从0训练 LLM 的完整流程
全文来自对 【LLM】从零开始训练大模型 的整理,但由于原文格式上阅读不太舒服,花了很长时间整理,同时也扩展了一些内容。
原文的配图会更丰富,如果需要可以去原文查阅,下文只包含重要的效果图展示。
在这篇笔记中,详细梳理一个完整的大语言模型(LLM)训练流程,包括:
- 模型预训练(Pretraining)
- Tokenizer 训练
- 指令微调(Instruction Tuning)
- 奖励模型(Reward Model)
- 强化学习(RLHF)
1. 预训练阶段(Pretraining Stage)
目前,常见做法是在已有基座模型基础上进行微调,例如 alpaca、vicuna。这种方式要求基座模型与下游任务有较高契合度。实际中可能遇到以下问题,导致开源 backbone 难以直接使用:
- 语言适配问题
- 专业知识不足
- 通用预训练的语料难以覆盖如金融、法律和医疗等领域的专有知识。解决方法是引入领域数据,例如 xuanyuan 2.0 用大规模专业语料补足模型短板。
1.1 Tokenizer 训练
在大模型预训练流程中,选择合适的模型基座是首要步骤。然而当前主流大模型普遍缺乏充分的中文预训练,因此业界常采用"二次预训练"策略——将英文表现优异的模型(如LLaMA)通过大规模中文语料进行适配性训练,使其具备中文处理能力。Chinese-LLaMA-Alpaca 即是该领域的代表性成果。
为提升中文处理效果,研究人员通常会对原始tokenizer进行词表扩展。这种扩展主要针对OOV(Out-Of-Vocabulary,词表外字符)问题,通过向原始词表中手动添加高频汉字及子词实现。以Chinese-LLaMA为例,其在LLaMA原始词表基础上新增了17,953个中文token;而BELLE 项目则采取分阶段训练策略:先用120万行中文语料训练出包含5万个token的专用词表,随后与原有词表合并,最终通过更大规模的中文语料进行微调。分词效果可通过tokenizer_viewer 工具直观验证。
主流的分词方式大致分为三类:
- WordPiece:基于字词匹配的分词方法,在单语言场景下简单高效。但面对多语言混合文本时,词表规模易失控。
- BPE(Byte Pair Encoding):基于Unicode字节的统计分词算法,通过合并高频字节对实现切分。相比WordPiece更适用于多语言场景,但对特殊字符的处理仍存在局限。
- Byte-level BPE(BBPE):粒度最细的分词方案(如LLaMA采用),直接将文本分解为UTF-8字节序列。例如"编""码"等常见字可独立成2个token,而"待"等未登录字符会被拆分为3个Unicode单元。其原理详见知乎解析 。
BBPE的核心优势在于理论上杜绝OOV问题——无论字符多生僻,只要能用Unicode表示即可被拆解处理。但其训练复杂度显著提升:模型需学习合法汉字的Unicode序列组合规则,否则可能生成乱码(如无效字符���)。因此工程实践中多采用"BBPE+词表扩展"的折中方案——在保留BBPE基础框架的同时,将高频汉字直接加入词表。此举既能降低OOV率(实测可减少约30%未登录词),又避免词表过度膨胀,兼顾训练效率与效果。
总结来说,WordPiece适合单语言简单场景但扩展性有限;BBPE虽能完美解决OOV却伴随高训练成本。当前中文大模型普遍采用BBPE框架下的词表扩展策略,已成为行业标准方案。若实际应用中出现乱码或生僻字切分异常,建议优先检查tokenizer适配性,尝试增量式词表扩展,往往可快速解决此类问题。
1.2 语言模型预训练
扩充完 tokenizer 后,正式进入模型的预训练阶段。Pretraining 的核心其实很简单,就是让模型吃一大堆文本,做 Next Token Prediction。具体流程里,数据采样、数据预处理和模型结构设计,是影响效果的关键环节。
-
数据源采样:以 GPT-3 的训练为例,其数据源采用非均衡采样策略:
- Common Crawl 虽占整体数据的82.1%,但实际采样比例仅为60%,导致仅完成0.44个epoch训练
- 高质量小规模数据(如 Wikipedia)通过高权重采样实现多轮训练
- 此举旨在平衡数据规模与质量,避免模型过度依赖低质量海量数据,同时确保稀缺但高信息密度的优质数据被充分学习。
-
数据预处理:核心环节是文本向量化转换。与Finetune阶段常见的截断策略(如2048 token后丢弃)不同,预训练阶段需最大化上下文窗口利用率:
- 对长文本按指定序列长度seq_len(通常为2048)进行滑动窗口切片
- 每个片段独立参与训练,确保完整语料的信息不丢失
- 该方法可使整本书籍的文本信息被完整编码,显著提升语料利用率。
-
模型结构设计:为了提升训练效率和模型性能,业界在 decoder 架构上玩了很多“加速” trick,主要集中在 Attention机制改进 与位置编码增强。
- Attention加速技术
- MQA(Multi Query Attention) :通过共享查询头降低显存消耗(如 Falcon-40B )
- Flash Attention :利用内存优化算法提升计算效率
- Position Embedding 优化
- ALiBi (Bloom 采用):通过线性偏差增强长序列建模
- RoPE (GLM-130B 采用):结合旋转矩阵实现绝对位置感知
- 能让模型对不同长度的输入都保持比较稳定的效果。参考:LLM 加速技巧:Multi Query Attention 和 Attention with Linear Bias(附源码)
- Attention加速技术
-
Warmup & Learning Rate 策略:训练过程中需采用动态学习率调度策略
- 资源充足场景 :直接设置较大学习率(如1e-4),加快收敛速度
- 资源受限场景 :采用小学习率(如5e-5)配合长warmup步数(建议500-2000步),确保训练稳定性
1.3 数据集清理
中文预训练数据集可以使用悟道作为基础语料库,其数据分布以百科全书和博客内容为主。开源数据集适合实验验证,若需进一步提升模型性能,则需要自定义数据集构建流程。根据Falcon论文披露的核心发现,仅使用「清洗后的互联网数据」就能够让模型比在「精心构建的数据集」上有更好的效果,一些已有的数据集和它们的处理方法如(Paper中):
- 数据源统计与专属清洗:先统计每种数据源占比,为不同来源设定专门的清洗策略。
- 数据规模筛选:比如 RefinedWeb 原始有 5000G tokens,最终只保留了 20% 最优质部分用于训练,直接暴力提纯。
- 多级去重:Falcon LLM 用精确(exact)和模糊(fuzzy)去重,在文档级和行级都做,外加“三句跨度去重”,直接干掉多句内重复内容,保证段落不冗余。Fuzzy 去重常用 fastText 在高质量(HQ)数据上训练。
- 内容过滤:依赖 URL 黑名单、内容规则、敏感词等,剔除垃圾站点、低质内容和敏感文本。部分流程直接用机器学习模型(如 fastText)自动判断文本质量。
- 长度/语种筛选:过滤掉小于 100 字符的短文本,用 fastText 或 Cld3 检查文本语言,自动剔除非目标语种内容,保证数据纯净。
- NSFW过滤(可选):按需额外清理色情/违规内容。
- 高质量优先原则:最终只保留约 20% 高质量文本,保证训练数据多样性、有效性。
- 自动+人工结合:大部分环节自动完成,遇到敏感或争议内容再人工复查,确保数据安全和可控。
有关 Falcon 更多的细节可以看这里:何枝:【Falcon Paper】我们是靠洗数据洗败 LLaMA 的!
