注意力机制优化(书)
-
背景与意义
- Transformer 结构中,自注意力机制的时间和存储复杂度与序列长度呈平方关系,占用大量计算和内存资源。
- 优化自注意力机制的时空复杂度、提升计算效率是大语言模型的重要问题。
- 优化方法包括稀疏近似、低秩近似等,同时也有硬件相关的高效计算方法。
-
稀疏注意力机制(Sparse Attention)
- 发现很多注意力矩阵元素是稀疏的,可以通过限制 Query-Key 对 数量来降低计算复杂度。
- 稀疏化方法:分为基于位置和基于内容两类。
1. 稀疏注意力机制
-
基于位置的稀疏注意力机制的五种类型
- 全局注意力(Global Attention):引入一些全局节点,增强建模长距离依赖关系的能力。
- 带状注意力(Band Attention):大部分数据带有局部性,限制 Query 只与邻近节点交互。
- 膨胀注意力(Dilated Attention):类似 CNN 的 Dilated Conv,通过增加感受野获取更多信息。
- 随机注意力(Random Attention):通过随机采样,提升非局部的交互能力。
- 局部块注意力(Block Local Attention):多个重叠的块(Block)内进行信息交互。
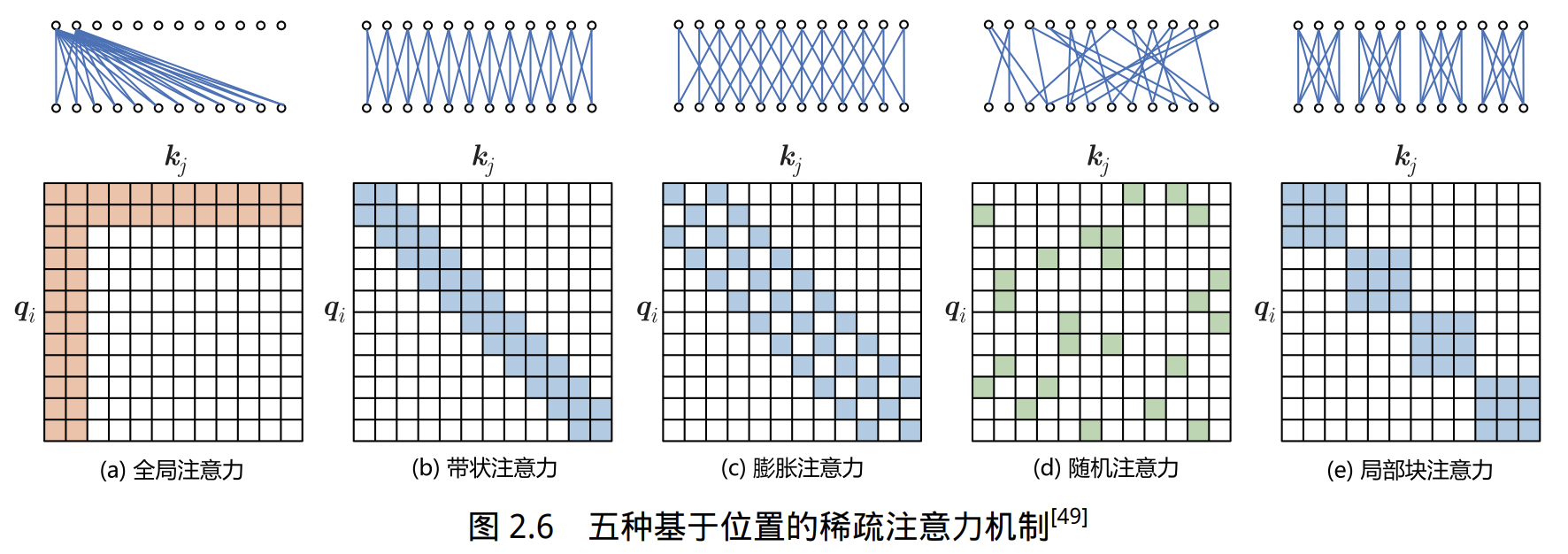
-
稀疏注意力机制的典型模型和组合模式
- 多数稀疏注意力机制为上述类型或其组合:Star-Transformer(带状+全局),Longformer(带状+内部全局),ETC(带状+外部全局)。
- Star-Transformer 仅含一个全局节点和宽度为 3 的带状注意力,任意两个非邻接节点通过全局节点连接,相邻节点直接相连。
- Longformer 使用带状注意力和部分膨胀窗口注意力,并有内部全局节点注意力(Internal Global-node Attention)。
- ETC(Extended Transformer Construction)使用带状注意力和外部全局节点注意力(External Global-node Attention)。
- 稀疏注意力还包含编码机制化输入(如 CPC, Contrastive Predictive Coding)进行预训练。
- BigBird 使用带状注意力、全局注意力和额外的随机注意力,能近似全连接注意力,效果较好。

- 多数稀疏注意力机制为上述类型或其组合:Star-Transformer(带状+全局),Longformer(带状+内部全局),ETC(带状+外部全局)。
-
基于内容的稀疏注意力机制
- 根据输入数据内容为每个 Query 选择高相似度的 Key,从而创建稀疏注意力。
- 代表方法:Routing Transformer 和 Reformer。
-
Routing Transformer
- 使用 K-means 聚类方法,对所有 Query
和 Key 聚类,聚类中心为 ,其中 是中心个数。 - 每个 Query 只与其簇(Cluster)内的 Key 交互,聚类中心用滑动平均更新:
- 其中
表示簇 内向量数量。
- 使用 K-means 聚类方法,对所有 Query
