1. Transformer前世今生
1. 预训练与迁移学习
1. 预训练是什么?
- 预训练:指在大数据集上先训练好一个模型(如模型A),然后将其参数迁移到一个相关的小数据集的新任务(如任务B)。
- 常见做法是在新任务上:
- 参数冻结(Freeze): 把预训练模型A的前几层参数保持不变,只训练后面的高层参数。(适合新任务和原任务差别不大的情况。)
- 微调(Fine-tuning): 让预训练模型A的全部或部分参数都参与新任务的训练。(适合新任务与原任务有差异时,能让模型适应新特征分布。)
- 适用于视觉(CNN)、NLP(BERT、GPT等)等各类任务
- 典型流程:加载预训练模型 → 替换最后一层输出 → 冻结部分参数/全部微调 → 用新任务数据继续训练。
2. 详细例子
- 当我们没有大规模标注数据(大数据集)时,直接训练深度模型通常效果很差。比如,只有100张猫狗图片,直接训练深度CNN容易过拟合,精度很低。
- 但如果有一个在大数据集(如10万张猪、牛图片)上训练好的模型A,这个模型已经学会了很多通用特征(比如边缘、纹理等)。
- 研究发现,神经网络浅层(前几层)学到的特征通常是通用的(图片:横竖撇那),适合迁移到新任务。

-
所以,对于任务B(比如猫狗分类,仅有100张图片),我们可以直接用模型A的浅层参数(前几层),把这些参数迁移过来,甚至可以复用A的全部结构和参数。
-
这样,任务B不需要从零开始训练深层网络,也能有较好表现。
-
总结:预训练让我们用大数据训练的"经验"加速小数据集的新任务,有效提升模型表现和训练效率。
3. 总结
- 预训练和迁移学习大大降低了小样本任务的训练难度和计算成本。
- 典型流程:先在大数据集上训练好基础模型 → 在小数据集上迁移、微调模型 → 提高新任务表现。
- 两种主要策略:
- 冻结参数:底层参数保持不变,只训练顶层或分类头。
- 微调参数:全部或部分参数都在新任务上继续训练。
- 这种方法已成为计算机视觉、NLP等领域的标配,提高了模型的泛化能力和开发效率。
2. 统计语言模型
1. 语言模型
- 语言模型的任务,是利用概率的方法判断一句话的合理性或预测下一个词。
- 比较:"我喜欢吃苹果" 和 "我喜欢吃桌子" 哪一句概率更大。
- 预测:给定 "我喜欢吃___",模型根据上下文预测最有可能的词(比如"苹果"、"香蕉")。
2. 统计语言模型
-
统计语言模型:用统计的方法解决上面2个问题(判断、预测)。
- 分词:"我喜欢吃苹果" → "我 / 喜欢 / 吃 / 苹果"
- 序列:文本是一个有顺序的序列,建模时需要考虑词序。
-
利用链式法则(Chain Rule)分解句子的联合概率,每个词的出现概率与前面词相关,相乘得整个句子的概率:
- 用来预测下一个词时,比如:"我喜欢吃___",对于词表
中每个候选词 ,都可以计算 选概率最大的就是最合理的预测。
- 用来预测下一个词时,比如:"我喜欢吃___",对于词表
-
痛点 1:当序列很长时,模型需要处理超长上下文,导致参数多、稀疏,训练难,这时就需要 n-gram 统计模型来简化。
3. n-gram 统计语言模型
-
解决 1:文本很长时,用马尔科夫假设简化,只考虑前面固定数量的词(N-1个),这就是 n-gram。
- UniGram(一元):n=1,仅考虑单个词,忽略上下文。
- BiGram(二元):n=2,当前词只依赖前一个词。
- TriGram(三元):n=3,当前词依赖前两个词。
-
一般
越大,模型考虑的上下文越多,但数据稀疏和复杂度也提升。 -
例子: 统计 "cat sits" 在语料库里出现的频次。 若 "cat" 出现10次,其中4次后面是 "sits":
