5. Weight Decay(权重衰退)
5. Weight Decay(权重衰退)
-
权重衰退的作用
- 权重衰退(Weight Decay) 是通过在损失函数中加入一个正则化项,来限制模型的容量,防止过拟合。
- 在训练过程中,模型会学习到较小的参数值,从而避免权重过大。
- 通过对参数加上惩罚项,使得训练过程中模型学习到的参数不会过大,从而抑制过拟合。
-
权重衰退的公式
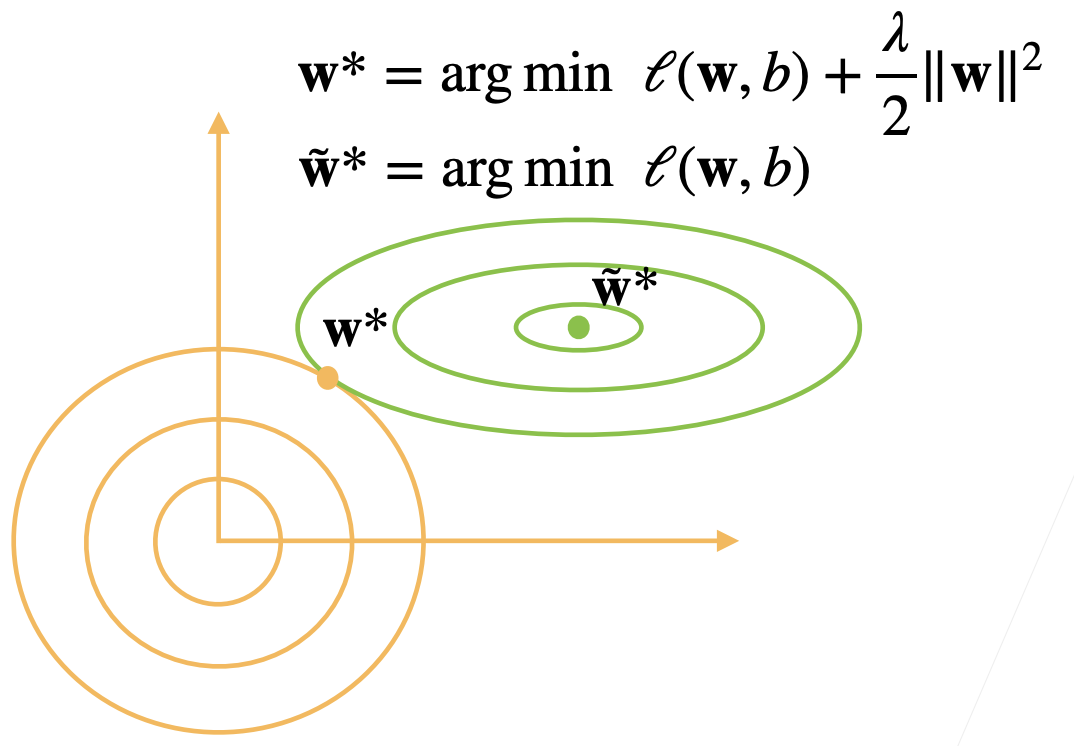
- 权重衰退通过L2范数来实现,即在目标函数中加入一个参数的L2范数(参数的平方和)作为惩罚项:
- 这里,
是原始损失函数, 是权重的L2范数, 是正则化超参数,控制权重衰退的强度。 表示没有正则化, 时,模型会强迫所有的权重接近0。
- 这里,
- 权重衰退通过L2范数来实现,即在目标函数中加入一个参数的L2范数(参数的平方和)作为惩罚项:
-
权重衰退对模型训练的影响
- 没有权重衰退(无L2正则化):
- 模型容量可能过大,导致过拟合,训练误差低但测试误差高。
- 添加权重衰退(L2正则化):
- 通过正则化惩罚项,模型参数被限制,不会过大,从而降低过拟合风险。
- 如果
值较大,可能会导致欠拟合,模型难以适应数据。
- 没有权重衰退(无L2正则化):
-
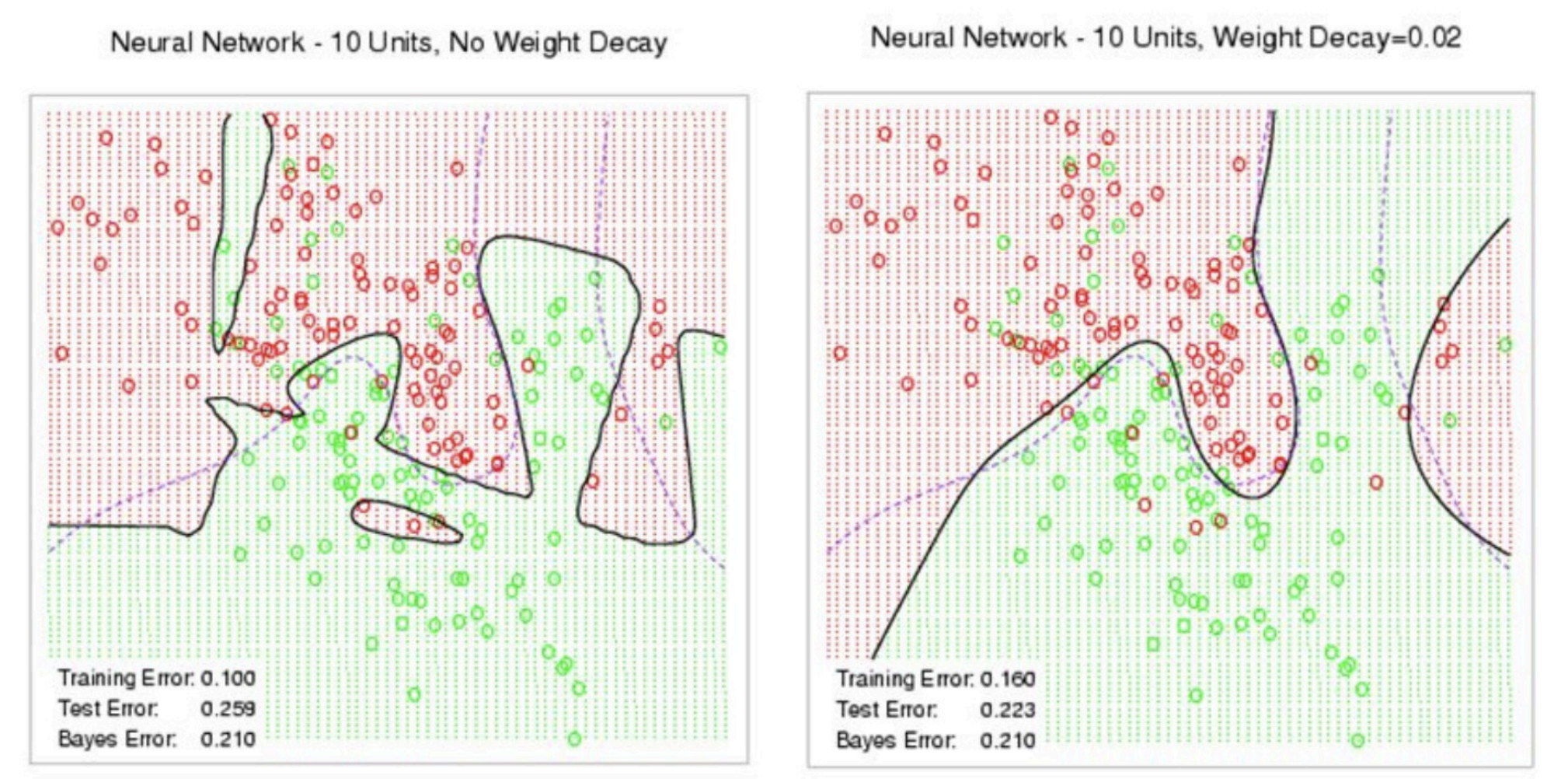