-
Reformer
- 采用局部敏感哈希(Local-Sensitive Hashing, LSH),为每个 Query 选择 Key-Value 对。
- 用 LSH 函数对 Query 和 Key 哈希,分桶处理,提高桶内 Query 与 Key 的交互概率。
- LSH 函数定义如下:
- 其中
为 的随机矩阵。 - 只有当
时, 才与对应 Key-Value 交互。
- 其中
2. FlashAttention
-
NVIDIA GPU 显存类型与结构
- GPU 显存有多种类型,不同类型内存(显存)有不同的速度、大小和访问限制。
- 显存分为六大类:
- 全局内存(Global Memory)
- 本地内存(Local Memory)
- 共享存储(Shared Memory, SRAM)
- 寄存器(Register)
- 常量内存(Constant Memory)
- 纹理内存(Texture Memory)

-
存储物理位置与带宽
- 全局内存、本地内存、共享存储和寄存器具备读写能力。
- 全局内存和本地内存使用高带宽内存(High Bandwidth Memory, HBM),物理上位于板卡 RAM 存储芯片上,容量大但访问速度较慢。
- 共享存储和寄存器位于 GPU 芯片内部,容量小但访问速度快。
-
访问带宽与并发
- 以 NVIDIA H100 为例,全局内存有 80GB,最大带宽 3.35TB/s,但并发线程全部读取时平均带宽依然有限。
- 共享存储和寄存器的访问限于同一个 GPU 线程块(Thread Block)内,线程可并发访问。
- 虽然 NVIDIA H100 每个 GPU 流处理器(SM)可用共享存储容量 228KB,但速度远高于全局内存。
-
传统自注意力计算流程
- 需在 GPU 中引入两个中间矩阵
和 ,并存储到全局内存。具体计算过程为: - 步骤为:从全局内存读取矩阵
和 ,计算 并写回全局内存,再读出 计算 并写回,最后读取 和 计算 。 - 这种流程极大占用带宽,计算速度受限于全局内存访问。
- 需在 GPU 中引入两个中间矩阵
-
FlashAttention 的优化思想
- 利用 GPU 硬件设计,针对全局内存(HBM)和共享存储(SRAM)I/O 速度的不同,尽量避免从 HBM 反复读写注意力矩阵。
- 目标:高效利用 SRAM,加速计算,减少全局内存中读写注意力矩阵。
- 做法:不访问整个输入情况下计算 Softmax,避免在向传播中存储完整注意力矩阵。
- 在标准 Attention 算法中,Softmax 必须在对
做矩阵乘法前,先完成 、 每个分块中一整行的计算。 - FlashAttention 中,将输入分割成块,在每个块内执行多次传递,以分步方式完成 Softmax 计算与
的矩阵乘法。
-
FlashAttention 核心实现思路
- 标准自注意力实现需要将
, 等大中间矩阵写入全局内存,大小与序列长度平方成正比,带来巨大的内存带宽消耗。 - FlashAttention 通过分块传输与块内归一化/Softmax,避免全矩阵读写,仅小块数据在片内 SRAM 与全局 HBM 间流转。