4. 平滑策略
- 痛点 2:数据稀疏时,某些 n-gram 组合可能在训练语料中一次都没出现,概率为 0,影响模型泛化。
- 解决 2:加一平滑(Add-one/Laplace Smoothing) 给所有组合都"虚拟加一",这样,哪怕没见过的组合也不会出现概率为0的情况:
:前后词组合的出现次数 :前一个词出现总次数 :词表大小
5. 总结
- 语言模型,用概率衡量一句话的合理性,或预测下一个词的可能性。
- 统计语言模型,通过条件概率和链式法则对自然语言序列建模。
- n-gram 简化建模难度,仅考虑有限长度的上下文,常见于早期NLP应用。
- 平滑策略,解决未出现组合概率为0的问题,提高模型鲁棒性。
- 现代神经网络(如 RNN、Transformer)已逐步替代传统统计模型,但基本思想仍然相通。
3. 神经网络语言模型(NNLM)与 Embedding
神经网络 + 语言模型:用神经网络方法解决"预测下一个词"和"语言理解/生成"相关任务。
1. 独热编码 one-hot
-
痛点&解决:计算机不认识单词(不能理解处理文本),利用 One-hot 让计算机认识单词,将每个单词转为数字化向量
-
One-hot 编码:就是用全0、只有一位为1的向量来唯一标识每个词。
-
举例:假设词表
只有8个单词,one-hot 编码是 的稀疏矩阵。

- 缺点(痛点3):
- 稀疏性高:向量绝大多数为0,存储和计算都低效。
- 不表达语义:任何两个单词的 one-hot 距离都一样,无法体现词之间的语义联系。(e.g. cat 和 dog 之间完全看不出"它俩都属于动物")。
- 无法衡量相似性:模型分不清 "good" 和 "great" 有多接近,"good" 和 "banana"同样远。
- 维度爆炸:词表越大,向量越长,计算和存储成本随之上升。
2. NNLM 架构
- 基本结构:一个简单的多层感知机(MLP)。
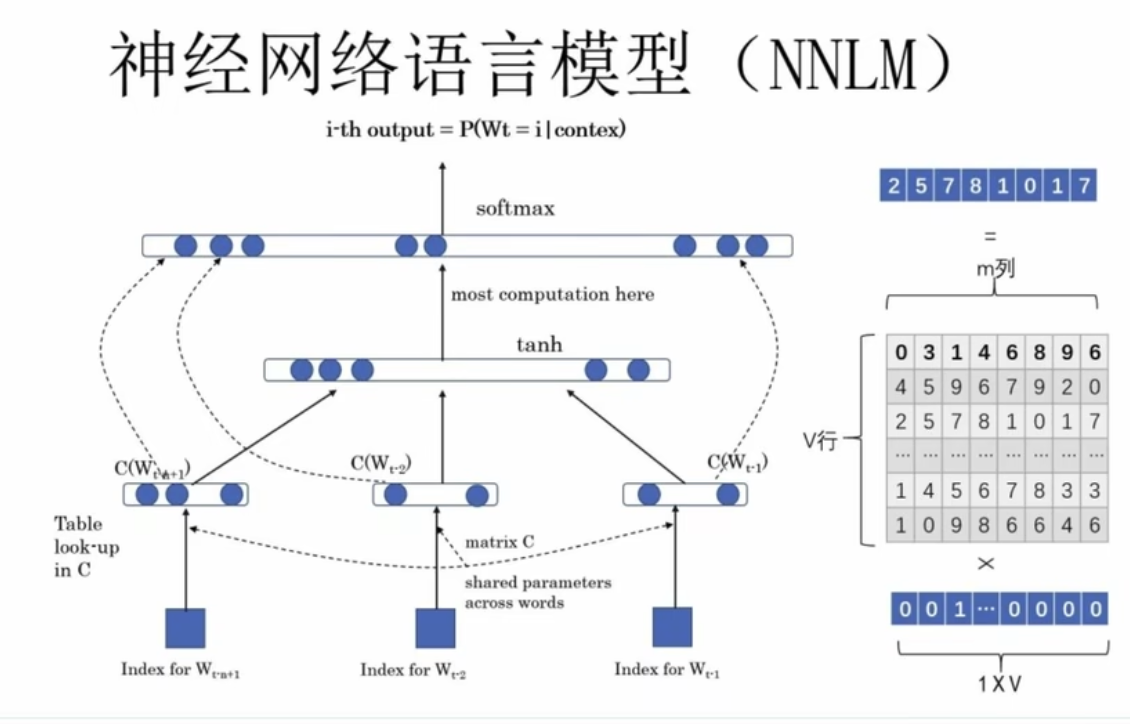
- 计算流程:
-
输入上下文4个词,
w1, w2, w3, w4是词的one-hot向量 -
用词向量矩阵
,将 one-hot 变成词向量 : c1, c2, c3, c4 -
拼成句子向量
-
非线性激活
tanh(),线性变换U() -
最终通过 softmax 输出概率分布,预测下一个词。
1
2
3
4w1 * Q = c1,
w2 * Q = c2,
w3 * Q = c3,
w4 * Q = c4
-
3. 词向量(Embedding,Q矩阵)
- 词向量矩阵 Q(Embedding Matrix):是所有词的嵌入矩阵,训练中自动学习得到。
- one-hot × Q = 某个词的词向量(
),例:
-
优点(解决3):
- 可以灵活设置维度,极大程度降维、节省空间
- 可以用余弦相似度计算词与词的相似度,表达语义相关性
- Embedding 可迁移用于各种NLP任务,提升模型表现。
-
语义相似:如果用PCA把词向量降到二维再画出来,语义接近的词会聚在一起。
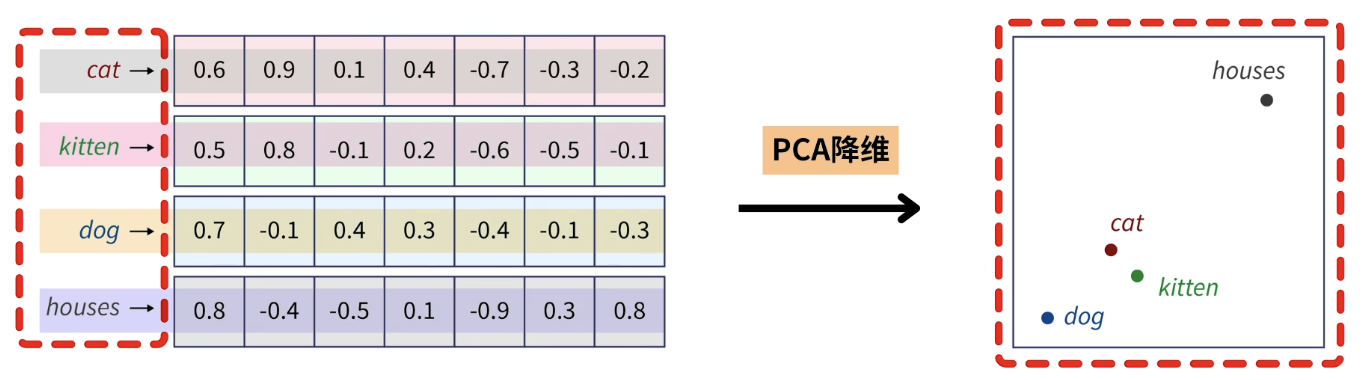
-
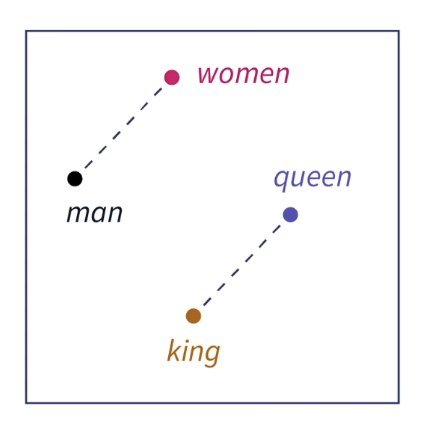
语义关联:通过词向量的数学关系,可以发现
king - man + woman ≈ queen,这揭示了词语之间的语义结构。
-
嵌入矩阵(Embedding Matrix): 通过词嵌入算法(如Word2Vec、FastText、GloVe)训练得到一个通用的嵌入矩阵(可用作Embedding层)
