4. Model Selection(过拟合,欠拟合)
4. Model Selection 模型的选择(过拟合,欠拟合)
1. 模型选择与评估流程
-
目标:预测谁会偿还贷款
- 银行委托你调查申请人还款情况
- 拿到100个申请人数据,其中5人在3年内违约

-
潜在陷阱与模型偏见
- 假设你发现所有违约的5人在面试时都穿蓝色衬衫
- 你的模型也“发现”了这个强信号
- 思考:这可能导致模型学到无意义甚至有害的“假相关”特征,泛化能力差,容易过拟合

-
训练误差与泛化误差
- 训练误差:模型在训练集上的误差
- 泛化误差:模型在新(未见过)数据上的误差
- 举例:
- 根据模拟考试成绩预测正式考试分数
- 在过去模拟考试表现好(训练误差低),不代表正式考试一定表现好(泛化误差未必低)
- 学生A通过死记硬背获得高分,学生B掌握原理,两者对未来考试的预测能力不同
- 根据模拟考试成绩预测正式考试分数
-
验证集与测试集
- 验证集:用于评估模型好坏的数据集
- 比如:训练集中抽取50%作为验证集
- 不要和训练数据混用(常见错误)
- 测试集:只用一次,最终评估模型泛化能力
- 例子:未来考试、房价真实成交价、Kaggle私有排行榜
- 验证集:用于评估模型好坏的数据集
-
K-折交叉验证(K-fold Cross Validation)
- 数据量有限时常用方法
- 算法:
- 将训练数据分成K份
- For
: - 第
份作为验证集,其余作为训练集
- 第
- 汇报K个验证集误差的平均值
- 常用
或
2. 过拟合与欠拟合
-
基本概念
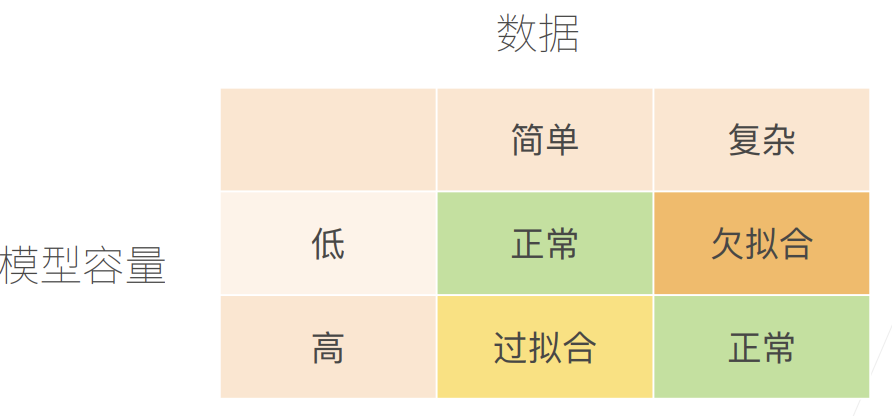
- 过拟合(Overfitting):模型在训练集表现很好,但在新数据(测试集)表现很差,本质是“学得太多”,把噪声也当成了规律。
- 欠拟合(Underfitting):模型在训练集和测试集表现都不好,本质是“学得太少”,没能学到足够的规律。
- 最佳模型:训练误差和泛化误差(验证/测试集)都低。
-
模型容量
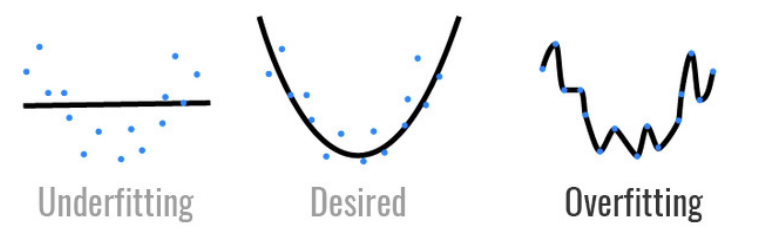
- 模型容量:衡量模型拟合各种复杂函数的能力
