2. Transformer(书)
- 大语言模型的核心目标是对自然语言的概率分布进行建模。
- Transformer架构自2017年提出后成为自然语言处理和机器翻译领域的主流模型架构。
1. Transformer 结构
1.1 Transformer 结构简介
- Transformer 架构:2017年由Google提出,用于机器翻译的神经网络模型。
- 基本目标:将源语言(Source Language)转换为目标语言(Target Language)。
- 主要思路:完全通过注意力机制完成序列对序列、目标语言序列全局依赖的建模,不依赖循环结构。
1.2 基本组成模块
-
编码器(Encoder) 与 解码器(Decoder)
- 左右结构,分别对应编码和解码。
- 每边包含多个Transformer Block(N层堆叠)。
- 每个 Block 输入为向量序列
,输出为 。
-
Token 表示:输入序列(词/子词)
,通过Transformer块,逐步编码为上下文相关的表示 ,再由 Decoder 解码为输出 。 -
主要任务:实现从输入
到输出 的 语义抽象与转换。
1.3. Transformer 关键机制
-
多头注意力层(Multi-Head Attention)
- 作用:并行运行多个独立注意力机制,从不同维度抽取输入序列信息。
- 优势:可直接建模任何两单词之间的依赖关系,突破传统循环结构的限制,尤其擅长长距离依赖建模。
-
位置感知前馈网络层(Position-wise Feed-Forward Network)
- 作用:对输入文本序列的每个Token进行独立复杂变换(全连接层),加上位置编码,保留位置信息。
-
残差连接与层归一化(Residual Connection & LayerNorm)
- 残差连接(Add部分):各模块之间有跳跃连接(类似ResNet思想),使信息更好地流动、缓解深层网络训练难题。
- 层归一化(Norm部分):对每个子层的输出进行归一化,保证训练稳定性。
1.4 位置编码(Positional Encoding)
-
为什么需要位置编码?
- Transformer结构不再使用 基于循环 的方式建模文本输入,模型本身不具备词语之间的顺序信息(即不能感知相对/绝对位置)。
- 输入嵌入层(Input Embedding)只负责将每个单词(token)转换为向量表示,但这些向量没带有位置信息。
- 在编码器端,必须补充单词在序列中的"位置"特征,才能让模型捕捉顺序。
-
什么是位置编码?
- 位置编码(Positional Encoding):为嵌入向量加入位置信息。序列中每个单词所在的位置会被转换成一个向量(与词向量相加),以此增强模型对顺序的理解。
- 作用:让模型获得序列中各单词的顺序和相对距离信息,帮助捕捉序列结构。
-
位置编码的计算方法(正弦余弦编码)
- Transformer用不同频率的正弦和余弦函数对位置编码:
- 对于位置
和维度 ,总维度 - 同一个位置,偶数维用sin,奇数维用cos,频率指数增长,覆盖不同时间/距离尺度。
- 对于位置
- Transformer用不同频率的正弦和余弦函数对位置编码:
- 位置编码的优点
- 正弦余弦范围在
,和嵌入向量相加不会极端扰动原有信息。 - 平移不变性:由于三角函数性质,位置编码具有线性可组合性(第
的位置编码等于第 位置和第 个偏移量的线性组合),模型可直接获知词间距离。 - 自动学习利用:训练时,模型会自己学会如何用这部分信息,无需额外监督。
- 正弦余弦范围在
2. 注意力层(Self-Attention & Multi-Head Attention)
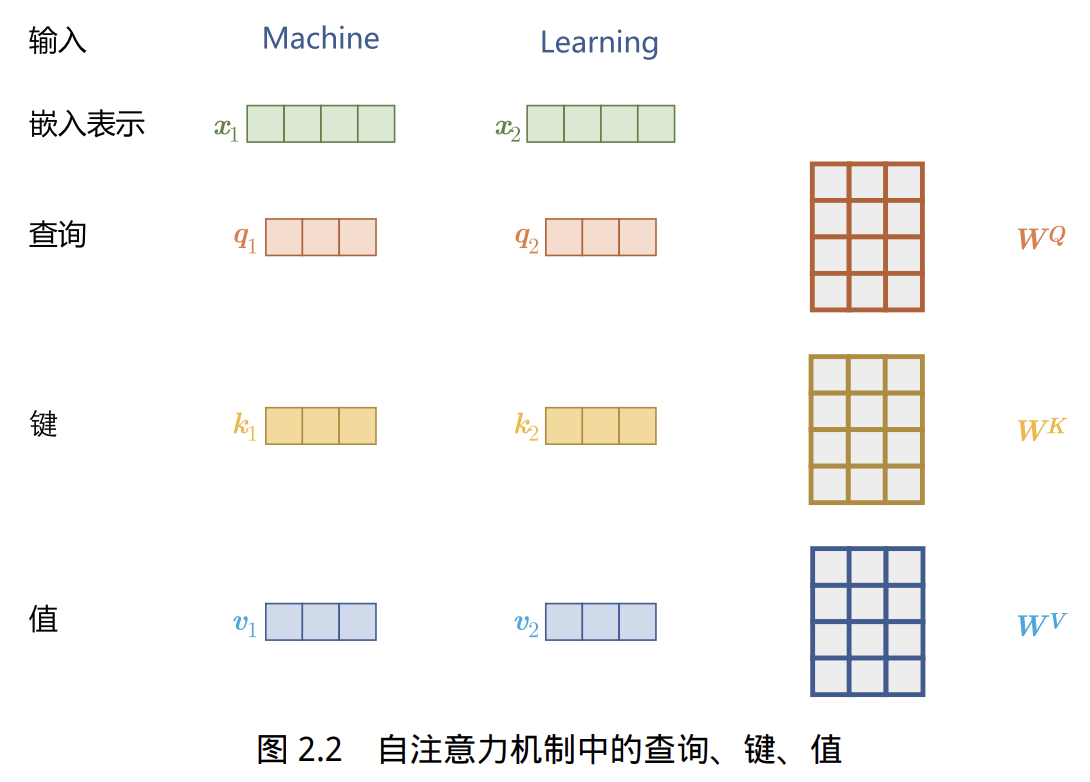
2.1 自注意力(Self-Attention)核心思想
-
自注意力机制是Transformer的核心操作,用于在序列中建模任意两个单词间的依赖关系。
-
输入为每个单词的嵌入向量与其位置编码相加后的结果,记为