1.4 模型效果评测
LLM 的评测通常分为两类:语言拟合能力和知识蕴含能力。最基本的量化指标是 PPL(Perplexity) 和 BPC(Bits Per Character)。可以简单理解为,这些指标都是在生成文本和目标文本的 Cross Entropy Loss 上做变形,反映模型对“语言模板”的拟合程度——比如一句话的上下文,预测接下来哪些字词是合适且通顺的。但现在大部分 LLM 都能写出流畅句子,仅靠 PPL、BPC 很难拉开差距。因此,评估 LLM 的“知识蕴含能力”才是关键。
C-Eval:中文知识能力测试 :C-Eval 是专门针对中文大模型设计的知识测试集,涵盖 1.4 万道选择题、52 个学科。做法很直观,把题目写进 prompt,让模型续写 1 个 token,看它是否能正确给出「A/B/C/D」答案。
大部分“只预训练没精调”的模型,直接续写未必能老老实实输出「A/B/C/D」,所以官方建议用 5-shot 提示——即在 prompt 前给 5 道带标准答案的样题,让模型学会格式。如下:
1 | |
接下来取模型在「答案:」后第一个 token 的 logits,只看 A/B/C/D 四个字母的概率,归一化后判断答案。因为是 4 选 1,基线是 25%。这个方式可以清晰拉开模型在“中文知识”维度的表现。C-Eval 的评测结果也再一次印证了 GPT-4 在知识能力上的强势。
1 | |
总结:现在 LLM 评测不再只看生成通顺,而是要看“能不能答对问题、理解知识本身”。这也是未来大模型比拼的主战场。
2. 指令微调阶段(Instruction Tuning Stage)
第一阶段的预训练完成后,模型虽然变得“见多识广”,但本质上还是在做“续写”——它只是学会了根据前文继续写下去。这就会出现一个问题:模型生成的内容,经常并不是我们真正想要的答案。比如:
| 用户问题 | 用户预期回答 | 模型续写结果 |
|---|---|---|
| 《无间道》的主演有哪些? | 刘德华、梁朝伟 | 《无间道》的主演有哪些?不少观众期待看到阵容公告,今天小编… |
造成这种现象的根本原因,是预训练语料大多来自互联网,里面“一问一答”的格式其实很少,大部分都是“写写写”,很少“答答答”。所以模型经常不会正面回答,而是照着原样续写。但你让它换个问法,比如:
| 用户问题 | 用户预期回答 | 模型续写结果 |
|---|---|---|
| 《无间道》的主演有 | 刘德华、梁朝伟 | 《无间道》的主演有刘德华、梁朝伟和黄秋生,而这部电影也是香港警匪片的代表作之一。 |
这样,模型就会“无意识地”把答案带出来——但还是不够自然,也不符合人类问答的风格。所以,指令微调(Instruction Tuning) 的目标,就是教会模型如何理解和执行“你直接给我答案”这种人类指令。也就是所谓的“指令对齐”。OpenAI 在 Aligning instructions 里就做了这种实验。原生GPT-3 只是在做续写任务,但 InstructGPT 则能“乖乖”按你的需求回答问题。
指令微调本质上就是用大规模 “人类问答式” 样本继续训练,让模型逐渐掌握“对话”和“执行指令”的习惯,变得更像助理、更像人。这一阶段,也为后面的 RLHF(强化学习人类反馈)打好了基础。
2.1 Self Instruction
要让模型学会“像人一样对话”,最直接的方法就是给它大量真实问答数据。InstructGPT 论文用 1.3 万条人工标注数据(labeler 标注)对 GPT-3.5 做了监督学习(SFT)。
但这条路有个大问题:全靠人标注,成本太高,效率很低,而且还得保证团队专业、认知统一。OpenAI 有人有钱能搞,但普通团队很难复刻。
现在有了 ChatGPT,其实可以让 ChatGPT 来“教”自己的模型,这就是 Self Instruction(自监督指令生成)的核心思路。本质就是让 ChatGPT 充当“超级标注员”,蒸馏出自己的问答样本。
最有名的项目是 stanford_alpaca。它不仅让 ChatGPT 给答案,还让它自己“想”问题——即从一批“种子指令”(seed)出发,要求 ChatGPT 不断扩展出更多新问题和标准答案。
英文 Alpaca 已经很火,中文社区也搞了类似的项目,比如 BELLE。
BELLE 的套路很简单:先给 ChatGPT 一些范例,然后让它模仿生成更多多样化、高质量的“指令-输入-输出”训练样本。
关键点:
- 指令类型要多样(如开放问答、封闭问答、分类、总结、生成等)
- 不重复动词、不限制语气、内容要现实且有挑战性
- 有输入的要给具体上下文,没有输入的就写“无输入”
举个例子,生成指令样本的 prompt 可以像这样:
1 | |
这样,模型就能自动“批量制造”训练数据,大大降低人力成本,同时还可以持续扩展各种场景和任务类型。关于 BELLE 的更多细节,可以参考这篇文章:让ChatGPT生成训练ChatGPT的训练数据
2.2 开源数据集整理
本章简单梳理几组开源 Instruction Tuning 数据集。除了直接“拿来用”,也可以分析它们的设计套路,学会怎么构建属于自己的指令数据集。
-
Alpaca:stanford_alpaca 用 self instruction 方法,搞了 5200 条指令训练样本。 每条数据都有 instruction(要求)、input(输入)、output(标准答案),样例如下:
1
2
3
4
5{
"instruction": "Arrange the words in the given sentence to form a grammatically correct sentence.",
"input": "quickly the brown fox jumped",
"output": "The quick brown fox jumped quickly."
