GPT(书)
1. GPT发展历史
- GPT-1 是最早的版本,用了自回归语言建模,在 BooksCorpus 数据上训练,模型小,效果有限,但它首次验证了“预训练+微调”的可行性。
- GPT-2 模型更大了(从一亿到十五亿参数),训练数据也更多,首次展示了“只用预训练、不需要微调”也能完成很多任务,叫做 Zero-shot learning,震惊了整个 NLP 社区。
- GPT-3 是爆火的版本,参数到了 一千七百五十亿,彻底实现了 few-shot 和 zero-shot 能力,并且通过 prompt 设计可以完成翻译、问答、代码生成等一堆任务。
- GPT-4 更强大,加入了图像输入能力(多模态),推理能力更强,行为更稳定,还能进行工具调用、多轮对话、考试解题等等。
-
受计算机视觉领域ImageNet启发,NLP领域开始采用大规模预训练+微调范式,提升模型表达力与泛化能力。
-
ELMo 开启动态词向量预训练,GPT 和 BERT(基于Transformer)则彻底推动NLP进入“预训练微调”新时代。
-
利用丰富无监督/自监督数据+Transformer结构,模型学到通用的词汇、语法和语义表示,下游任务微调时无需针对每个任务细致设计结构,仅需“微调”即可获得显著性能提升。
-
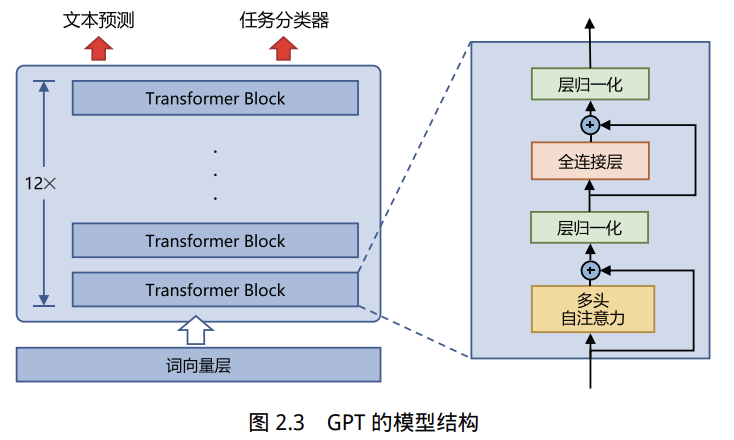
OpenAI于2018年提出生成式预训练语言模型(GPT,Generative Pre-Training),是典型的单向自回归预训练语言模型,由多层Transformer堆叠组成。
-
主要包括输入层、编码层(多层Transformer)、输出层。
2.自监督预训练
-
自监督机制
- GPT采用生成式自监督预训练(语言建模),即只根据已知历史生成下一个token,单向预测(只能从左到右/右到左,不能双向)
- Transformer的结构和解码策略保证了每个输入位置只能依赖过去时刻的信息。
-
输入序列的嵌入
- 给定词序列
,GPT首先为每个输入词 提供其对应的嵌入 ,计算公式如下: - 词向量
,表示词 的语义信息。 - 位置向量
,表示词 在句子中的位置(即输入序列的位置编码)。
- 词向量
- 给定词序列
-
Transformer编码
- Transformer块的处理:每个输入嵌入经过多层Transformer块进行处理,公式为:
- 第
层的隐藏表示 ,序列长度 ,模型维度 ,模型总层数 。
- 第
- 多层Transformer 使得模型逐层提取输入的深层特征,能够更好地捕捉序列中的长期依赖。
- Transformer块的处理:每个输入嵌入经过多层Transformer块进行处理,公式为:
-
输出与条件概率建模
- 预测输出:在Transformer的最后一层,GPT使用输出
来预测每个位置的下一个词的条件概率: 是词表的嵌入矩阵, 是输出偏置, 是最终的隐藏层表示。 - Softmax:将模型的输出转换为每个词的概率分布,表示当前词在所有可能词表中的概率。
- 预测输出:在Transformer的最后一层,GPT使用输出
-
训练目标函数
- 最大化似然估计:模型训练时的目标是通过最大化每个词的条件概率来优化模型,最终目标是最大化整个序列的生成概率:
- 模型参数
,损失函数是每个词的负对数似然。 - 训练时采用梯度下降法进行优化,模型根据数据学习预测每个词的概率。
- 模型参数
- 最大化似然估计:模型训练时的目标是通过最大化每个词的条件概率来优化模型,最终目标是最大化整个序列的生成概率:
3. 有监督下游任务微调
-
下游任务微调的目标与步骤
- 目标:使GPT模型在特定的下游任务(如分类、回归等)中,通过微调,学习任务特定的特征和标准。
- 步骤:
- 通过自监督预训练(如语言建模)获得通用的语言表示能力。
- 在下游任务微调过程中,模型会根据下游任务的标注数据调整模型参数。
-
微调过程
- 输入数据:输入的文本序列为
,每个输入文本都被标注。 - GPT模型:将标注文本输入GPT,获取最后一层输出
。 - 预测过程:通过Softmax函数对每个词的条件概率进行计算,得到模型的预测结果:
:用于输出的权重矩阵。 - Softmax:将输出转换为概率分布,用于分类任务中的标签预测。
- 输入数据:输入的文本序列为
-
目标函数
- 下游任务的目标函数:通过最大化每个词的条件概率来优化模型,公式如下:
为训练数据集, 为输入文本和目标标签的对应对。
- 下游任务的目标函数:通过最大化每个词的条件概率来优化模型,公式如下:
-
微调损失与正则化
- 在微调过程中,通常会采用正则化方法(如权重衰减)来避免模型的过拟合,防止灾难性遗忘问题。
- 灾难性遗忘(Catastrophic Forgetting):微调过程中,模型可能会忘记预训练时学习的通用特征。
- 为了避免灾难性遗忘,可以在微调损失函数中添加正则化项(
): 是正则化系数,控制微调损失与预训练损失的平衡。
- 为了避免灾难性遗忘,可以在微调损失函数中添加正则化项(
4. 总结
- 微调目标:在保持通用语言能力的基础上,通过调整模型参数,让模型适应特定的下游任务(例如分类、回归)。
- 预训练与微调的关系:预训练模型提供了基础的语言理解能力,微调则是根据下游任务的标注数据进一步优化模型,使其能专注于任务的细节。
- 正则化与灾难性遗忘:为了避免微调过程中遗忘预训练所学到的知识,需要在损失函数中引入正则化项。
参考资料
- 《大语言模型:从理论到实践(第二版)》-- 张奇、桂韬、郑锐、黄萱菁
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
GPT(书)
http://neurowave.tech/2025/04/25/2-6-LLM-GPT/