。 -
为了实现对上下文的依赖建模,引入三个元素:查询(Query)
、键(Key) 和 值(Value) 。 - 这三者都是通过线性变换由输入
得到: , , 为可学习权重, 为所有输入对应的矩阵。
- 这三者都是通过线性变换由输入
2.2 自注意力权重与输出计算
-
每个输入
要关注序列中其他所有位置,关注程度通过 和 的点积打分,所有打分用softmax归一化,得到注意力权重。 -
防止梯度爆炸/收敛效率低,打分前需除以
( 为维度)。 -
最终输出是加权求和后的所有
,公式如下: -
分别为所有词的query、key、value矩阵, 为输出矩阵。
2.3 多头自注意力(Multi-Head Attention)机制
-
单头注意力可能只关注上下文的某一方面,多头注意力让模型能从不同子空间关注信息(如语法、语义、实体等)。
-
方法是使用多组独立的权重
,每组计算一组 ,再拼接后用 线性变换: -
最终输出为所有头拼接后再线性变换的结果。
-
自注意力机制使模型能自动识别输入各部分的重要性,不受距离影响,有效捕捉长距离依赖和复杂关系。
3. 前馈层(Feed-Forward Network, FFN)
-
作用与结构
- 前馈层接收自注意力子层的输出作为输入,对每个位置的表示分别进行更复杂的非线性变换。
- 具体实现:一个带有ReLU激活函数的两层全连接网络,逐位置独立应用。
-
数学表达式
- 其中
为前馈层参数
- 其中
-
设计要点
- 实验发现,增加前馈层隐藏状态的维度有助于提升模型最终性能。
- 因此,前馈层隐藏维度通常比自注意力子层要大。
-
简单讲,前馈层就是逐token的MLP,结构虽简单,却对性能影响极大。
4. 残差连接与层归一化 (Add & Norm)
4.1 残差连接(Residual Connection)
-
Transformer结构很深,包含多个堆叠的复杂非线性映射,训练难度大。
-
为提升训练稳定性,引入残差连接:每一层的输出等于子层的输出加上输入本身(即跳跃连接):
表示第 层输入, 表示该层的变换函数。
-
残差连接可有效缓解深层网络中的梯度消失问题。
4.2 层归一化(Layer Normalization, LN)
-
进一步保证各层输入/输出稳定,引入层归一化,规范每一层的分布:
和 分别是均值和方差(对当前层数据做归一化), 和 为可学习参数。
-
这样处理后,数据被平移到均值0、方差1的标准分布
。 -
作用:有效缓解优化过程中的不稳定、收敛慢等问题。
5. 编码器+解码器
5.1 掩码多头自注意力(Masked Multi-Head Attention)
- Decoder端比 Encoder端更复杂,每个Transformer块的第一个注意力子层为掩码多头自注意力。为Decoder每个Transformer块的第一层自注意力子层额外加掩码,仅用已生成(t 时刻前)目标序列的内容参与计算。
- 机制:只允许Decoder当前单词关注其前面所有(已生成)单词,掩盖未来信息,避免训练阶段"偷看"后文,保证生成时只能用已知信息。
- 原因:生成目标序列是自回归的,解码阶段每一步只能访问当前和之前已生成的token,掩码阻止模型看到后续内容,保证训练/推断一致性。
5.2 多头交叉注意力(Multi-Head Cross-Attention)
- Decoder还额外增加了多头交叉注意力模块,核心思想是Decoder可同时接收Encoder输出和本层掩码自注意力的输出。
- 实现方式:
- 查询(Query)来自解码器前一层的输出,
- 键(Key)和值(Value)来自编码器的输出。
- 作用:允许解码器"看见"编码器处理后的源语言全部信息,实现编码-解码的信息交互;对生成目标语句的上下文语义理解至关重要。
参考资料
- 《大语言模型:从理论到实践(第二版)》-- 张奇、桂韬、郑锐、黄萱菁
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付