}- Alpaca 覆盖多种任务类型(写作、描述、分类、摘要等),数据类型分布比较均匀,适合泛用训练。
-
BELLE:BELLE 提供了规模从百万到数百万的数据集,100万、200万、350万 都有,完全够用。 数据样例:
1
2
3
4
5{
"instruction": "判断给定的文章是否符合语法规则。如果不符合,请提供修改建议。下面是一篇文章的开头: '为了探讨这个主题,本文将提供一系列数据和实例,以证明这一观点。'",
"input": "",
"output": "这个开头符合语法规则。"
}- 虽然整体分布无法精确统计,但从 1000条评测集 可以看出,任务类型非常丰富,涵盖摘要、开放/封闭问答、分类、抽取、头脑风暴、重写、Code & Math 等场景。
任务名称 例子 文本生成 为一种智能手表编写用户手册,包括详细的使用说明和操作步骤。 头脑风暴 针对“如何提高公司销售额”进行头脑风暴并记录所有想法。 开放域问答 用一两句话描述尼罗河是如何形成的。 封闭域问答 选择填空:他喜欢去_______看电影。A) 邮局 B)超市 C)电影院 D)音乐会 分类 将文章归类为新闻报道、科学文章或社论。 抽取 根据表格信息提取“张三”的考勤情况。 重写 将一段关于纽约市的介绍改写得更简明扼要。 摘要 总结一个故事里最重要的三个事件。 Code & Math 写一个SQL查询所有性别为女性学生的姓名和学号。
- 虽然整体分布无法精确统计,但从 1000条评测集 可以看出,任务类型非常丰富,涵盖摘要、开放/封闭问答、分类、抽取、头脑风暴、重写、Code & Math 等场景。
-
其它代表性数据集
2.3 模型的评测方法
相比预训练阶段(如 PPL、NLL 等有明确标准的指标),Instruction 阶段模型到底“聪不聪明”“听不听话”就没那么好量化。过去常用的 BLEU 或 ROUGE 等自动评分方法,在当前大语言模型场景下已经无法准确反映模型实际表现。
现在更流行的一种做法,是借鉴 FastChat 等项目,用 GPT-4 对各类开源模型的生成结果进行打分。我们同样采用了 GPT-4 评分,对三种开源模型(OpenLlama、ChatGLM、BELLE)进行了测试。
注意:以下测试仅为作者的实验结果,不具备权威性。
-
GPT-4 评测流程说明
-
每道题我们先获得 ChatGPT 的回答,以及三种候选模型的回答。之后,将「ChatGPT 答案」和「候选模型答案」配对输入 GPT-4,让它给每个答案打分(满分 10 分),并写出打分理由。我们针对每一类任务单独统计分数,最后汇总出每个模型的平均得分。
-
部分评分数据(GPT-4 评测结果示例)
Model open qa classification summarization rewrite closed qa extract average origin-openllama 0.9500 1.1000 1.0600 0.9400 1.0400 1.0500 1.0200 chatglm 1.0100 0.9000 1.1100 0.8500 1.0300 1.0000 0.9800 belle-original 0.7700 1.0000 0.8200 0.9300 0.8200 0.8200 0.8600 -
打分 prompt 参考如下: GPT-4 会根据帮助性、相关性、准确性、细节等维度进行评分,每次给出两个分数(对应两份答案),并在后续说明理由。
-
-
评分局限与人工 Review
- 实际测试中,我们发现 GPT-4 的评分和理由并不总是准确的。例如,有的题目明明 Instruction 设定很明确,GPT-4 却因为小的表述修改给了高分。此外,单纯改变句子顺序也可能影响评分。为此,我们还尝试对调换顺序的结果做平均处理,但发现 GPT-4 的评分依然存在主观性。