- 形状:【词数 × 向量维度】
4. 总结
- NNLM 用神经网络预测下一个词,更好建模上下文关系。
- Embedding 彻底解决了 one-hot 的稀疏性与语义表达缺陷。
- 词向量(Q矩阵)让词语的表示更智能、更有实际语义,可广泛应用于分类、生成、理解等NLP任务。
参考资料
4. Word2Vec
One-hot 编码的局限(痛点4):
- 高维稀疏性:词表很大时,one-hot 向量非常长,大多数元素都是0,存储和计算效率低。
- 缺乏语义相似性 :One-hot 无法反映词与词的语义关系。例如,"猫"和"狗"都是动物,但它们的 one-hot 向量正交(点积为0),模型无法感知它们的相似性。
1. Word2Vec(为了得到矩阵Q)
-
Word2Vec 是一种无监督学习方法,利用大量文本中的上下文关系自动训练词向量。
-
目标(解决4):把每个词映射为低维稠密实向量,使 语义相似的词在向量空间中更接近。
-
训练思想:让"意思相近的词,向量距离也近"。
-
两种常用模型结构:
- Skip-Gram:给定中心词,预测其上下文词。例如输入"apple",预测"eat"、"red"等周围词。
- CBOW(Continuous Bag-of-Words):给定上下文词,预测中心词。例如输入"cat"、"dog",预测"animal"。
-
缺点(痛点5):
- 无法区分一词多义("apple" 是苹果,还是)。
- 只依赖局部上下文窗口,忽略全局统计信息和长距离依赖。
2. NNLM V.S. Word2Vec
- NNLM(神经网络语言模型) 侧重于用神经网络预测下一个词,通常采用双层感知机结构:
- Word2Vec 专注于"学好词向量 Q 矩阵",而不是直接预测下一个词。
- CBOW:上下文词 → 预测中心词
- Skip-Gram:中心词 → 预测上下文词
3. 预训练词向量的使用
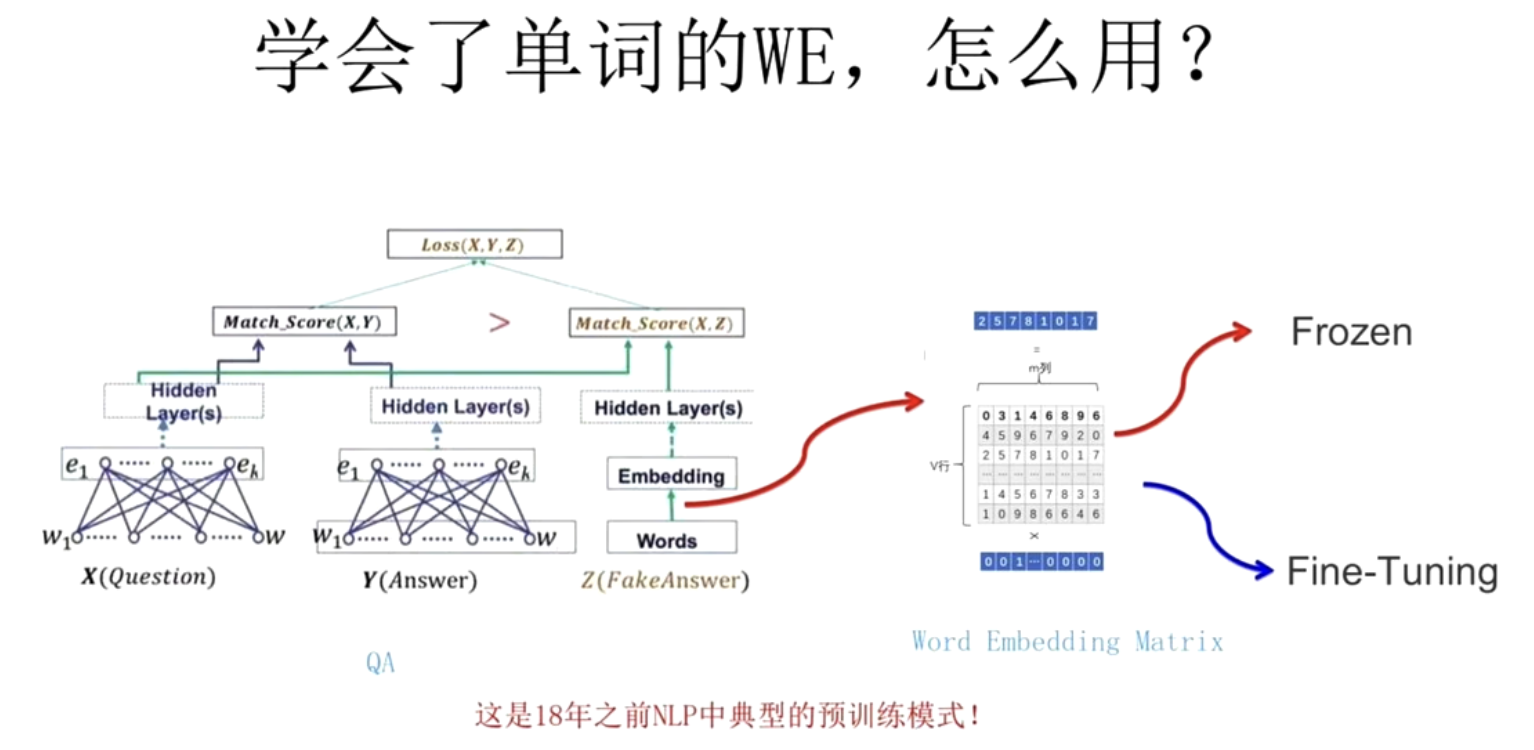
- Word2Vec 可以作为预训练模型,用于下游NLP任务的特征输入。
- 常见用法:
- 冻结:加载预训练好的 Q 矩阵(词向量表),参数保持不变,直接作为输入特征使用。(i.e. 不改变Q矩阵)
- 微调:在新任务中继续训练 Q 矩阵,让词向量进一步适应新场景。(i.e. 随着任务改变Q矩阵)
4. 总结
- Word2Vec 通过无监督学习自动获得词向量Q矩阵,使语义相近的词在空间中靠近。
- 两种结构:CBOW(上下文预测中心词)、Skip-Gram(中心词预测上下文)。
- 本质上就是一个预训练词向量查找表(Q矩阵),可直接用于后续模型(冻结/微调)。
- 虽然Word2Vec提升了文本建模能力,但在表达上下文动态含义和一词多义等问题上有局限,现代NLP任务已逐步采用BERT、GPT等更复杂的上下文相关预训练模型。
5. ELMo模型(双向LSTM)
NNLM模型 V.S. Word2Vec模型:
- NNLM模型:以神经网络(MLP)预测下一个词,副产品是词向量(Embedding)。
- Word2vec模型:专门学习词向量(Q矩阵),两种架构:
1. CBOW(上下文词 → 预测中心词)
2. Skip-Gram(中心词 → 预测上下文词) - 痛点5:静态 embedding 不能根据上下文变化,无法表达复杂语义。
- "apple":是水果,还是 公司
- 每个词只有一个向量,无法区分一词多义(如 word2vec、GloVe)
- 解决5:ELMo 通过引入上下文动态生成词向量,解决静态词向量不能区分多义词的问题。
1. ELMo模型架构