权重衰退的图示
-
图示展示了没有和有权重衰退的情况:
- 左图:没有权重衰退时,模型容易发生过拟合,训练误差较小但测试误差较大。
- 右图:有权重衰退时,模型参数受到限制,测试误差得到改善。
-
-
使用均方范数作为软性限制
-
L2正则化作为一种软性限制,可以限制参数的大小,但不会完全消除它们。
-
不对偏置项b进行正则化:偏置项通常不会受到正则化影响,因为它不影响模型复杂度。
-
通过调整超参数
,可以控制正则化项的影响程度: :没有正则化,过拟合风险较大。 - 较小的
:正则化效果较弱,模型有更多自由度,但仍然有限制。 - 较大的
:强正则化,模型会倾向于较小的参数,可能导致欠拟合。
-
-
参数更新规则
-
梯度计算:
-
参数更新:
- 这里
是学习率, 是权重衰退系数。 - 通常
,在深度学习中交权重衰退。
- 这里
-
总结
- 权重衰退通过L2正则化来控制模型的复杂度,防止过拟合。
- 正则化超参数
决定了正则化的强度,影响模型的泛化能力。 - 适当的权重衰退可以帮助模型在训练集和测试集上都获得较好的表现。
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
5. Weight Decay(权重衰退)
http://neurowave.tech/2025/04/22/10-5-LNN-权重衰退/