型
- 以奖励模型的分数为奖励,使用PPO算法对模型进行强化学习微调,让其最大化人类偏好。
- Step 1: 收集人类演示数据,并用其训练监督模型
- 步骤2和3可以循环迭代,每次用最新策略收集更多对比数据,训练更好的奖励模型和新策略。
- 实际操作中,大部分对比数据来自监督模型,小部分来自PPO微调模型。
3.2 Dataset
- 主要数据集来自用户通过OpenAI API(Playground界面)提交的文本prompts,部分用早期InstructGPT模型生成。
- 用户被明确告知数据可能会用于后续模型训练,每次使用Playground时会收到提醒。
- 论文不使用生产环境API用户的数据,只用Playground和实验用数据。
- 去重方式:检测长前缀重复的prompts,并限制每个用户最多200条。
- 按用户ID划分 train/validation/test 集,保证同一用户的数据只在一个分集里,防止“数据泄漏”。
- 所有训练集prompts都做了个人敏感信息(PII)过滤,避免模型学习到隐私内容。
- 早期InstructGPT模型训练时,还需要标注员自己编写三类prompt来补充:
- Plain:随机构思多样任务,保证任务多样性。
- Few-shot:写一条指令和多个输入/输出示例,模拟few-shot学习。
- User-based:根据API用户排队等候申请时给出的实际用例,由标注员写出真实需求相关的prompt。
- 从前述prompts中,InstructGPT训练过程用到了三种数据集:
- SFT dataset:标注员演示“理想答案”的数据(约13k条,来自API和人工编写),用来做监督微调(Supervised Fine-Tuning)。
- RM dataset:模型输出的对比排序数据(约33k条,API和人工编写),用于训练奖励模型(Reward Model)。
- PPO dataset:只有模型自己生成、没有人工标注的prompts(约31k条,只来自API),用于PPO强化学习微调。
- 关于数据集构成:以RM数据集为例,大多数用例是“生成型任务”,而不是分类或问答任务。(附录里还展示了一些典型prompt示例、数据分布细节)
- Plain(朴素方式):随机构思保证任务多样性
- 随意写一个任务指令,不需要示例。
- 例子:请帮我列出5个常见的蔬菜名称
- 西红柿、胡萝卜、紫甘蓝、包菜、生菜
- Few-shot(少样本方式):写一条指令 + 多个输入/输出示例
- 每个 prompt 包含一个明确的任务指令,再加上几个输入输出对作为例子。
- 这是为了模拟人类在看到少量示例后就能理解任务的方式(类似 few-shot learning)。
- 例子:把中文翻译成英文
- 输入:我喜欢苹果。
- 输出:I like apples.
- 输入:今天天气不错。
- 输出:The weather is nice today.
- 现在请翻译:这本书很有趣。
- User-based(用户驱动方式):基于真实用户需求构造prompt
- 根据真实 API 用户在申请访问时提供的使用场景,由标注员构造与之相关的 prompt。
- 更贴近实际应用场景,用于评估模型在真实用户需求下的表现。
- 例子:假设某个用户申请 API 时说:我想让模型帮我生成社交媒体上的产品推广文案。
- 于是标注员根据这个需求构造了如下 prompt:
- 根据以下信息生成一段 Instagram 推广文案:
- 产品名称:夏日柠檬气泡水
- 特点:低糖、无卡路里、天然风味
- 风格:轻松、年轻、适合夏天
3.3 Tasks
- 任务数据来自:标注员自写prompt和API用户提交的prompt。
- 涉及内容:文本生成、问答、对话、摘要、信息抽取等多种NLP任务,绝大多数为英文。