- ELMo(Embeddings from Language Models):专注于动态上下文词向量的预训练模型。
- 解决5:利用多层双向LSTM(biLSTM),通过左右两个方向编码句子,动态生成每个词的表示。
- 输入一句话,前向LSTM从左到右,后向LSTM从右到左,双向捕捉上下文。
- 每个词的最终表示,是将每一层输出(包括底层token embedding和各层LSTM隐藏状态)做加权和,权重由模型自动学习。
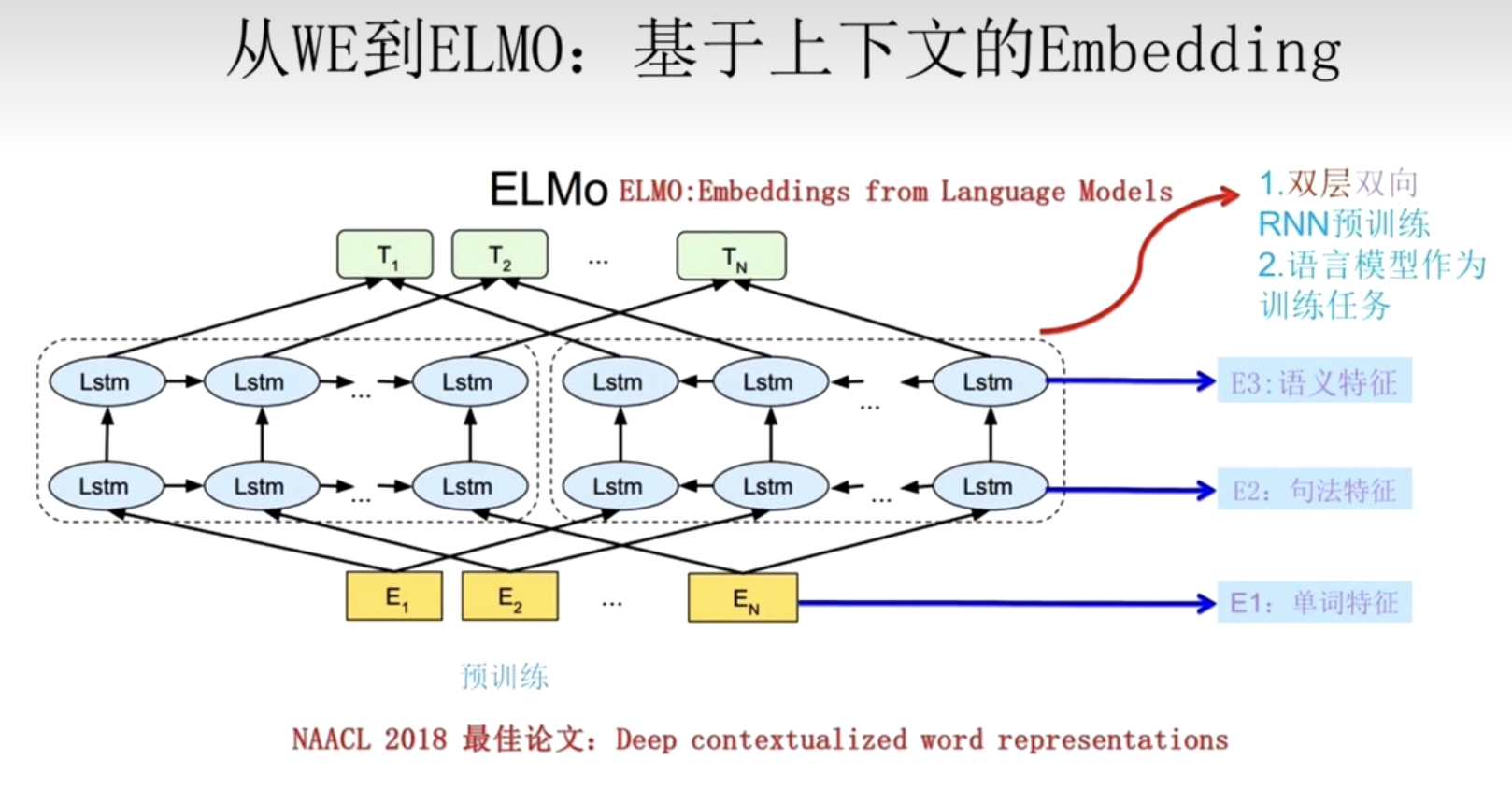
2. 词向量生成方式
- 底层:词的 Embedding,,通常由
字符级CNN或词表查表获得。 - 上层:LSTM每层的隐藏状态。
- 对于句子中的第
个词 ,ELMo 向量 计算方式: = 总层数 = 第 个词在第 层的输出 = 各层加权系数(可学习,softmax归一化) = 全局缩放因子(可学习)
3. 总结
- ELMo 用多层双向LSTM生成动态词向量,能根据上下文区分多义词。
- 它融合了不同层的语法与语义信息,显著优于静态词向量(如Word2Vec)。
- ELMo词向量可直接作为各种NLP任务的输入特征,极大提升了模型效果,是现代预训练模型的重要基础。
6. Attention Mechanism 注意力机制
- 注意力机制:让模型自动关注输入中的 重要部分,动态分配权重,不再平均处理所有信息。
- 输入:Q(Query)、K(Key)、V(Value)
- 常用于 NLP(文本)、CV(图片)等场景。

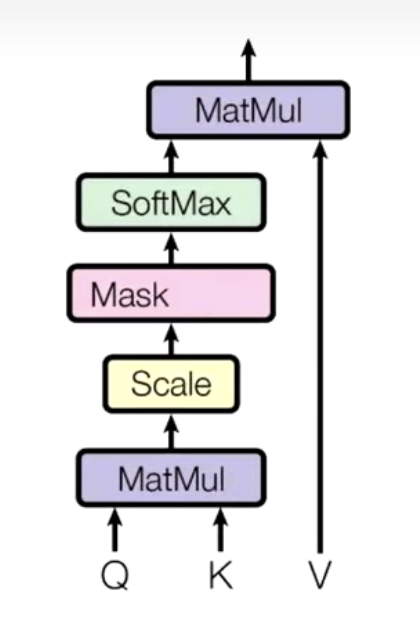
1. 注意力流程(以点积注意力)
- 注意力公式:
形状: ,每个Query和所有Key配对打分
-
输入定义
(Query):查询向量 (Key):关键内容的描述 (Value):与 Key 对应的信息
-
计算相关性分数 + 缩放
- 对每个 Query 和所有 Key 计算相似度
(点积,并除以 ):
- 对每个 Query 和所有 Key 计算相似度
-
归一化权重
- 对所有打分做 softmax,转为概率型权重:
- 对所有打分做 softmax,转为概率型权重:
-
加权求和输出
- 用权重对 Value 加权求和,得到注意力输出:
- 输出大小和 Value 一样,但已经融合了"最重要的信息"。
- 用权重对 Value 加权求和,得到注意力输出:
2. 相关技术
- 缩放因子:通常除以
防止点积过大,避免 softmax 梯度消失。 - Self-Attention:Q、K、V 都来自同一输入(如 Transformer),能表达序列内部的依赖关系。
- 多头注意力(Multi-Head Attention):多组独立的 Q、K、V 分别做 attention 后拼接,提升模型表达力。
4. 总结
- 注意力机制:通过Query、Key、Value结构,让模型自动判断"哪些输入信息更重要",为每个输入分配不同权重。
- 计算时,Query和所有Key做相似度打分,softmax归一化后对Value加权平均,输出综合了最有用信息的结果。
- Key 和 Value 可以视为同一个东西(即
),只是起到"打分和加权"的作用。 - 这种机制能动态聚合上下文,表达远距离依赖,是NLP(BERT、GPT等)和CV现代架构的核心模块,极大提升了模型的表达和理解能力。
7. Self-Attention(自注意力)
- Self-Attention 机制可以让模型自动计算输入序列中每个元素与其他所有元素之间的相关性(即注意力分数),然后根据这些相关性动态调整每个位置的表示。这意味着每个元素在更新自身表示时,都能综合全局上下文的信息,而不是只依赖于固定范围的邻居。