- 为了验证 GPT-4 打分的有效性,我们又增加了一轮人工 Review,对每个答案进行人工评分,并给出了详细的打分规则:
- 准确性:是否严格执行指令、信息是否覆盖完整、可读性、无害性等。
- 评分标准:
- 未评价(-100):人工未评分,不计入均值。
- 很差(-2):明显劣于 ChatGPT,如答错、跑题。
- 稍差(-1):略差于 ChatGPT,整体正确但可读性差。
- 持平(0):和 ChatGPT 表现基本相当。
- 稍好(+1):略好于 ChatGPT,答得更准或更好读。
- 很好(+2):明显优于 ChatGPT,答得更正,ChatGPT 有明显错误。
- 人工 Review 的主要结论:
- 在 GPT-4 打分结果中,部分开源模型分数甚至超过了 ChatGPT(比如分数 1.02)。
- 但经过人工 Review,ChatGPT 的答案更符合我们主观认知。
- 新的评测方法不断涌现,比如 PandaLM。
- 越来越多权威评测集被广泛应用,如 C-Eval、open_llm_leaderboard 等。
Instruction 阶段的自动评价还远不完美。GPT-4 评分虽然高效,但结果有偏差,不能完全替代人工 Review。多种新方法和基准正在持续涌现,建议实际评测中多角度、多方法结合使用。
3. 奖励模型(Reward Model, RM)
何枝:【RLHF】想训练ChatGPT?得先弄明白Reward Model怎么训(附源码) 介绍奖励模型(Reward Model,RM)的基本原理和实际训练方法,并且给出了实验代码和 rank list 标注平台的介绍。这个平台用于对模型生成的结果进行排序标注,便于后续 RM 的训练。Rank List 标注平台的界面,支持自定义 prompt,生成多条模型回复,并由人工对每条回复进行排序,结果会作为 RM 的训练数据:
- 左侧显示了当前模型的配置信息(如模型名称、设备、数据集、rank 列表长度、生成序列最大长度等)。
- 中间可以输入 prompt(如“今天早晨我去了”),平台会生成多条候选回复,并允许用户为这些回复手动排序。
- 下方则显示了根据人工排序结果生成的最终排名数据,这些数据可用于训练奖励模型。
3.1 奖励模型(RM)的必要性
在完成 SFT(Supervised Fine-Tuning)后,我们通常已经能得到一个表现不错的模型。但仔细回顾 SFT 的整个过程,其实我们一直只是在告诉模型什么是“好”的数据,并没有明确指出什么是“不好”的数据。SFT 更多的是一种引导手段,用来激发预训练模型中已有的知识。然而,由于 SFT 数据有限,对模型的引导能力也有限,这就导致预训练模型中原有的“错误”或“有害”内容可能没能被及时修正,最终引发模型产生“有害性”或“幻觉”等问题。
为了解决这个问题,学界提出了让模型摆脱高昂人工标注、实现自我迭代的方法,比如:RLHF (Reinforcement Learning from Human Feedback) 和 DPO (Direct Preference Optimization)。无论是 RL 还是 DPO,本质上都需要让模型区分“好”的数据和“不好”的数据:
- RL 方法是直接给模型一个样本的得分(好/坏)。
- DPO 则是同时给模型一条好的样本和一条坏的样本。
而如何判断样本的“好坏”?除了依赖昂贵的人工标注,RM 的出现就显得非常关键了——它可以自动评判生成数据的优劣,大大提升训练效率和效果。
3.2 利用偏序对训练 RM