- 指令形式:包括直接自然语言指令、few-shot示例和续写任务。
- 标注员需判断用户意图、避免不明确任务,并关注回答真实性和有害内容。
3.4 Human data collection
- 雇佣约40名标注员(Upwork、ScaleAI),涵盖多样人群,专注识别有害内容和敏感话题。
- 通过筛选测试选出表现优异的标注员,培训并持续答疑。
- 训练过程中如遇用户请求有害内容,优先考虑“有用性”;评估时则更重视“真实性”和“无害性”。
- 另设未参与训练的标注员做泛化测试,结果显示不同标注员之间的一致性较高(72.6%±1.5%),与同行论文一致。
3.5 Models
论文以GPT-3的预训练语言模型(Brown等,2020)为基础,作者通过三种不同的技术对模型进行训练:
监督微调(SFT)
- 在标注员演示的数据上对GPT-3进行监督微调。
- 训练过程为16个epoch,采用余弦学习率衰减和0.2的残差dropout。
- 最终SFT模型的选择是基于验证集上的奖励模型(RM)分数。
- 与Wu等(2021)类似,作者发现SFT模型在1个epoch后就会在验证损失上过拟合;但即使存在过拟合,增加训练epoch数仍然有助于提升奖励模型分数和人工偏好评分。
奖励建模(RM)
- 在SFT模型的基础上,去掉最后一层embedding,再训练一个奖励模型,使其能够输入prompt和response,输出一个标量奖励分数。
- 本文只用6B参数规模的RM,这样计算开销较小,同时作者发现175B规模的RM训练起来不稳定,不适合作为强化学习中的价值函数(详细见附录C)。
- 参照Stiennon等(2020),奖励模型是在一个对比数据集上训练的,该数据集包含同一输入下两个模型输出的对比。
- 奖励模型的训练采用交叉熵损失,比较哪个输出更受人工标注员青睐。奖励分数之差代表一个输出被人类偏好于另一个输出的对数概率。
对比数据训练方式
按照Stiennon等人(2020)的方法,奖励模型(RM)是在一组“两个模型输出的对比数据”上训练的。每个输入prompt有两个不同的输出,让标注员选择更好的那个。训练时用交叉熵损失,标签就是人工选择的偏好。两个输出reward分数之差代表一个答案比另一个更可能被人类喜欢的对数几率。
加速对比数据收集的方法
- 标注员每次会拿到K个(
)模型输出,让他们进行排序,这样每个prompt可以得到 对比样本(所有两两组合)。 - 因为这些对比高度相关,如果直接打乱后做一次性训练,奖励模型容易过拟合。
- 作者的做法是:每个prompt的所有对比视为同一个batch元素一起训练,这样只需要对每个输出做一次前向计算(更高效),也能避免过拟合,提升验证集表现。
奖励模型的损失函数
- 损失函数写作:
- 其中:
:奖励模型对prompt 和输出 的标量分数(参数为 )。 :同一个prompt下,两组输出中被人类认为“更优”和“较差”的答案。 :全部人工标注对比数据集。 :sigmoid函数,保证输出落在 区间。 :每个prompt中输出的两两组合总数。
奖励模型
是在监督微调(SFT)之后单独训练的,其目标是模拟人类对模型输出的偏好(通过标注的排序数据)。 对于prompt
,取出一对 ,假设 比 排序高。首先把 (问题 和回答 )输入到奖励模型 中计算出分数,然后减去关于 的奖励分数。我们希望这个差值越大越好,最后通过sigmoid函数、log加负号的方式构成损失函数。具体而言,这是一个Logistic Regression 的二分类问题 ,目标是让 的分数尽可能大, 的分数尽可能小。当 时,理想情况下,我们能从1次排序中生成36对样本( )。 排序4个答案可能要30s,排序9个答案大概只要40s,加上读题时间,时间其实只多了30% ~ 40%,并没有成倍增长。但由于9个答案能产生36个排序对,而4个答案只能产生6个,所以用差不多的人工时间,标注信息却多了6倍。极大提升数据效率,这是很赚的地方。