- 这种机制能够捕捉序列中任意位置之间的依赖关系,让每个元素"关注"整个序列,因此非常适合建模全局依赖和长距离联系。
- Self-Attention 是 Transformer 等现代 NLP 模型的核心组件,被广泛应用于文本理解、生成等任务,极大提升了模型的表达能力和效果。
- 通俗说,就是每个词都可以"环顾四周",随时向全句里任何词"借用信息",让表达更聪明。
1. 输入定义
- 给定输入序列
,每个 - 对每个
,通过(可学习)参数 线性变换 得到对应的 Query、Key、Value 向量: 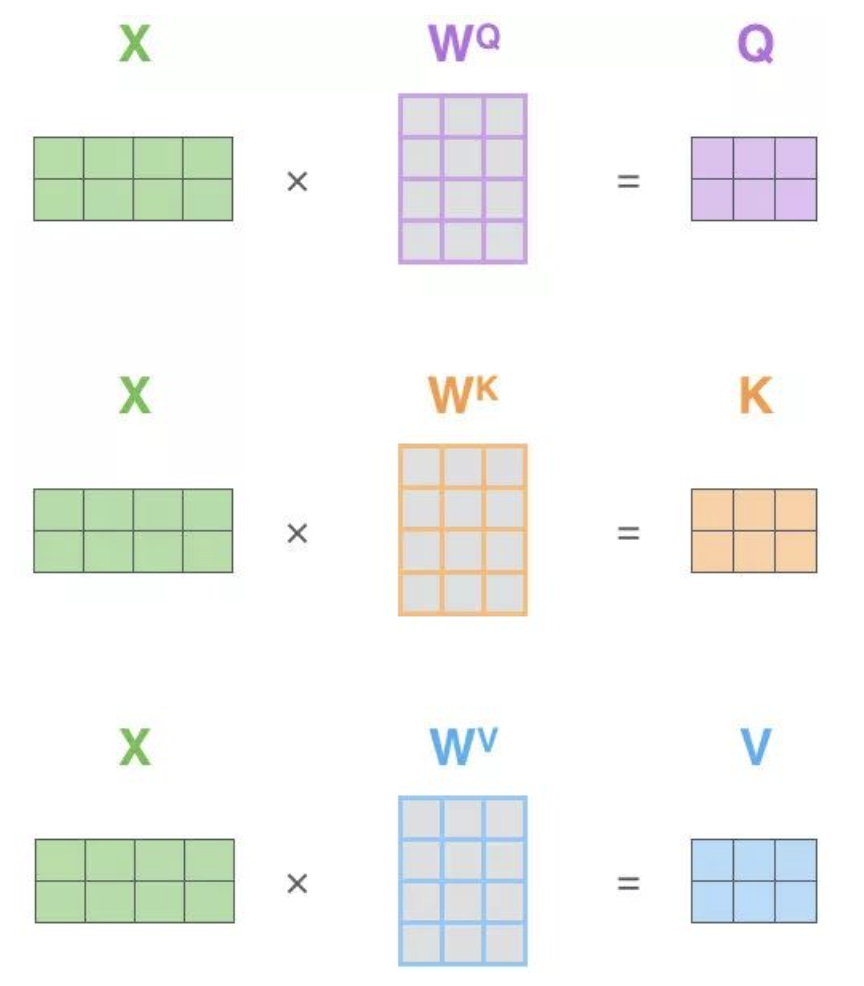
2. 计算过程
- 相似度打分
- 对于每个
,分别和所有 做点积相似度,得到打分 : 是Key的维度,分母用来缩放防止梯度爆炸。
- 对于每个
- 归一化权重
- 对每个
,用 softmax 把所有分数 归一化为注意力权重 :
- 对每个
- 加权求和输出
- 用权重加权所有
得到输出 : 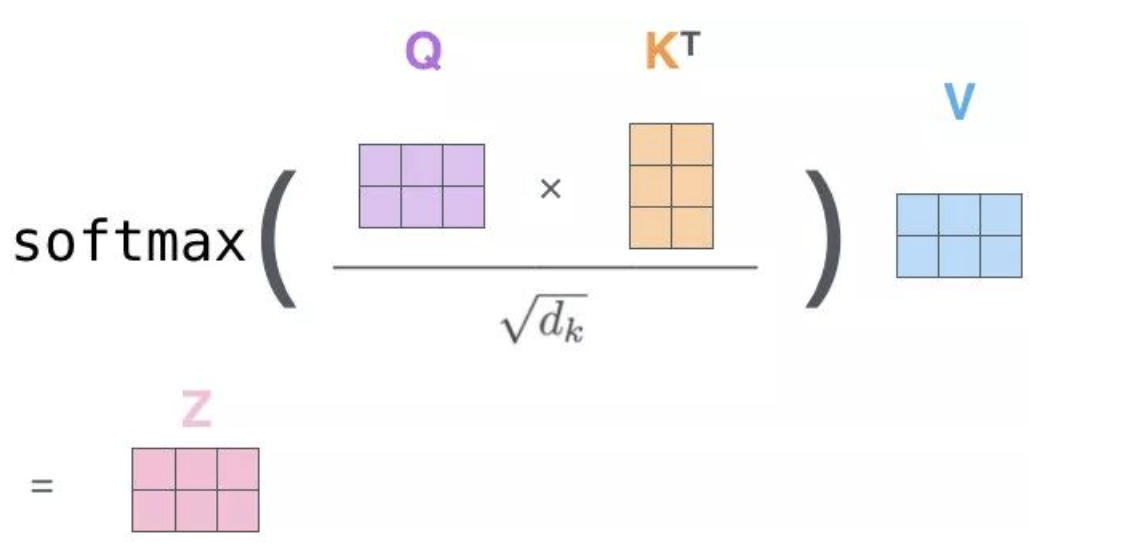
- 这样
就融合了序列中所有位置的信息,且权重大小反映了相关性。
- 用权重加权所有
- 最后形成一个注意力机制的图,包含序列中相关性的矩阵
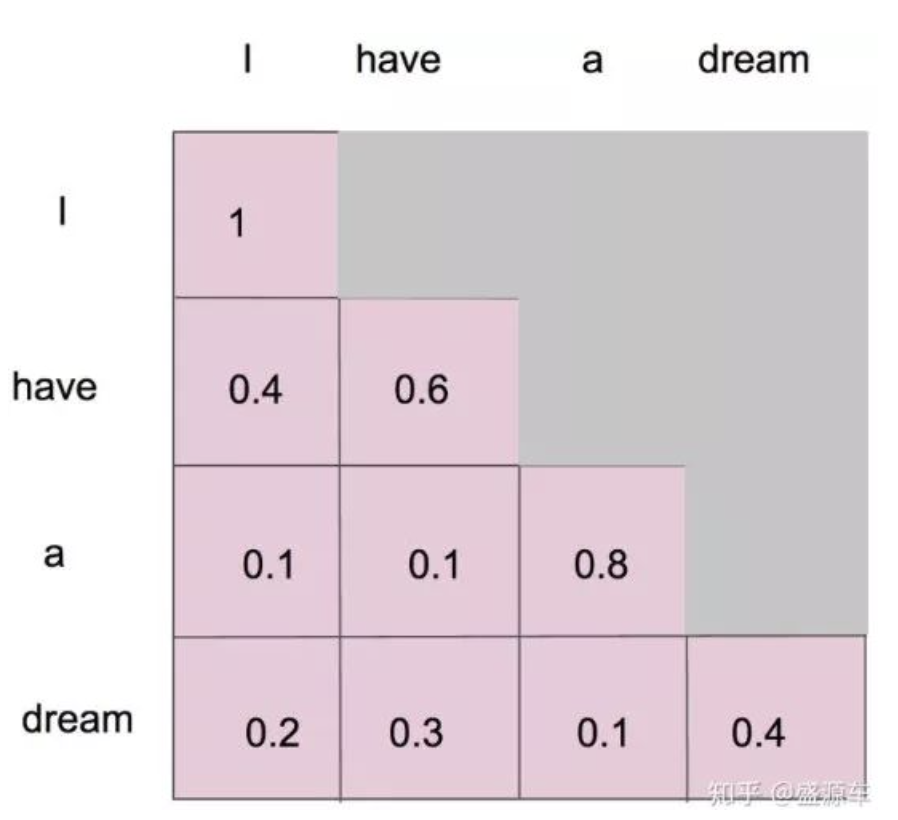
3. 举例说明
假设输入序列为 "machine learning",经过 embedding 得到
- 对每个
,通过线性变换 ,计算出对应的 (即 对应 "machine", 对应 "learning")。 - 现在我们以"machine"为例,先用
分别与 和 做内积,计算出 (表示"machine"与自己的相关性), (表示"machine"与"learning"的相关性)。 - 将这两个分数都除以
(假设 ),得到 14 和 12。 - 对分数 14 和 12 进行 softmax 归一化,得到注意力权重
, 。这说明"machine"在自我关注时权重更大,但也会分一些注意力给"learning"。 - 用这两个权重对 value 向量进行加权求和,得到"machine"的新的表示
。 - 类似地,对"learning"也可以得到自己的新表示
,方法一致。 - 这样,原始的
和 就分别变成了融合上下文信息的 和 , 包含了 和其他所有词的相关信息, 同理。

4. 总结
- Self-Attention 机制通过让每个元素根据与序列中所有元素的相关性自适应地调整自己的表示,实现了信息的全局聚合。
- 它不仅能捕捉长距离依赖,还能让模型动态关注最有用的上下文信息,是现代 NLP 和 Transformer 架构不可或缺的核心组件。
- 通过Self-attention,每个词的表示都变得更加丰富和语义化,大大提升了模型理解和生成复杂序列的能力。
- Attention 和 Self-Attention 区别:
- Attention:有一个查询Q,去关注(聚合)一堆别的内容K/V,K 和 V 通常代表同一个对象,可以认为
。 - Self-Attention:输入序列里的每个元素都同时作为 Q、K、V,也就是说,Q、K、V 都来源于同一个输入,可以认为
。这样每个元素都能和所有同伴(包括自己)计算相关性,实现信息的全局交互。 - 简单说:Attention 是"我看别人",Self-Attention 是"大家互相看彼此"。
- Attention:有一个查询Q,去关注(聚合)一堆别的内容K/V,K 和 V 通常代表同一个对象,可以认为