在 OpenAI 的 Summarization 和 InstructGPT 论文中,都采用了「偏序对」方法来训练奖励模型(Reward Model, RM)。所谓偏序对,就是不直接给每个样本打具体分数,而是用“哪个更好”这种顺序关系来标注。例如:
- 直接打分:A 句子(5分),B 句子(3分)
- 偏序对标注:A > B
训练时,模型会尝试最大化“好句子得分与坏句子得分之间的分差”,让 RM 自动学会区分优劣。
(为什么采用偏序对而不是直接打分?详情可参考上面论文。)
-
实验示例:我们可以这样构造训练数据:
1
2
3
4
5{
"prompt": "下面是一条正面的评论:",
"selected": "屯了一大堆,今年过年的话蛮富足的!到货很快的!",
"rejected": "对商品谈不上满意,但是你们店的信誉极度不满意,买了件衣服取消了订单,要求退款,结果退款过程进行一半就不进行了,真是因小失大啊"
}- prompt 要求模型续写一条好评。
- selected(A):正面评论
- rejected(B):负面评论
- 我们用 llama-2-7b 作为训练基座,期望模型给 A 更高分,B 更低分。
-
Loss 与训练过程可视化:Reward Model 的 loss function 就是让 r(A) - r(B) 的分差最大。下图展示了 RM 训练日志(step 越大,训练越久):
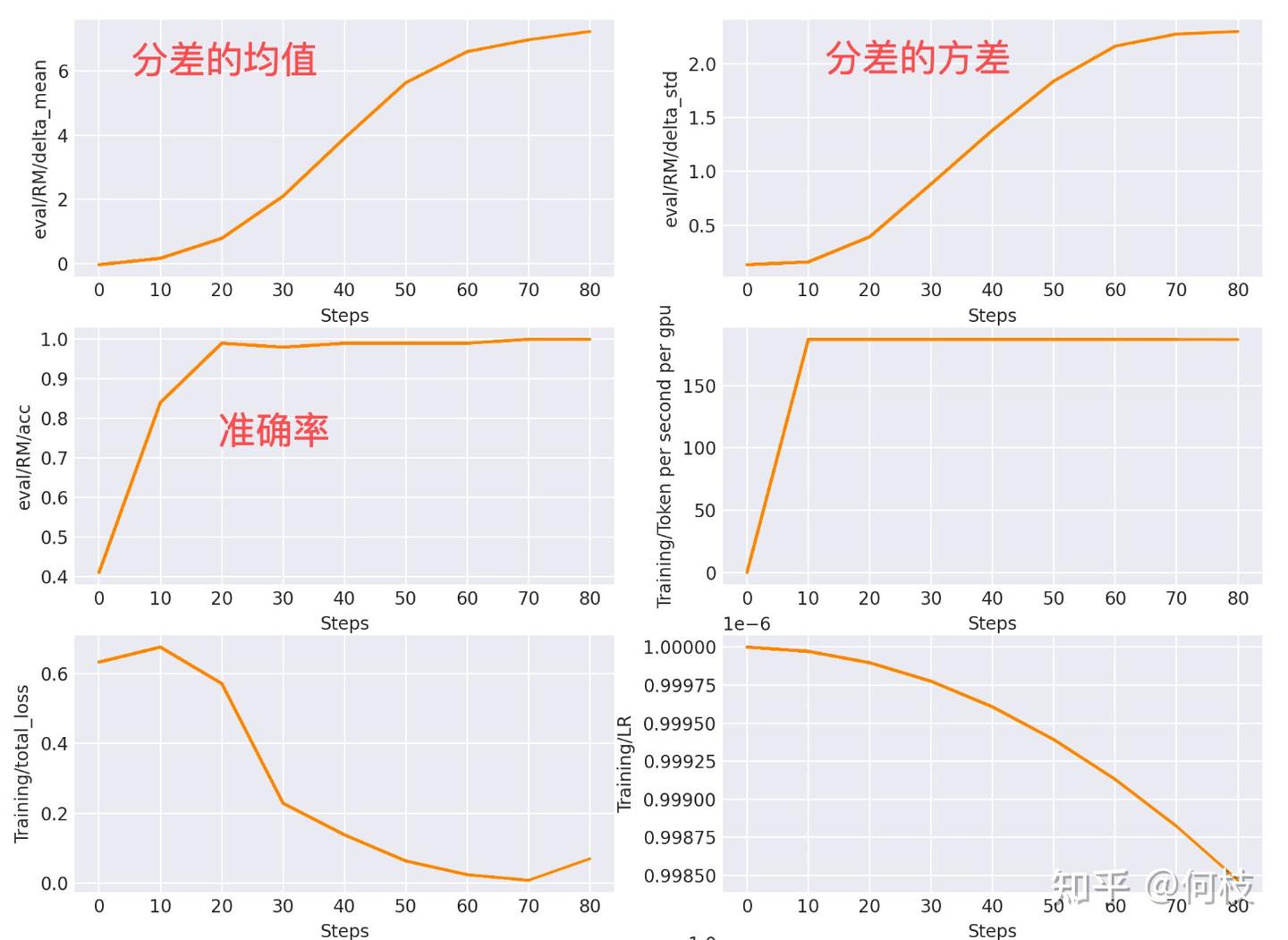
- 一排左图:分差均值随 step 增大不断上升,说明模型越来越能区分好坏。
- 一排右图:分差方差随训练也逐渐变大。
- 二排左图:准确率提升很快,并趋于稳定。
- 三排左图:loss 不断下降。
- 三排右图:学习率(Learning Rate)变化。
- 进一步画出 100 个评测样本的分差分布(见下图):
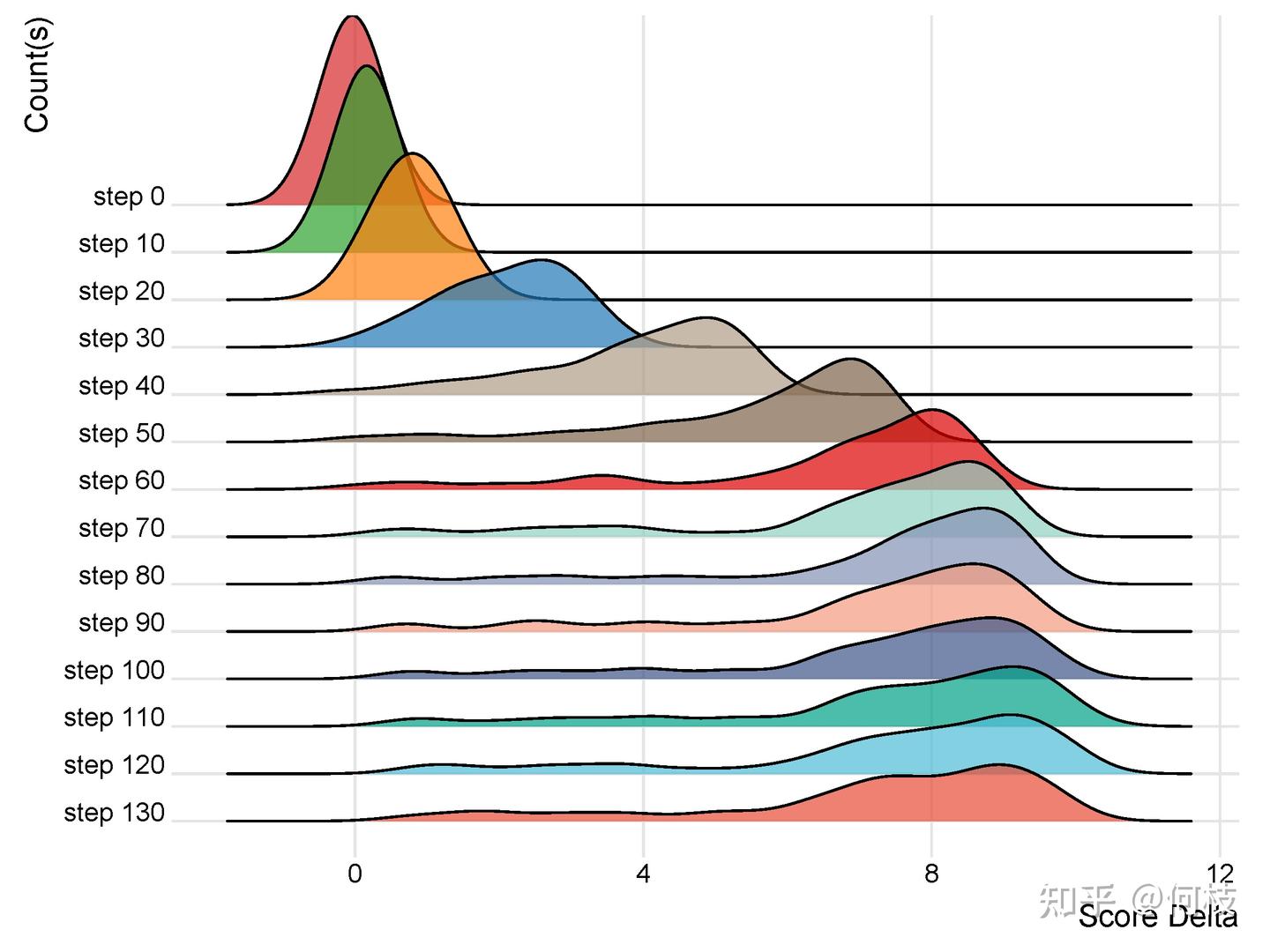
- step 0(未训练)时,分差分布接近均值 0,方差很小,模型基本不会区分好坏;
- 随着训练,分布均值持续变大,表明模型对好坏数据的区分能力不断增强;
- step 60 之后,分布趋于稳定。
-
限制与改进:虽然这样,偏序对本身还是“粗糙”了些,会导致打分不够精准。有些后续工作会在偏序标注基础上,进一步标注“A比B好多少”;也有的会在 Reward Gap Loss 基础上,添加 Preferred Sample 的 LM Loss。细节可以参考:
通过偏序对训练 Reward Model,可以让模型逐步学会“好回答”和“坏回答”的区分能力。随着训练进行,模型的判断越来越准确,但要进一步提升效果,还需要更细致的标注和优化。
3.3 使用多少数据能够训练好一个 RM?
不同任务对训练数据量的需求差别很大。比如:
- 在 OpenAI 的 Summarize from Feedback 任务中,使用了约 6.4 万条偏序对进行训练。
- 在 InstructGPT 任务中,训练用了大约 3.2 万条偏序对(数据规模详见 InstructGPT 论文 page 33,可以看到,RM 训练数据的总量通常在几万条以上,且不同数据集来源和用途略有不同)。
- 在 StackLlama 任务中,数据规模达到了 10 万条,来源于 Stack Exchange。
通过这些项目经验,还无法给出训练出稳定 RM 所需的“最小量级”结论,这很依赖具体任务和领域。但实际工程中,5 万条以上的偏序对通常是相对稳妥的规模参考。关于 Reward Model 的 scaling law 细节,可参考 OpenAI 相关论文与RLHF 训练中,如何挑选最好的 checkpoint?。
