LLaMa(书)
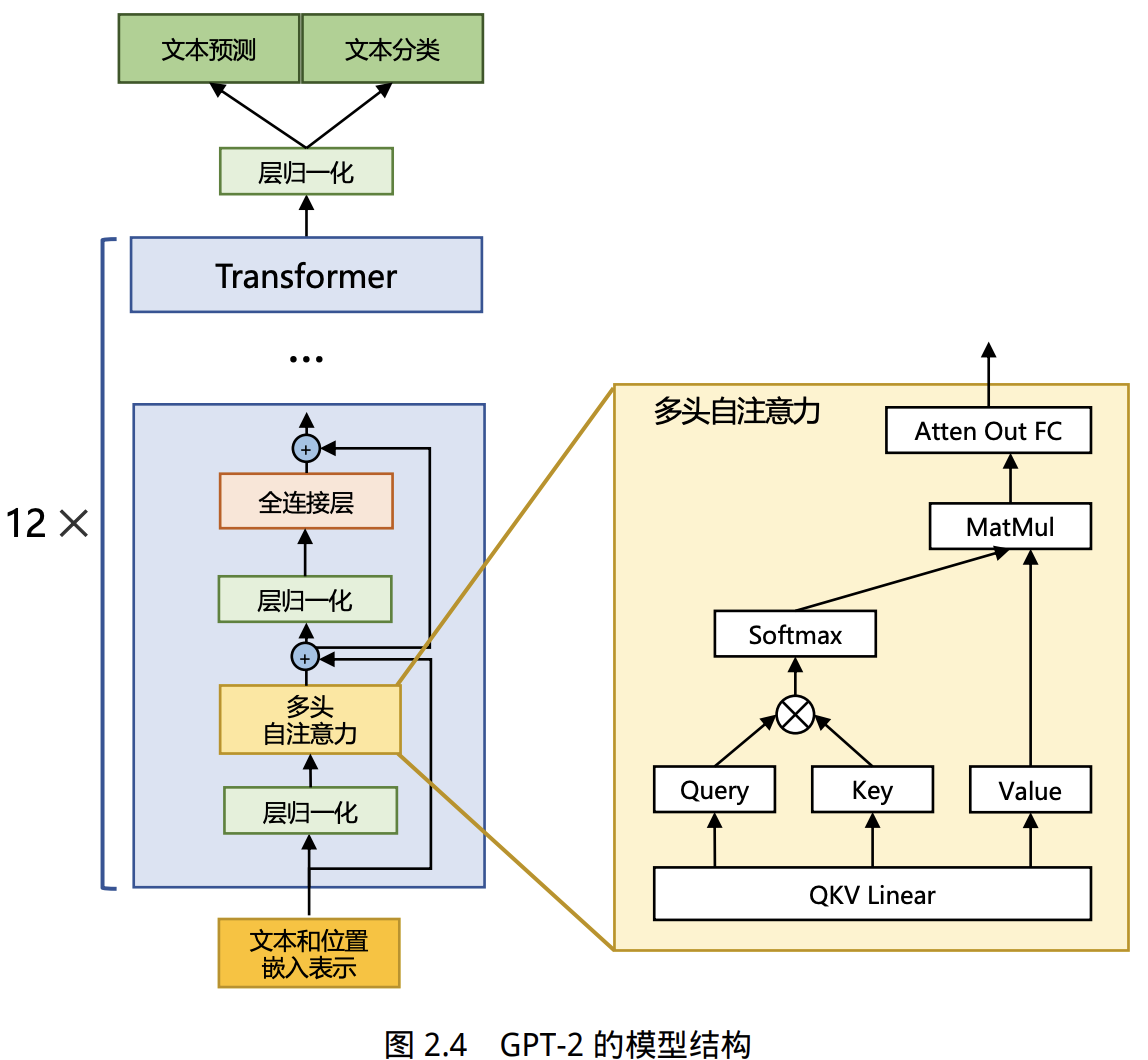
- 绝大多数大语言模型采用类似GPT的自回归Transformer解码器架构,各模型在位置编码、归一化、激活函数等细节有所不同。
- GPT-3未开源,社区有OPT等开源复现;MetaAI基于GPT-3架构开源了LLaMA,效果优秀。
- OpenAI的GPT-3后续模型未再开源。后续结构分析主要参考LLaMA。
LLaMA采用的Transformer结构与GPT-2类似,主要改进有:
- 前置层归一化(Pre-normalization),使用RMSNorm归一化函数
- 激活函数换为SwiGLU
- 采用旋转位置嵌入(RoPE)
1. RMSNorm归一化函数
- RMSNorm归一化函数(Root Mean Square Layer Normalization)常用于如LLaMA、GPT-2的前置归一化(pre-norm)结构。
- 与LayerNorm区别:RMSNorm不做均值减法,仅按方差归一化。
RMSNorm计算公式
对于输入向量
-
1. 计算均方根(Root Mean Square, RMS):
-
2. 归一化每个分量:
-
3. 可学习仿射变换:
其中
为可学习的缩放因子, 为可学习的偏置(常用 为向量, 可选)。
2. SwiGLU 激活函数
-
SwiGLU 激活函数的提出者及应用:Shazeer 提出,在 PaLM 等模型中广泛应用,取得不错效果。
-
与 ReLU 的对比:相比 ReLU,SwiGLU 在大部分评测中提升明显。
-
在 LLaMA 中的使用方式:全连接层采用 SwiGLU 激活函数,具体公式如下:
- 其中
为 Sigmoid 函数
- 其中
-
Swish 激活函数
参数影响 - 当
时,Swish 接近线性函数 - 当
时,Swish 接近 ReLU - 当
时,Swish 光滑且非单调
- 当
-
工程实现:HuggingFace 的 transformers 库用 SiLU 代替 Swish
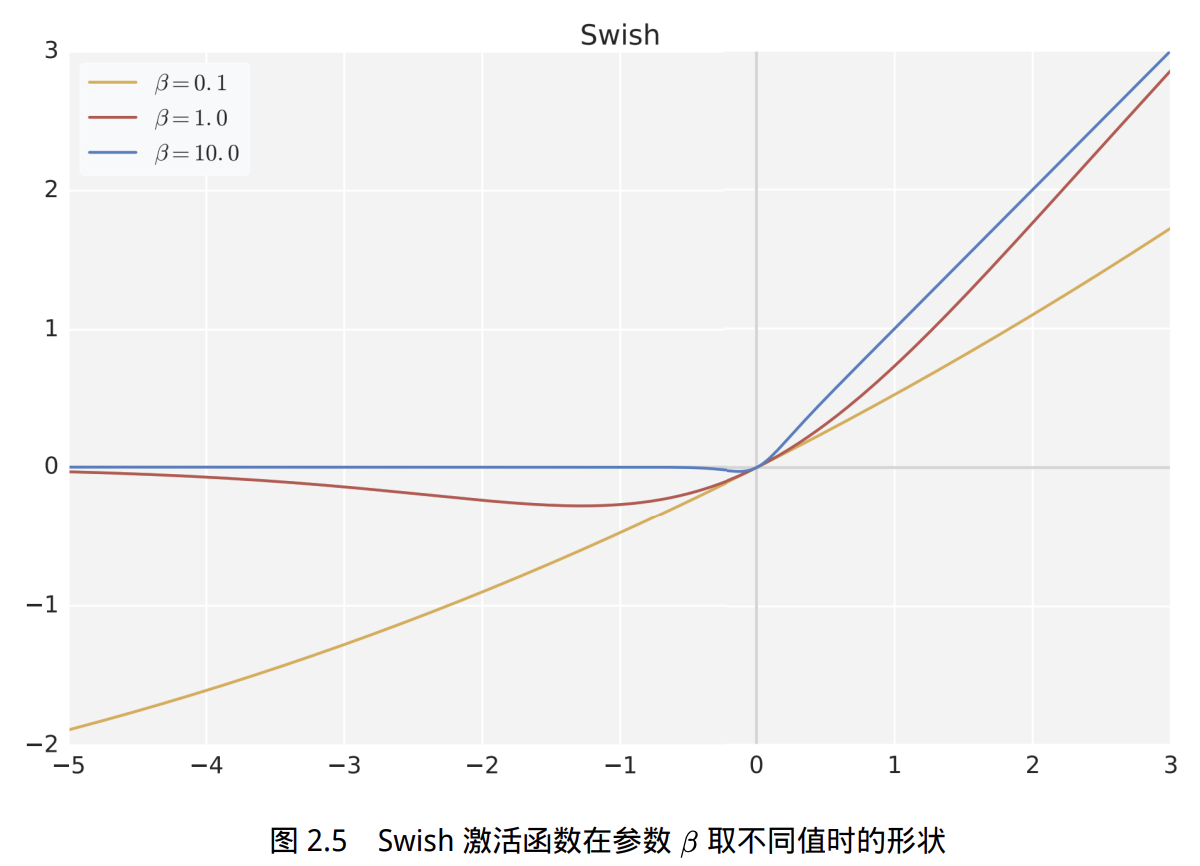
- 曲线对比了
、 、 三种情况。 越小(如 ,黄色),曲线越接近一条斜直线,即接近 ,表现为线性函数。 (红色)时,曲线介于线性和ReLU之间,光滑但非单调。 很大(如 ,蓝色),曲线在 时和 很接近, 时趋于零,形状接近 ReLU 激活函数。
3. RoPE(Rotary Position Embedding)
-
基本思想:用旋转式位置嵌入(RoPE)代替绝对位置编码。RoPE 利用复数的几何意义,实现相对位置编码。
-
基本形式
通过函数对查询 、键 添加绝对位置信息: -
复数表示的 RoPE:这个变换几何上等价于对向量进行旋转。
-
二维矩阵形式
-
高维拼接形式:任意偶数维的 RoPE 可表示为多个二维旋转块的拼接:
-
高效计算:由于
是多个 2×2 块的对角拼接,具备稀疏性,可用按位乘( )操作进一步提升计算速度。
参考资料
- 《大语言模型:从理论到实践(第二版)》-- 张奇、桂韬、郑锐、黄萱菁
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
LLaMa(书)
http://neurowave.tech/2025/04/26/2-7-LLM-LLaMa/