8. Multi-Head Self-Attention 多头自注意力机制
1. Self-Attention与RNN/GRU/LSTM对比与原理
-
RNN/GRU/LSTM 缺点(痛点):
- 长距离依赖弱:信息只能沿序列逐步传递,捕捉远距离关系很难。
- 效率低:计算必须串行,难以并行,训练和推理都慢。
-
Self-Attention优点(解决):
- 长距离依赖强:每个位置直接关注全序列,长依赖无瓶颈。
- 支持并行:所有位置可同步计算,大幅提升效率。
- 全局信息:每个词的表示都融合了全局句法与语义特征。
2. Multi-Head Self-Attention
-
Self-Attention:
- Self-Attention是Attention的一种特例——自己"问自己"相关性。
- 给定输入
(词向量序列),经过自注意力层,每个 变为 , 吸收了序列中其它所有词的信息。 - 这样输出的
(词向量)融合了全局的句法和语义信息,比原始 拥有更丰富的上下文特征。
-
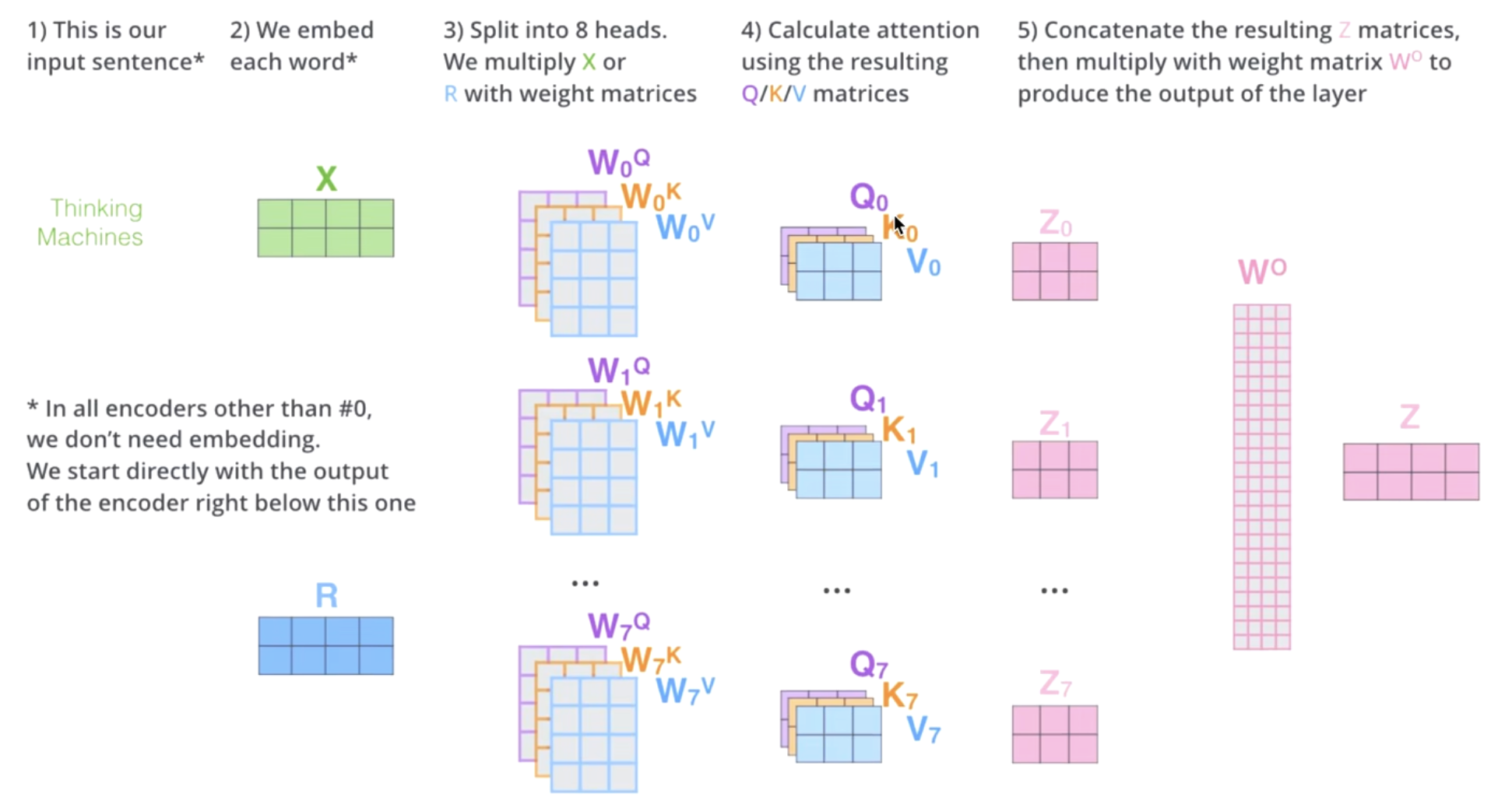
核心思想:把输入向量
映射到多个子空间(head),每个head独立计算Q/K/V和自注意力,得到不同的得到 ,拼接所有head的输出,再用输出权重 做线性变换得到最终 。 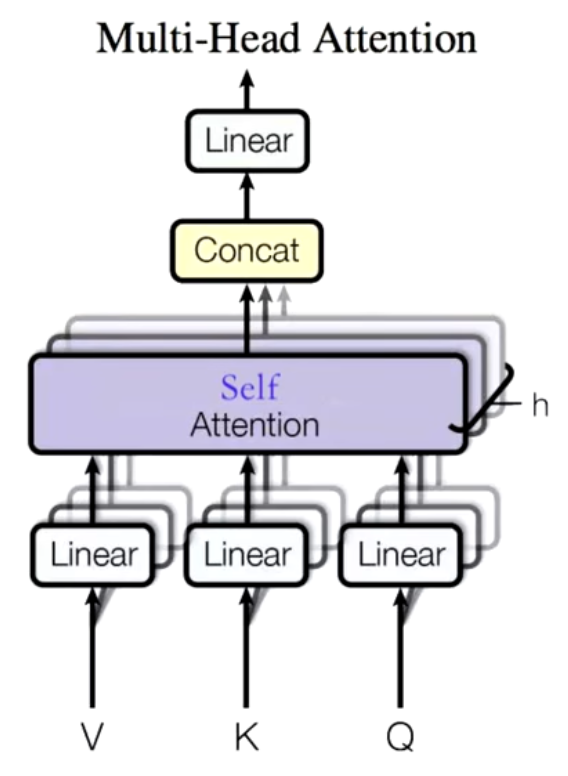
-
流程(如图片):
- 输入序列
,先做embedding - 分成
个head(假设如图 8个head),每头都有独立的Q/K/V权重矩阵 - 每个head独立计算attention,得到
- 将
拼接(concatenate)成一个长向量 - 拼接结果通过一个输出权重矩阵
做线性变换,输出最终
- 输入序列
-
公式:
-
本质:
- 多头机制让模型能从多个视角(不同的参数空间)学习句子结构和语义,每个head负责不同类型的特征,最后整合,表达力更强。
3. 总结
- 优点:
- BERT、GPT、Transformer等NLP大模型的标配结构。
- 并行高效,能捕捉复杂依赖关系
- 不同head能捕捉到不同的依赖关系或语义特征,拼接后提升整体表达力。
- 简单说,多头自注意力 就是把输入"拆分多视角"各自理解,再融合成最优表达,让每个词的表示既有局部又有全局,是现代NLP成功的关键。
9. Transformer 整体架构 (未整理)
1. 架构 与 必备技术点
- 整体架构
- Encoder-Decoder结构(分别N层堆叠)
- Seq2Seq任务中如何输入输出
- Embedding(词嵌入/向量化)
- 文本输入先通过Embedding层(将token/单词转为稠密向量)
- (Embedding + 位置编码)一起作为Transformer的实际输入
- 位置编码(Positional Encoding)
- 解决 Self-Attention 无序问题
- 常见实现(正弦/余弦编码)
- Self-Attention(自注意力机制)
- Q、K、V 的含义和计算
- 计算 Attention Score 和 softmax加权
- 能全局建模依赖关系
- Multi-Head Attention(多头注意力)
- 多头的作用、原理、拼接和线性变换
- 捕捉不同子空间的特征
- Masked Self-Attention
- 为什么需要 Mask
- 训练和推理时信息一致性
- Encoder-Decoder Attention
- Decoder如何通过 Q/K/V 与 Encoder 交互
- 为什么 K/V 来自 Encoder,Q来自 Decoder