- 分块实现可能会带来 FLOPS 增加,但整体运行更快且显著减少显存使用。
- 标准自注意力实现需要将
-
算法伪代码
:分块大小,受芯片内存 限制。 :分别分块处理,避免整体矩阵读写。 - 主要流程:分块读取
, ,块内对 进行乘法与归一化,再合成 写回。 - 片内只需要保存当前正在计算的块,显著降低内存压力。

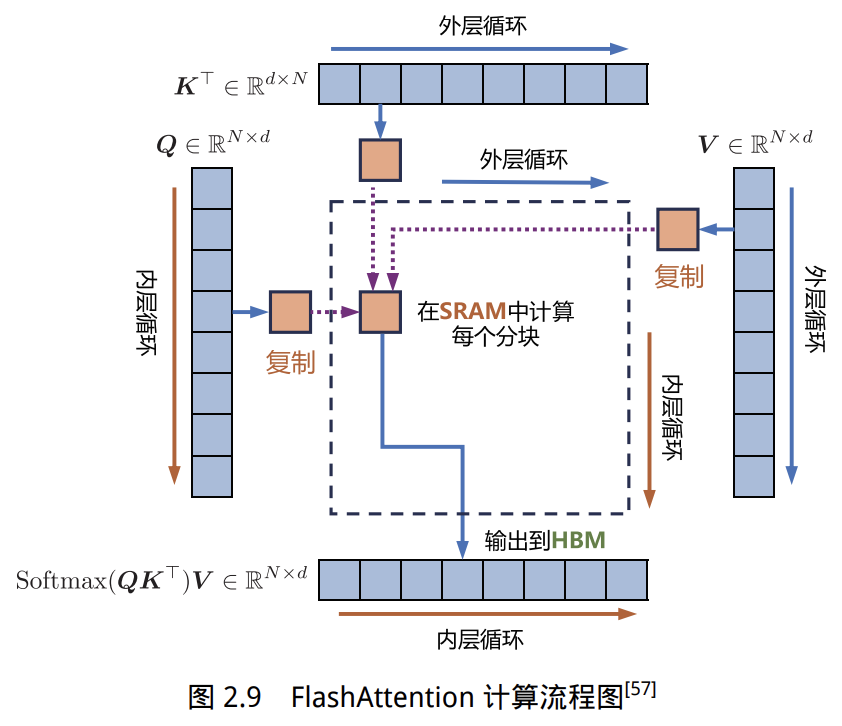
3. 多查询注意力
- 多查询注意力(Multi Query Attention, MQA) 是多头注意力的一种变体。
- 特点:
- 在 MQA 中,不同注意力头共享同一组 Key 和 Value,每个头只独立保留一份 Query 参数。
- Key 和 Value 的矩阵仅有一份,极大减少了显存占用,提高效率。
- 由于结构变化,模型通常需要从训练开始就支持多查询注意力。
- 研究发现,可以通过对已训练好的模型微调来增加多查询注意力支持,仅需约 5% 的原始训练数据就可达到不错效果。
- 目前包括 Falcon、SantaCoder、StarCoder 等很多模型都采用了多查询注意力。
4. 多头潜在注意力
-
多头潜在注意力(Multi-Head Latent Attention, MLA) 是 DeepSeek-V2 引入的注意力优化模型。
-
主要思想:
- 通过在键值层利用低秩矩阵,实现对压缩潜在键值状态的缓存,大幅减少
缓存大小,有效缓解通信瓶颈。 - MLA 方法将传统多头注意力中的 Key 和 Value 进行低秩联合压缩,得到低秩表示,用于
缓存。
- 通过在键值层利用低秩矩阵,实现对压缩潜在键值状态的缓存,大幅减少
-
设
为嵌入维度, 为注意力头数, 为每头维度, 是第 个输入。 -
标准多头注意力(MHA)通过三个矩阵
生成 。 -
MLA 方法对
缓存进行如下压缩: - 其中,
为低秩潜在向量, 为压缩维度; 为下投影矩阵, 分别是上投影矩阵。
- 其中,
-
MLA 推理时只需缓存
,缓存元素极少。 -
可合并到 , 可合并到 ,推理时甚至无需计算完整的 Key、Value。 -
为减少激活内存,还可对 Query 进行低秩压缩:
- 其中,
为查询压缩潜在向量, 为查询压缩维度, 、 为下投影和上投影矩阵。
- 其中,
-
理论上证明了 MLA 方法在表现力上优于组查询注意力(Group Query Attention, GQA)。
-
当 MLA 和 GQA 使用相同大小的
缓存时,MLA 表现出更强的能力。 - 原因:MLA 能展现更大的通道多样性,而 GQA 组内头部输出是复制的,无法捕捉 MLA 能处理的某些情况。
-
提出 TransMLA 后训练方法,能将基于 GQA 的预训练模型(如 LLaMA、Qwen、Mixtral)转换为基于 MLA 的模型。
-
转换后,通过进一步训练,在不增加
缓存大小的前提下,有效提升模型表现力。
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
注意力机制优化(书)
http://neurowave.tech/2025/04/26/2-8-LLM-注意力优化/