3.4 RM 模型的大小限制?
Reward Model(RM)的本质任务是对生成模型的内容进行打分。因此,RM 只需要具备理解和判断能力即可,对模型规模的要求其实没有生成模型那么高。目前业界对于 RM 的大小并没有明确的标准或限制。例如:
- OpenAI Summarize 任务中,使用的是 6B 参数规模的 RM 和 6B 的生成模型(LM)。
- InstructGPT 用的是 6B 的 RM 配合 175B 的 LM。
- DeepMind 则用 70B 的 RM 对应 70B 的 LM。
总体来说,直觉上“判分”任务比“生成”任务简单,因此可以用略小一些的模型作为 RM,这样计算成本更低,训练和部署也更高效。但实际选择还是要根据具体应用和资源来权衡。
4. 强化学习(Reinforcement Learning, PPO)
在我们拥有了训练好的 Reward Model(RM)后,就可以用 RM 进一步优化和进化我们的生成模型。目前常用的优化方式主要有三种:BON(Best-of-N)、DPO(Direct Preference Optimization)、PPO(Proximal Policy Optimization)。
4.1 Best-of-N(BON)
BON 也叫 reject sampling,其基本思路是:
- 通过设定一定的 temperature(温度参数),让同一个模型针对同一个 prompt 生成 N 条回复。
- 使用 Reward Model 对这些回复进行打分,挑选得分最高的几个作为“好样本”。
- 再用这些好样本继续训练原模型。
这种方法属于“采样-筛选-再训练”的循环迭代流程。例如 Llama2 论文 就采用了此方法。论文还特别指出,在 SFT 阶段要汇聚所有阶段的好样本一起训练,而不是只用最近一次采样的样本,这有助于提升模型的泛化能力。
BON 与 RL(如 PPO)的主要区别:
- 探索广度:BON 针对同一个 prompt 会采样 N 个答案,而 PPO 每次只采样 1 个。
- 进化深度:BON 通常只进行一次采样-筛选-训练循环,而 PPO 会持续进行采样-优化-采样的多轮循环。当然,BON 也可以反复多轮执行,这时两者的区别会缩小。
下图对比了 OpenAI Paper 中 BON 和 RL 的训练表现:
- 左图(a, BoN):显示不同数据量下,BON 训练时 Reward Model 的分数(RM Score)随着 KL 距离的变化情况。可以看到,数据量越大(颜色越浅),BON 的提升越明显且曲线更平滑。
- 右图(b, RL):展示 RL(如 PPO)训练时的表现,数据量越大,RM 分数提升越快,但曲线相对不如 BON 稳定,容易出现波动甚至崩掉。
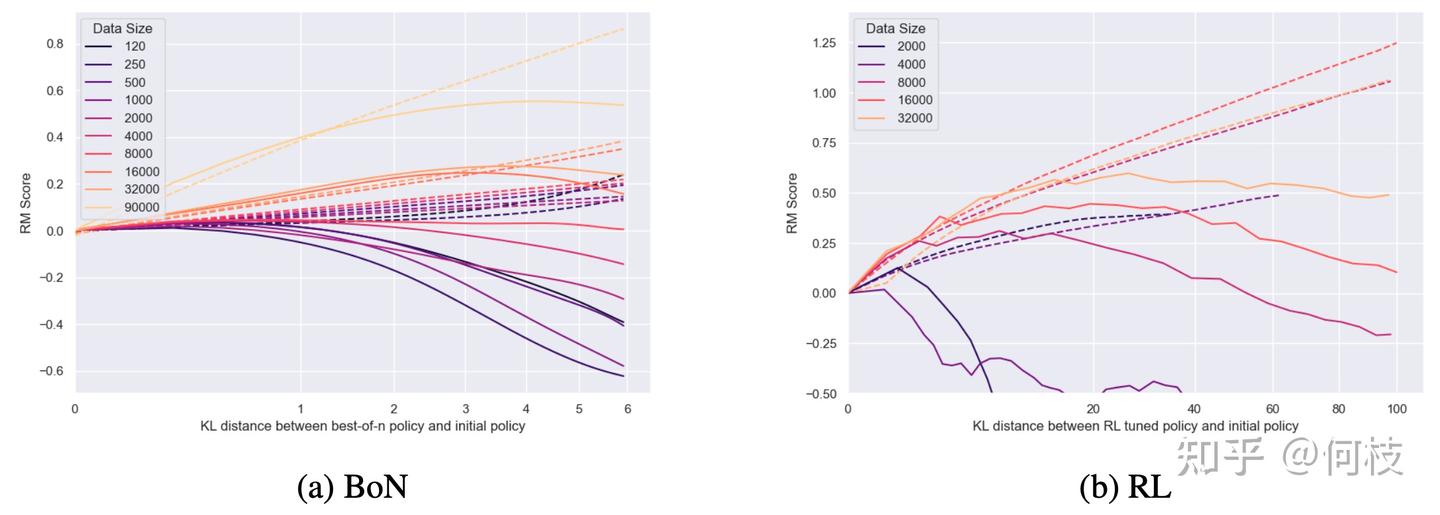
BON 方法训练曲线更稳定、不易崩盘,但 RL 方法最终的 reward 上限会更高。实际工程中可以根据资源和需求灵活选择、甚至组合使用。
4.2 Direct Preference Optimization(DPO)
Direct Preference Optimization (DPO) 是一种不依赖 Reward Model 的训练方法,可以直接利用「偏序对」数据来优化大模型本身。
DPO 借鉴了对比学习的思想,核心目标是:对于同一个 prompt,要让模型尽可能拉大 selected 答案和 rejected 答案之间的生成概率差距。换句话说,DPO 直接优化模型本身,使其更偏向于人类偏好数据,无需训练独立的 RM。