- Feed Forward网络
- 子层结构(两层MLP+ReLU)
- 子层如何加深非线性表达能力
- 残差连接(Residual)和层归一化(LayerNorm)
- 作用:缓解梯度消失/爆炸,提升训练稳定性
- 并行性和效率优势
- 为什么比RNN/LSTM更高效
- 可以同时处理所有位置
- 实际应用
- 机器翻译、文本生成
- 变体如 Encoder-only(BERT)、Decoder-only(GPT)、Encoder-Decoder(T5)
2. 宏观: 工作流程
- Transformer 属于 Seq2Seq 架构:由 Encoder(编码器) 和 Decoder(解码器) 两部分组成,广泛用于机器翻译等任务。
- 输入例子:中文 "我是一个学生"
- 输出例子:英文 "I am a student"
- N x 表示有
层编码器和 层解码器(通常 )。 - Transformer 的2种工作模式:
-
训练模式,teacher forcing模式:
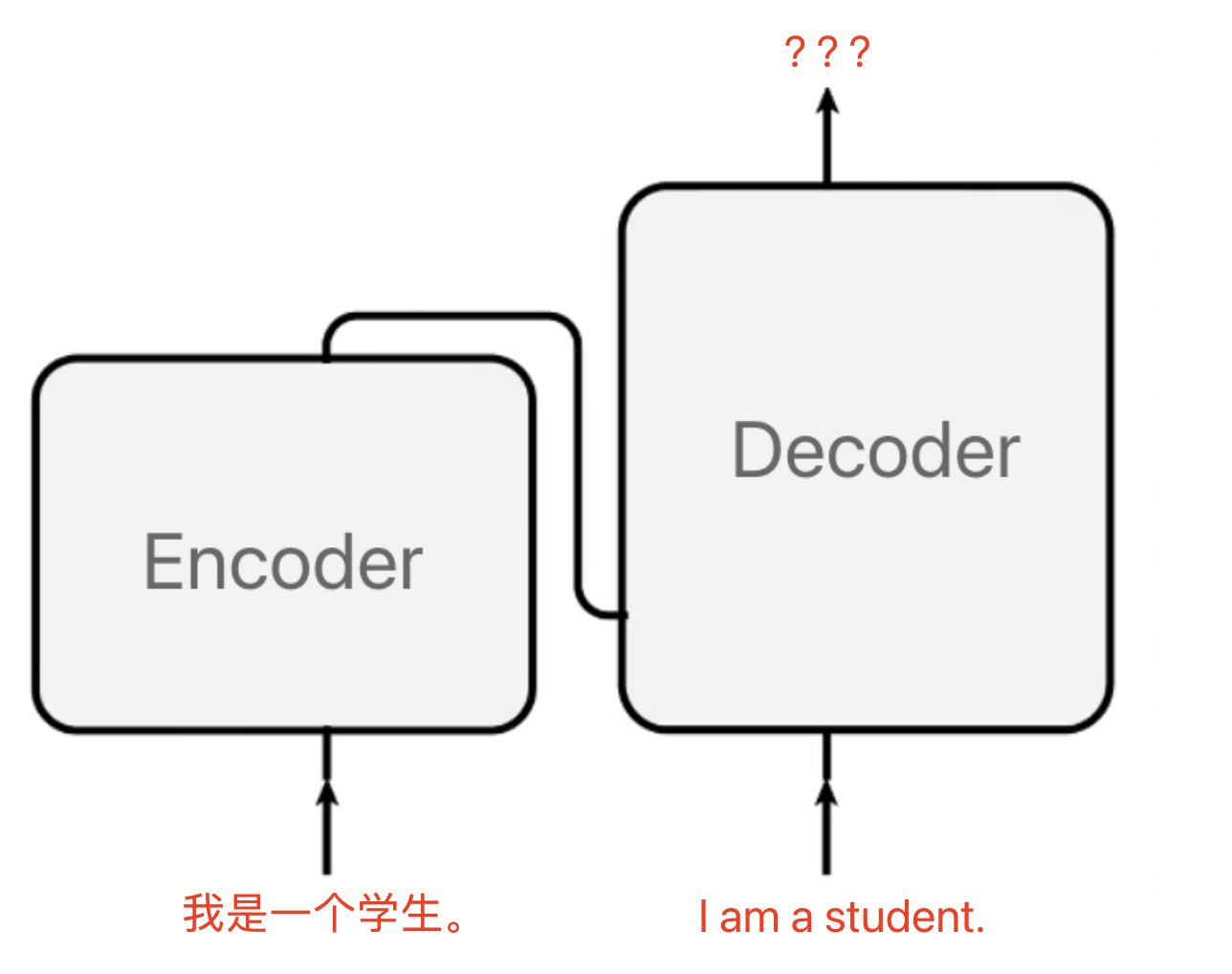
- 在机器翻译的时候,中文和英文作为输入数据。
- 在每一轮训练和迭代中,计算出模型output:hat{Y} =(你,多,大,了,?)和输入:Y=(我,是,一,个,学,生。)的损失
- 继续计算Loss关于Transformer中参数theta的梯度,使用梯度下降算法更新这些theta
- 前向推理,损失计算,梯度下降就完成了一次迭代
- 自回归的前向推理是循环过程
- 而教师强的前向推理是根据不同长度的真实标签分布进行推理
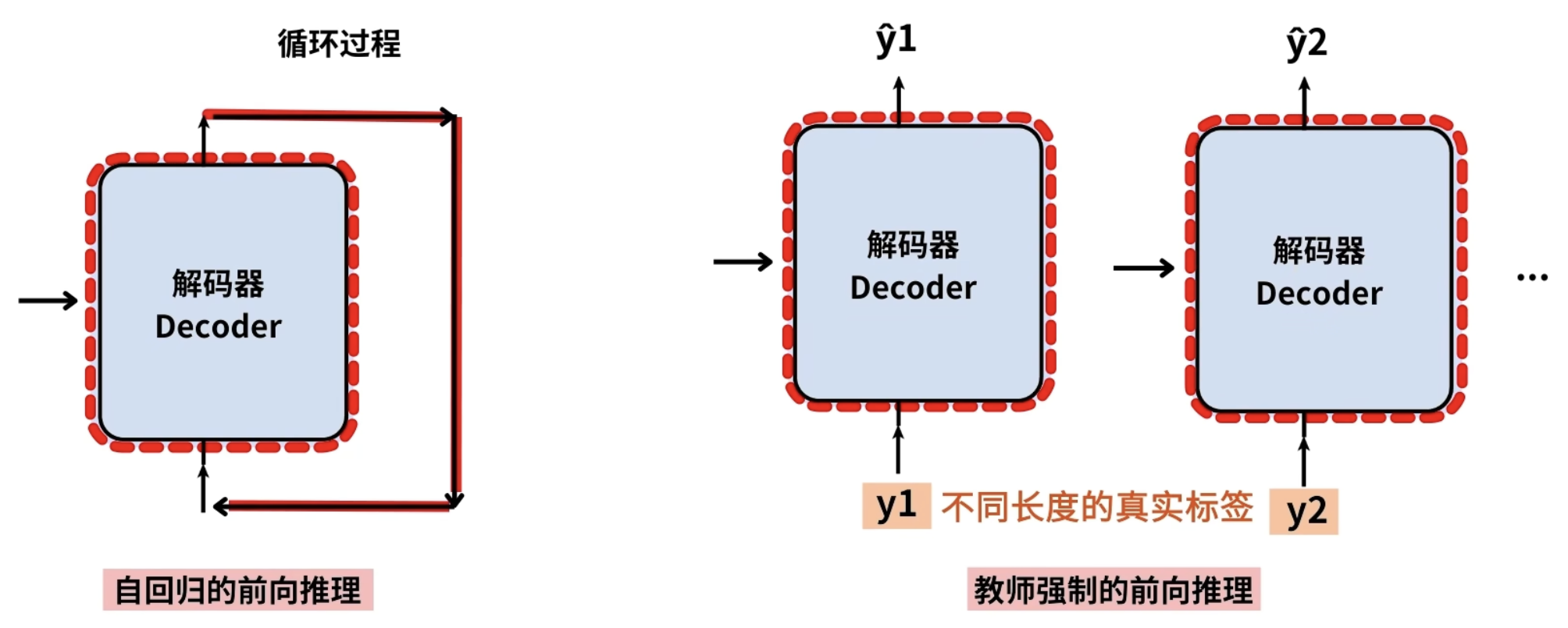
- 底层逻辑是一样的
-
推理模式,自回归,autoregressive模式:
- 当完成Transformer模型的训练后,需要模型对未知的数据进行推理计算
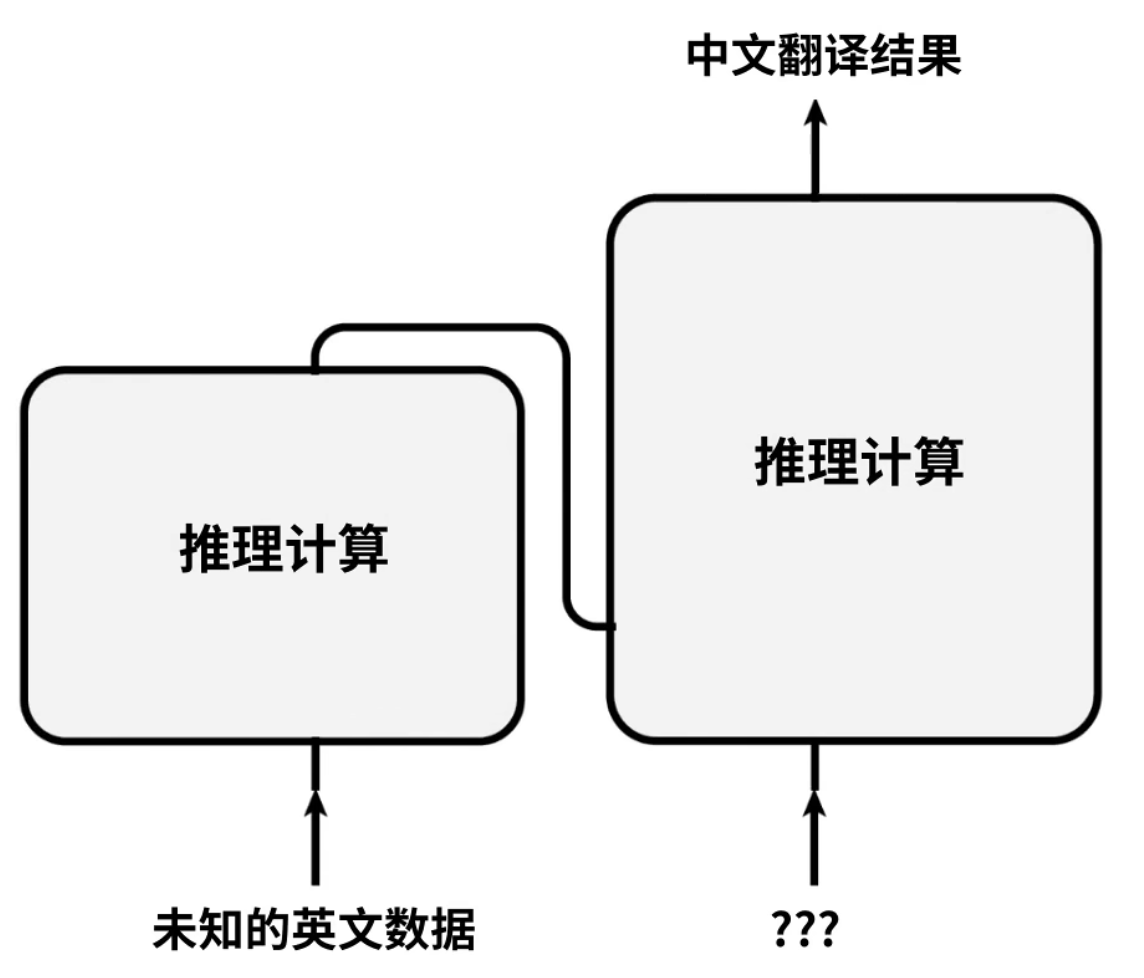
- 第一次推理计算:Encoder会得到英文,Decoder是未知的位置,会有一个
<start>符号提示开始翻译工作。 - 第二次推理计算:Encoder会直接使用计算结果,Decoder会得到
<start>我的输入,output会拿到一个是 - 第三次:Encoder会直接使用计算结果,Decoder会得到
<start>我是的输入,output会拿到一 - 。。。
- 最后一次:Decoder拿到
我,是,一,个,学,生,。,output会有一个结束符号<end>表示推理计算完成
- 当完成Transformer模型的训练后,需要模型对未知的数据进行推理计算
-
3. 微观: 架构设计细节
1. 文本序列
- 文本序列:"我是一个学生。" 通过分词器tokenizer 得到 【我,是,一,个,学,生,。】然后通过预设的词汇表,映射转换为对应的数字索引【123,34,2, 13,6, 231, 3】
- 中文词汇表V:【123,34,2, 13,6, 231, 3】
- 英文词汇表V:【2,3,4,11,35】
- 当中英文索引进入,会被Embedding层处理,单词的数字索引会被转换为词向量的序列
- 然后词向量进行位置编码,加上位置信息,数据尺寸为:batch size \times Sequence Length \times Embedding dimension(B x Q x D)
- Encoder英文尺寸【B,Q1,D】
- Decoder中文尺寸【B,Q2,D】
- 所以发现,批量大小通常是一样的B,嵌入维度也是一样的D,只有句子长度不一样
