7. 数值稳定
7. 数值稳定
1. 数值稳定性
-
神经网络的梯度
- 考虑一个有
层的神经网络:
- 计算损失
关于参数 的梯度:
- 链式法则:反向传播时,多个层的梯度相乘,导致数值可能急剧增大或减小。
- 考虑一个有
-
梯度爆炸与梯度消失
- 梯度爆炸(Gradient Explosion):参数更新过大,导致模型权重数值不断增大,最终发生溢出。
- 示例:
。
- 示例:
- 梯度消失(Gradient Vanishing):随着反向传播的进行,梯度变得非常小,导致无法有效更新模型权重。
- 示例:
。
- 示例:
- 常见诱因:层数过深、激活函数/初始化不当、学习率失控。
- 梯度爆炸(Gradient Explosion):参数更新过大,导致模型权重数值不断增大,最终发生溢出。
-
激活函数的影响
-
ReLU :一般能缓解梯度消失,但依然可能导致爆炸。
- 如果
较大,梯度会变得非常大,造成数值爆炸。
- 如果
-
Sigmoid: 在区间两端梯度非常小,极易导致梯度消失。
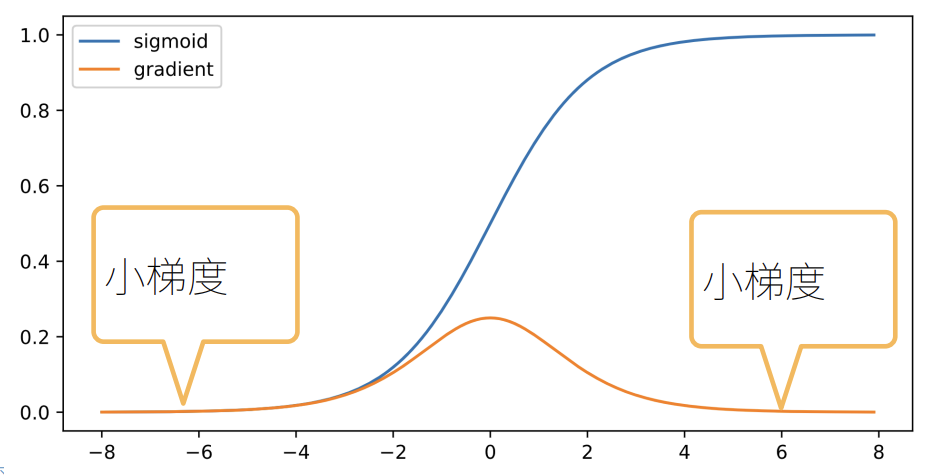
-
-
计算中常见的数值不稳定
- 数值溢出:参数值过大或过小,超出数值类型(如16位浮点数)的表示范围。
- 学习率敏感:学习率过大→爆炸,过小→不收敛
- 深层网络更易中招:链式乘积n次,深度越大,越不稳定。
-
例子:在MLP中,前向传播和反向传播都受到激活函数的影响。使用ReLU:爆炸风险更大。使用Sigmoid:消失风险更大。
- 使用ReLU:
- 使用Sigmoid时:
2. 让训练更加稳定
- 目标:让梯度值在合理的范围内(例如
)。 - 将乘法变加法:例如:ResNet、LSTM
- 归一化:梯度归一化、梯度裁剪
- 合理的,权重初始化、激活函数
MLP中的例子
- 目标:让每一层的输出和反向梯度的方差都是常数,避免数值爆炸或消失。
- 每层输出和梯度都看作随机变量,要求均值为0、方差为常数(独立同分布)。
-
假设:
是独立同分布(i.i.d.),且满足: 独立于
-
没有激活函数:
,其中 。
- 正向方差:
- 反向传播梯度:
- 为保证所有层的方差一致,理想要求
且 ,但实际很难同时满足。
- 常用:Xavier初始化(针对深度网络)
- Xavier初始化可以避免梯度爆炸或消失。
- Xavier初始化:适用于深度神经网络,通过平衡层输入输出的方差,使梯度在训练过程中更加稳定。
; - 正态分布:
- 均匀分布:
- note:
的方差为 。
3. 结论
- 梯度爆炸和梯度消失是深度神经网络常见的数值稳定性难题,尤其在网络层数增加后更突出。
- 主要对策有三条:
- 权重初始化要科学:优先选用Xavier或He初始化,降低数值极端波动风险。
- 归一化机制要用好:如Batch Normalization,让每一层的输出和梯度方差都在合理范围,防止异常扩散或消失。
- 激活函数要选对:避免Sigmoid等极易导致梯度消失的激活函数,推荐ReLU及其变体。
- 训练过程中还需关注学习率调整,权重初始化和归一化相结合才能最大程度保证数值稳定。
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
7. 数值稳定
http://neurowave.tech/2025/04/22/10-7-LNN-数值稳定/