- 低容量模型:难以拟合训练数据(易欠拟合)
- 高容量模型:能记住所有训练数据(易过拟合)
- 理想情况是模型容量刚好匹配数据复杂度,不过高也不过低
- 模型容量:衡量模型拟合各种复杂函数的能力
-
容量-误差关系
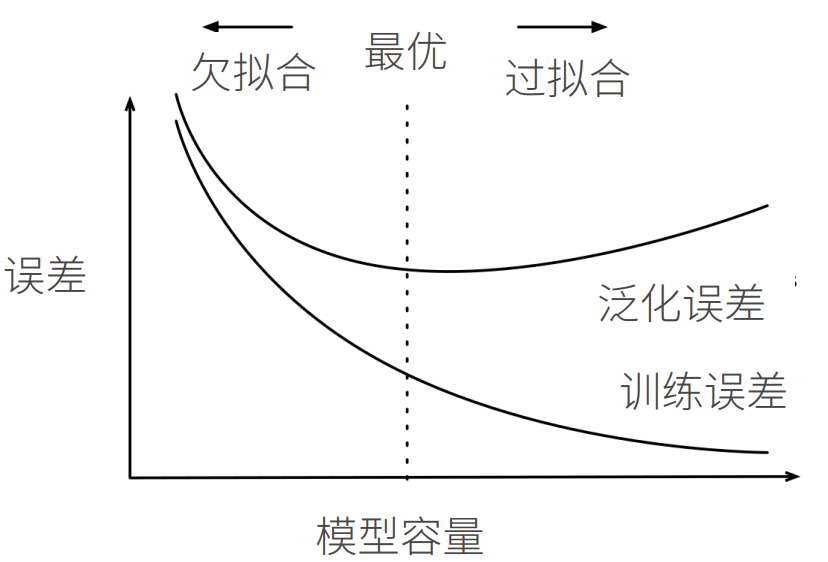
- 误差和容量的关系通常呈“U型”:容量低,误差高(欠拟合);容量高,训练误差低但验证误差升高(过拟合);中间有最优区间
-
如何估算模型容量
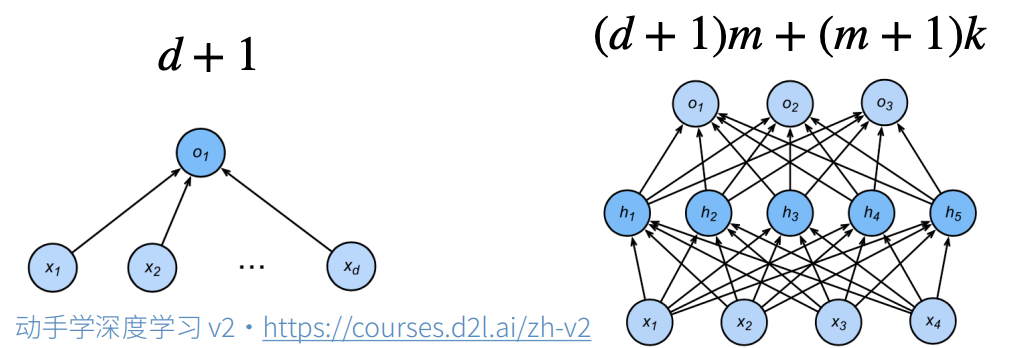
- 不同模型之间容量难直接比较(比如神经网络vs线性模型)
- 同类模型下,容量主要由:
- 参数个数
- 参数选择范围
-
VC维(Vapnik-Chervonenkis Dimension)
- VC维是统计学习理论中衡量模型复杂度的数学工具
- 本质:对于一个模型,VC维等于它能“完美分分类”的最大点数
- 例如:2维输入的感知机VC维=3,可以区分任意3点,不能区分4点(xor)

-
VC维的意义与实际应用
- VC维提供了模型好坏的理论解释:VC维越大,模型容量越大
- 能衡量训练误差和泛化误差之间的间隔
- 但深度学习实际应用较少,因为难以准确衡量复杂模型的VC维
-
数据复杂度
- 影响拟合难度的“数据复杂度”因素包括:
- 样本个数
- 每个样本的维度
- 时序/空间结构
- 多样性
- 影响拟合难度的“数据复杂度”因素包括:
3. 总结
- 训练集:训练模型参数
- 验证集:选择模型超参数
- 测试集:只用来评估最终效果(不能调参)
- 非大数据集常用K折交叉验证,提升模型评估可靠性
- 模型容量要与数据复杂度相匹配,否则易欠拟合或过拟合
- 统计机器学习提供数学工具衡量模型容量,实际深度学习多用误差曲线观测
- 常用做法:通过观察训练误差和验证误差,辅助调整模型容量和正则化等超参数
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
4. Model Selection(过拟合,欠拟合)
http://neurowave.tech/2025/04/22/10-4-LNN-ModelSelection/