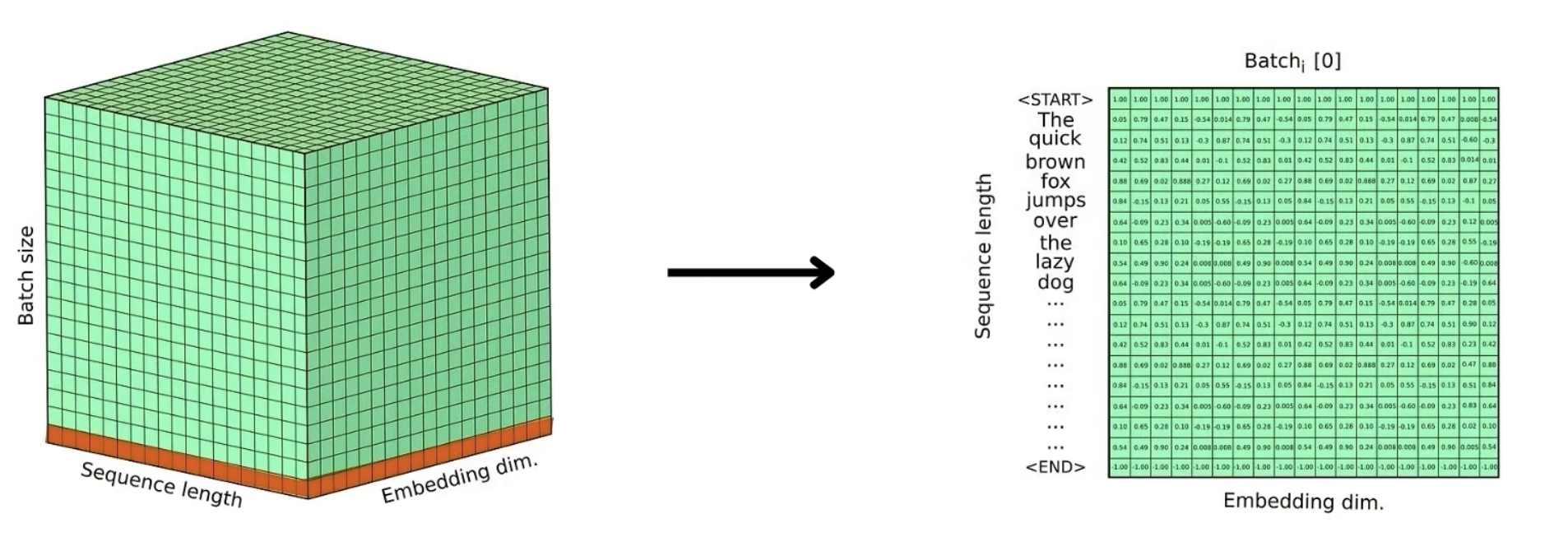
- 然后进入Encoder/Decoder架构内容
2. 编码器(Encoder)
每层包含两个子层:
- Multi-Head Self-Attention:可以看做是负责的线性变化
- self-attention:
- 让每个词对输入序列中所有词做自注意力,获得融合全局信息的新词向量(包括位置、语法、语义特征)。
- 输入词向量 = 词向量编码 + 位置编码 (参考文章:Positional Encoding)
- self-attention:
- Feed Forward(前馈网络)
- 多层感知机(含ReLU),提升非线性表达能力
- 每个子层均有残差连接和层归一化(LayerNorm),缓解梯度消失/爆炸、加速收敛。
- LayerNorm:稳定神经网络的训练,避免训练中产生梯度消失或梯度爆炸
- 层归一化计算公式:
- 使得经过层归一化的均值为0,方差为1,具有相似的尺度,使得神经网络可以更快的收敛训练过程更加稳定。
如果 gamma是缩放参数,beta是平移参数,默认值为(gamma=1,beta=0),层归一化不进行参数学习,就会直接使用层归一化计算公式
- 层归一化计算公式:
- 为什么Transformer使用layernorm?
- 无论一组序列数据的批量B是多少,在一组数据中,不同的序列有着不同的长度Q,不会影响层归一化计算
- Batch Size:B;Sequence length:Q;features dimension: D.
- LayerNorm:稳定神经网络的训练,避免训练中产生梯度消失或梯度爆炸
3. 解码器(Decoder)
- 比编码器多一个Encoder-Decoder Attention层(源语-目标语交互)。
- 包含三个子层:
- Masked Self-Attention
- 生成目标序列时,当前词只能看到前面已生成的词(训练/推理时用mask遮住未来信息)。
- 避免训练-推理信息不对齐(Exposure Bias),保证测试时一步步自回归生成。
- Encoder-Decoder Attention
- 查询(Q)来自已生成的目标词,键和值(K,V)来自编码器的源序列输出。
- 让生成目标时能关注源序列中最相关的部分。
- Feed Forward,同编码器
- 同样包含残差连接和LayerNorm。
- Masked Self-Attention
4. 编码器-解码器交互
- 为什么Decoder用K、V来自Encoder?
- Decoder生成目标序列时,需要"查询"源句中哪些词与当前生成最相关。
- Q(查询)= 已生成目标词,K/V = 编码器源序列输出。
- 解决了传统Seq2Seq框架每步都用全局编码C,不能区分源句不同词对生成词的影响大小的问题。
4. 总结
- Self-Attention和Multi-Head Attention:大幅提升了建模长距离依赖、捕捉句法语义的能力,可并行处理所有位置,效率极高。
- 残差连接+LayerNorm:训练稳定、深度可扩展。
- 位置编码:补偿无序性,传递序列顺序信息。
- Transformer通过全注意力机制,实现了高效、并行、强大特征提取能力,已成为现代NLP和生成式AI的主流架构(如BERT、GPT、T5等)。
- Masked Self-Attention是生成模型正确生成目标序列的关键,Encoder-Decoder Attention让生成每个词都能动态关注源句最相关内容。
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付