最贵的部分是
的计算。对于6B的GPT-3模型,虽然每次计算涉及到36个对比样本,但实际只需要做9次前向传播。如果某个输出的分数已经计算出来,可以在后续对比中复用这个结果。这样,我们通过复用前向计算结果,将36次计算减少到9次,节省了大约4倍的时间。如果 ,每次只选出最优答案(一个对比对),模型容易过拟合,因为样本数量太少。
强化学习(RL)
- 奖励模型(RM)的损失对奖励的平移不敏感,因此训练RL前,需要对RM做归一化处理,让标注员演示数据的均值为0。
- 按照Stiennon等人(2020),在PPO(Proximal Policy Optimisation,Schulman等,2017)框架下,用SFT模型作为起点,针对每个用户prompt进行强化学习。
- 环境是bandit类型,随机给出一个用户prompt,模型返回response,RM根据prompt+response计算reward,回合结束。
- 为了防止RL过程中过拟合奖励模型,在每个token处都加一个来自SFT模型的KL散度惩罚项(让RL模型不要偏离SFT分布太远)。
- RL中的value function由奖励模型初始化,这些RL模型被称为“PPO”。
- 进一步实验:
- 在PPO更新中混入预训练梯度,缓解模型在公开NLP数据集上的性能下降(alignment tax),这种模型称为“PPO-ptx”。
- RL优化目标变为:
:RL学到的策略(模型) :监督微调后的策略 :预训练分布 :KL惩罚项系数, :预训练梯度项系数,控制各自强度
- “PPO”模型里
,“PPO-ptx”则
- 特别说明:
- 文中默认“InstructGPT”指的就是PPO-ptx模型(即RLHF+预训练梯度混合版)。
强化学习的PPO也是OpenAI之前的工作,核心是通过在目标函数
上做随机梯度下降 来更新 policy。在RL中,策略(policy)由模型参数化,即我们要学习的模型 ,它通过生成动作(action)输出结果 。一旦生成 ,环境会通过奖励模型 给这个回答打分,但模型本身不会改变环境(因为任务只有一轮交互)。 初始化为监督微调后的模型 ,通过不断更新参数 让目标函数 的值最大化。 三个数据集之一在线强化学习数据集
(约31,000个固定prompt)。每次取一个prompt ,输入当前 模型生成回答 ,再用训练好的奖励模型 计算reward。每次迭代 是固定的, 随着policy更新会变化,reward也会变化。 为何需要奖励模型
?因为人类标注的数据是排序(如 ),而不是具体分数或正确答案。如果每次生成 后都让人重新标注排序(在线学习Online Learning),成本太高了,所以我们需要训练一个 来模拟人类打分。 随着
的不断更新,模型生成的新 可能和奖励模型训练时用的 逐渐偏离,导致reward变得不准,为了防止这个问题,我们在目标函数里加了一个KL散度惩罚项 ,KL散度其实就是用来衡量两个模型输出概率分布的差异,具体来说,就是比较现在的策略( )和最初SFT模型( )生成答案的概率差别。我们希望KL越小越好,最好为0,说明两个分布几乎一样,加个负号就是鼓励模型尽量别跑偏,输出保持稳定。 如果直接用前面两项,可能模型只对当前任务的输出产生很好的性能,但对其他任务的性能下降(用于缓解alignment tax:模型在追求人类偏好的过程中可能损失通用任务性能 ,泛化能力)。所以
它复用了原来 GPT-3 的预训练目标(损失函数)又拿了回来了。超参数 控制它偏向原始数据的强度: 时仅优化RM的目标(PPO 模型); 时引入预训练梯度(PPO-ptx 模型)。 PPO目标函数的三项:
:模型生成答案后,奖励模型给分,分越高越好。 - KL惩罚项:限制策略别偏离原本SFT模型太远,防止输出越来越离谱。
- 预训练损失(可选):让模型还能保持原来GPT的泛化能力,不只会讨好人类。
Baselines(对比基线)
- PPO模型的效果与SFT模型和GPT-3原模型进行对比。
- 还与175B GPT-3在few-shot prefix下进行对比(即先给一段指令示例,再用GPT-3生成,这叫GPT-3-prompted)。
- 还用175B GPT-3在FLAN(Wei等,2021)和T0(Sanh等,2021)这两个包含多种NLP任务和自然语言指令的大型数据集上做微调,与InstructGPT进行对比。这些模型大约各训练了100万条数据,最终选用在验证集RM分数最高的checkpoint。
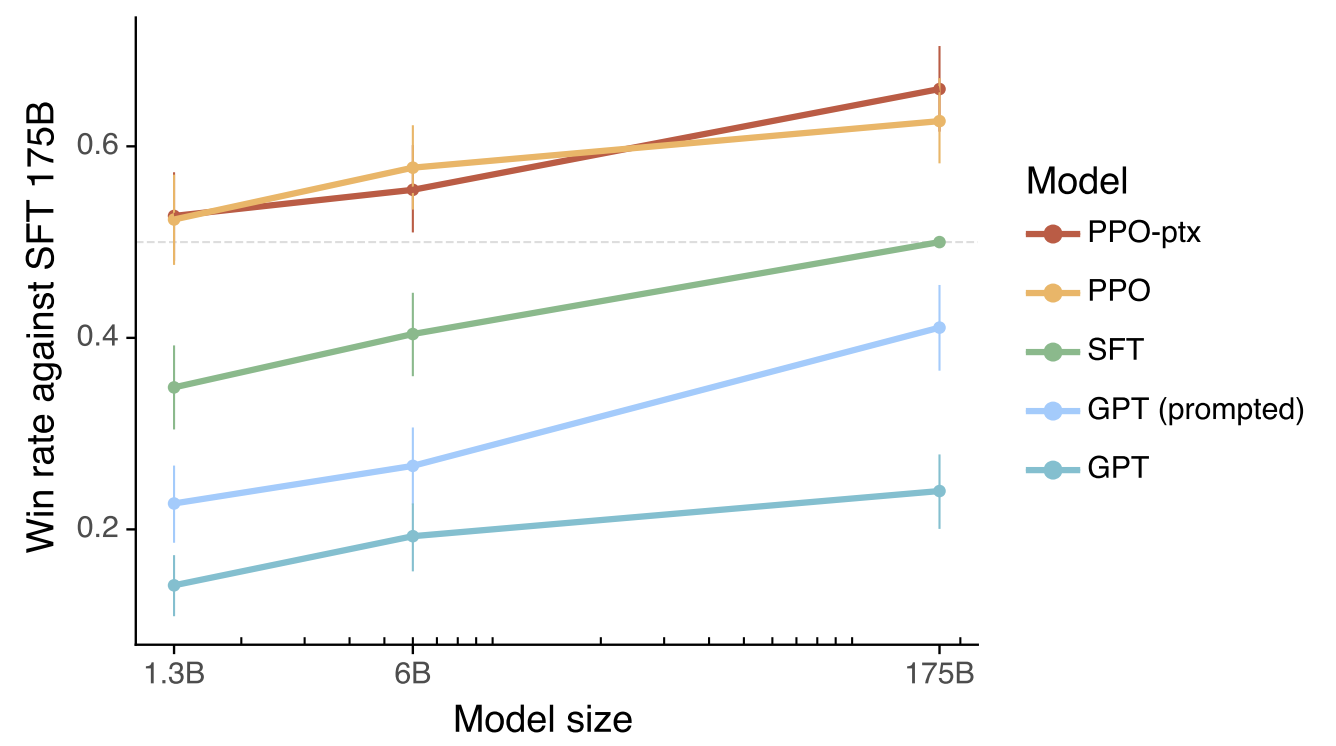
单纯提升GPT-3参数规模(1.3B到175B),效果提升有限;
加入人类反馈微调(SFT)后,模型表现大幅跃升,远超同规模纯GPT-3;
进一步用RL(PPO和PPO-ptx)训练,效果比SFT显著更好;
这说明,光堆算力和数据不如用人类反馈好,方法比规模更重要。
3.6 Evaluation
-
对齐的定义:
要评估我们模型的“对齐”程度,首先需要明确“对齐”在此处的含义。由于对齐的定义历史上一直模糊且有多个不同的提议(Chen等,2021;Leike等,2018;Gabriel,2020),作者借鉴了Askell等(2021)提出的框架,定义了三个“对齐标准”:- 有帮助:模型能执行用户指令。
- 诚实:模型陈述的内容应当真实。
- 无害:模型输出不会对人类造成伤害。
-
有帮助:
- 模型应能够遵循指令,并从few-shot提示中推断出意图(例如“写一篇关于‘青蛙’的故事”)。
- 由于给定prompt的意图可能不清楚或含糊,标注员的判断尤为重要。我们的主要评估标准是标注员的偏好评分。
-
诚实:
- 在纯生成模型中,如何衡量“诚实”是一个复杂的问题。生成模型的输出与它“相信”的正确输出之间很难直接比较。
- 作者采用了两个指标来衡量真实度(truthfulness):
- 评估模型在闭域任务中的“虚构”倾向(如“幻想”问题)。
- 使用TruthfulQA数据集(Lin等,2021)来评估模型是否提供真实的信息。
- 尽管如此,诚实的衡量方式仅捕捉了真实度的一个小部分。
-
无害:
- 衡量语言模型的有害性存在诸多挑战。模型生成的有害内容是否有害取决于其实际应用场景。例如,在部署的聊天机器人中生成有毒内容可能是有害的,但如果用于数据增强训练更精确的有害内容检测模型,可能反而是有益的。
- 在项目的早期阶段,标注员会评估某个输出是否“潜在有害”。然而,考虑到数据来自Playground API的用户,我们停止了这一做法,因为它涉及过多的猜测,尤其是这些数据来自与生产环境不直接相关的用户。
-
评估有害性的替代标准:
由于“潜在有害”的评估不够准确,作者使用了更具体的代理标准来捕捉模型行为的不同方面:- 标注员评估输出是否在特定场景下不适宜,如对客户助手不合适、贬低特定群体、或包含性别或暴力内容。
- 另外,作者使用了几个数据集来评估模型的偏见和有害性,如RealToxicityPrompts(Gehman等,2020)和CrowS-Pairs(Nangia等,2020)。
参考资料
- InstructGPT: Training language models to follow instructions with human feedback
- InstructGPT 论文精读【论文精读·48】
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付