DPO Loss 的核心优化目标:
表示当前 policy(策略)模型。 表示 reference(参考)模型。 是输入(prompt), 是生成的两个候选回复。 表示在人类偏好下 优于 的概率。 是 sigmoid 函数, 是温度系数。
公式来源于 A General Theoretical Paradigm to Understand Learning from Human Preferences,大部分开源实现(如 Huggingface trl)都基于这个思路。
代码实现示例::trl 库中的 DPO loss 实现如下
1 | |
DPO 利用偏序对直接训练大模型,无需单独 Reward Model,训练过程高效、简单,是近年来 RLHF 领域的热门方法之一。
4.3 Proximal Policy Optimization(PPO)
Proximal Policy Optimization (PPO) 是强化学习领域一种经典的基于 Actor-Critic(AC)架构的优化方法,其前身为 TRPO。PPO 通过引入重要性采样(Importance Sampling),解决了 on-policy 策略采样数据利用率低、更新次数受限等问题,从而提升了训练效率和速度。
在大语言模型(LLM)训练场景中,PPO 的完整实现需要同时加载 4 个模型:
- Actor Model: 用于生成并进化的主力模型
- Critic Model: 对 Actor 的输出进行评判、打分
- Ref Model(Reference Model): 参照模型,通过 KL 散度限制 Actor 的训练方向,避免模型“跑偏”
- Reward Model: 用于为 Actor 输出提供奖励信号,指导其优化方向
为了节省显存和计算资源,通常会让 Actor 与 Critic 共享同一个 backbone,这样只需同时加载 3 个模型。这也是 RLHF 训练“非常吃显卡”的核心原因之一。PPO 在训练 LLM 时,效果和收敛过程都可能很不稳定。
下面常常会通过具体案例来说明和分析这种训练不稳定性。
4.3 Proximal Policy Optimization(PPO)
PPO 是强化学习中一种基于 Actor-Critic 架构的优化方法,其前身是 TRPO(Trust Region Policy Optimization)。PPO 通过引入重要性采样(Importance Sampling),解决了 on-policy 方法“一次采样只能更新一次模型”的低效率问题,大幅提升了数据利用率和模型训练速度。
在大语言模型(LLM)训练中,用 PPO 通常需要同时加载 4 个模型:
- Actor Model:参与训练进化的主生成模型。
- Critic Model:为 Actor 生成内容打分,评判优劣。
- Ref Model:参考模型,用于计算 KL 散度,限制 Actor 的训练方向。
- Reward Model:奖励模型,为训练过程提供进化方向的奖励信号。
为了节省显存,实际工程中经常将 Actor 和 Critic 共享一个 backbone,这样只需同时载入 3 个模型。这也是 RLHF(基于人类反馈的强化学习)对显存和计算资源要求极高的主要原因之一。
工程特点和挑战:
- 训练过程和效果容易不稳定,对超参数、采样和模型设计非常敏感;
- 对硬件资源要求极高,显存消耗大、训练慢;
- 但 PPO 具备极强的策略优化能力,能不断探索并提升生成模型的“人类偏好”表现。
PPO 以其「训练过程不稳定」和「效果不稳定」著称,这里我们通过列出一些具体的 case 来说明。
1. 训练过程不稳定
-
PPO 训练过程中经常出现不稳定现象,尤其是 reward(奖励)曲线剧烈波动。例如,下图中蓝色折线是 actor 的 reward 曲线,粉红色是 ref_model(不参与训练)的 reward 曲线。可以看到,actor 的奖励曲线抖动非常明显。
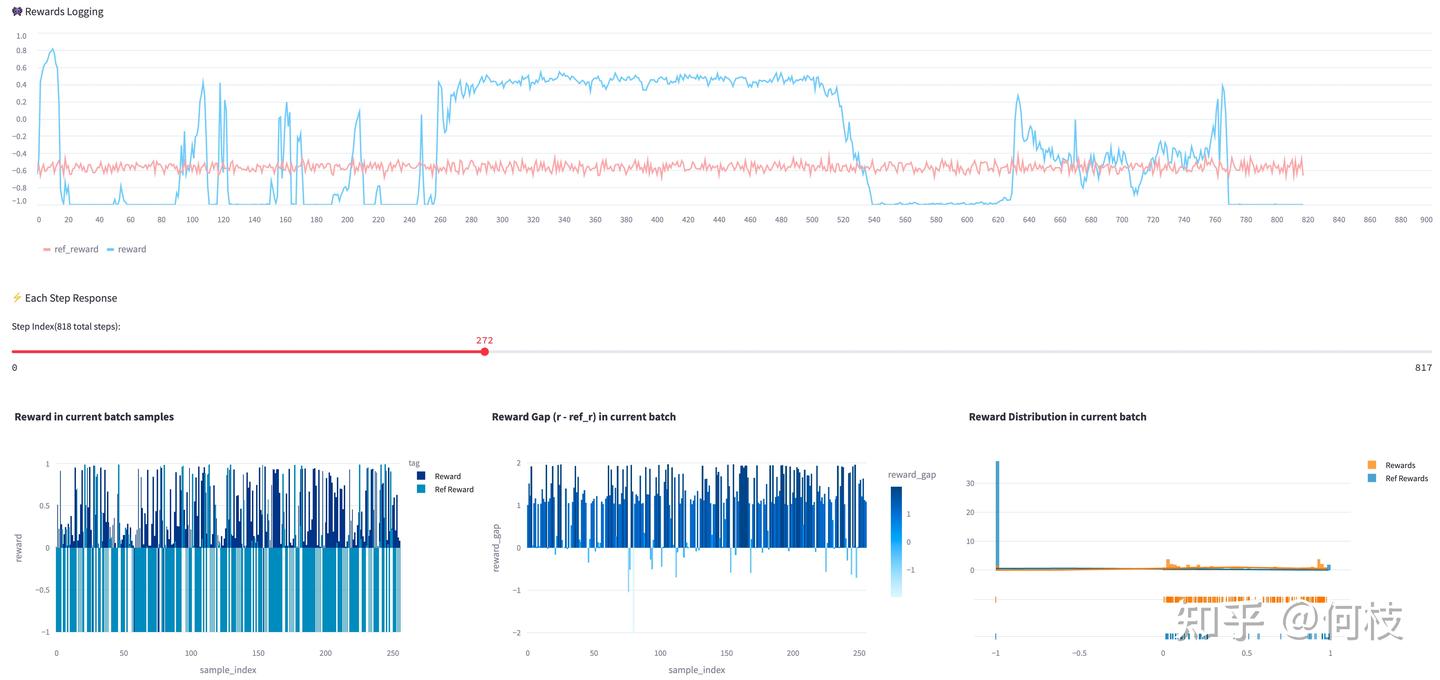
-
经过实验,发现影响 PPO 训练稳定性的几个关键因素:
- KL Penalty:适当调高 KL 惩罚项有助于抑制训练过程中的“发散”,动态调整 KL 系数会更稳妥。
- Reward Model(RM):选择一个更稳定、训练充分的 RM 能显著缓解 reward 抖动问题。
- Reward Scaling:对 reward 进行归一化(scaling/normalization)能提升训练稳定性,避免极端值影响训练。
- Batch Size:适当增大 batch size,有助于缓冲训练噪声,提高曲线平滑度和收敛速度。
-
PPO 对超参数极度敏感。为获得稳定训练过程,需要在 KL、reward scaling、RM 质量和 batch size 上多做实验和调优。
2. 训练结果不稳定
- 即使你在训练过程中看到了平稳且漂亮的 Reward 曲线,也别高兴太早——reward 的提升不一定代表模型真正变得更好。
- 例如:
- 下图展示了一条看起来很理想的训练 reward 曲线(右下角橙色为当前模型的 reward 分布,高分区域占比很大):
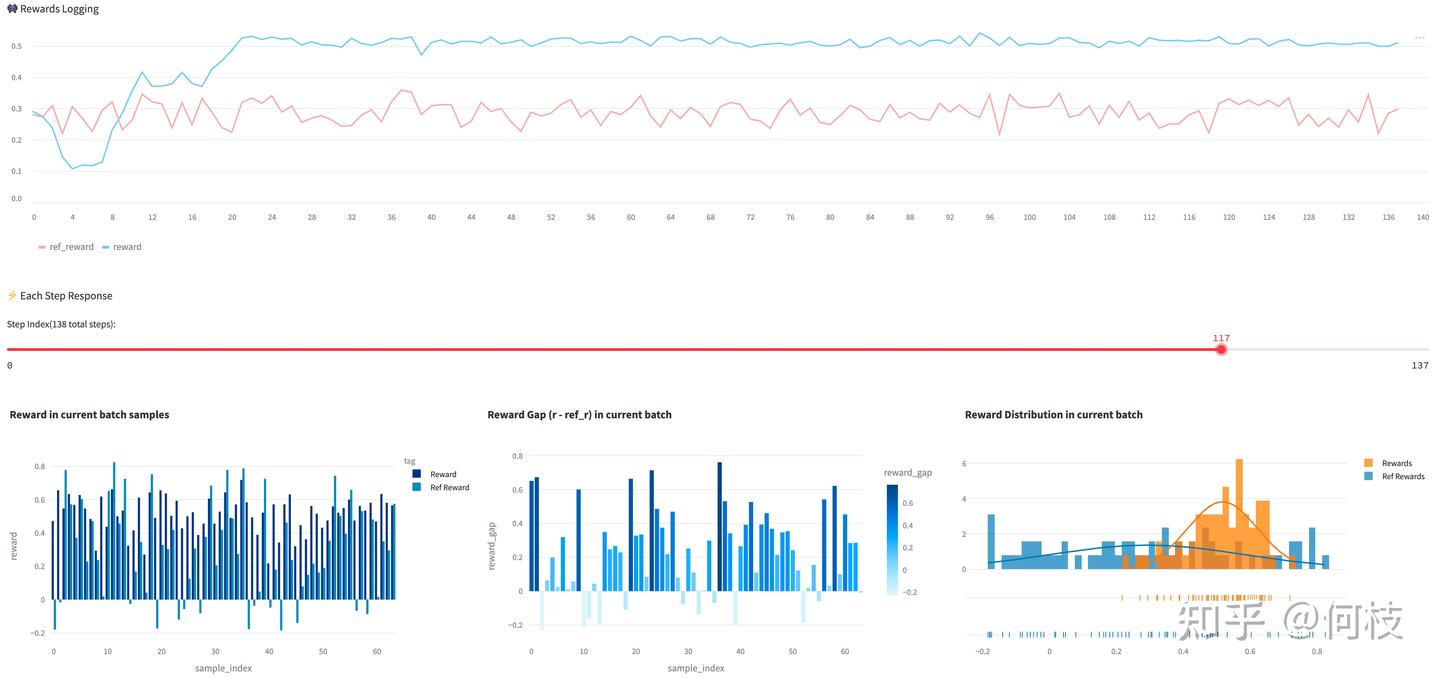
- 但实际上,模型最终生成的内容却是乱码:

- 下图展示了一条看起来很理想的训练 reward 曲线(右下角橙色为当前模型的 reward 分布,高分区域占比很大):
- 这往往是因为 Reward Model(例如情绪识别 RM)错误地对这些“乱码”给出了高分(见上图最后一列 RM 打分),导致模型学会了某种 reward hacking(通过取巧而非真正提升能力来获得高分)。
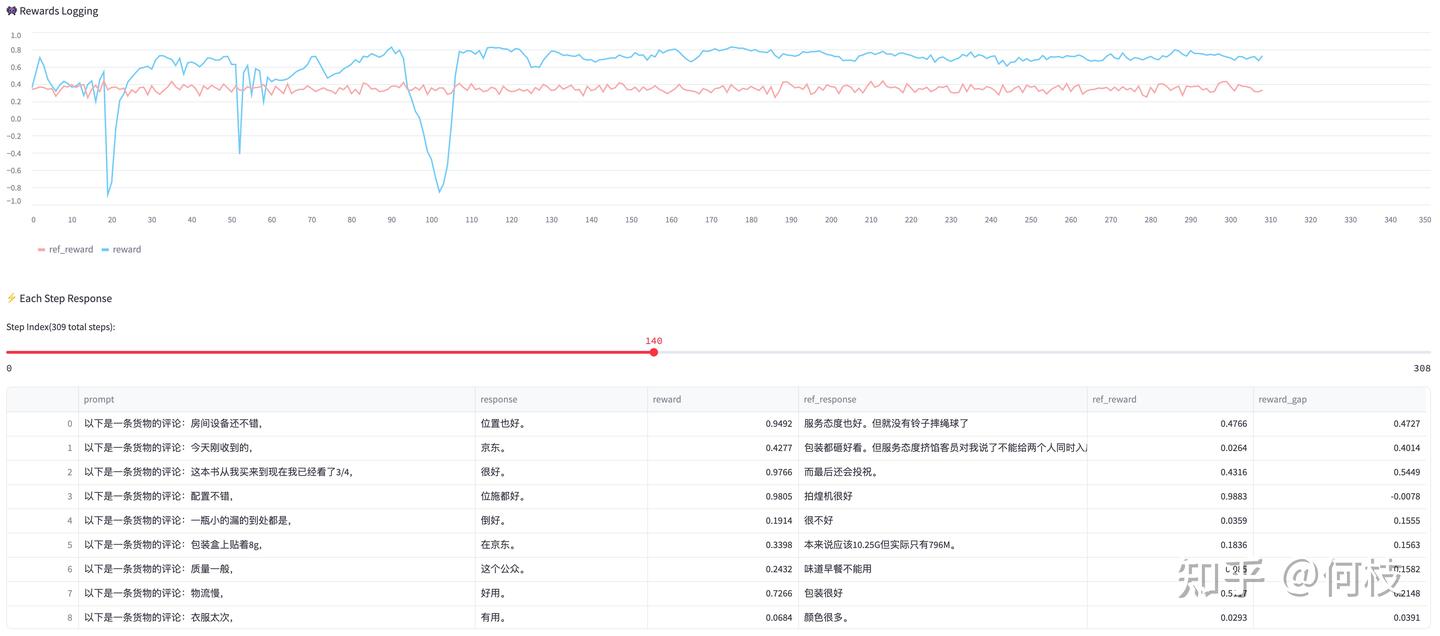
- 应对措施
- 提升 Reward Model 质量是基础。
- 也可以通过组合多个 RM来打分,防止 reward hacking。例如 Llama 2 训练时用 Safety RM + Helpful RM,虽然官方理由是“目标冲突”,但综合多 RM 本身就能降低 reward hacking 风险。
- 通过多 RM 混合策略,最终训练 reward 曲线会更加平稳,模型输出也不会崩掉:
- 关于稳定训练 PPO 的更多技巧和经验,可以参考 Secrets of RLHF in Large Language Models Part I: PPO 论文和相关实战经验总结:

- 推荐阅读:何枝:【RLHF】怎样让 PPO 训练更稳定?早期人类征服 RLHF 的驯化经验
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付