8. DeepSeek-V3(V2)详读 1(Abstract + Introduction)
DeepSeek-V3(V2)详读 1 (Abstract + Introduction)
这个文章巨长,内容比较多比较杂,里面涉及 DeepSeek-V3 和 DeepSeek-V2 的内容。会分成好几篇文章来讲解。
Abstract
- 模型名称:DeepSeek-V3
- 模型结构:专家混合模型(Mixture-of-Experts, MoE)
- 参数规模:总参数 671B,每个 token 激活 37B
- 主要技术:
- 多头潜在注意力(Multi-head Latent Attention, MLA)
- DeepSeekMoE 架构
- 无辅助损失的负载均衡策略(auxiliary-loss-free load balancing)
- 多token预测训练目标(multi-token prediction)
- 训练数据量:14.8T 高质量、多样token
- 训练流程:
- 预训练(pre-training)
- 监督微调(supervised fine-tuning)
- 强化学习(reinforcement learning)
- 评测表现:
- 超越其他开源模型
- 性能接近主流闭源模型
- 训练资源消耗:仅需 2.788M H800 GPU小时
- 训练过程:非常稳定,无不可恢复的loss波动,无回滚
- 模型开源地址: https://github.com/deepseek-ai/DeepSeek-V3
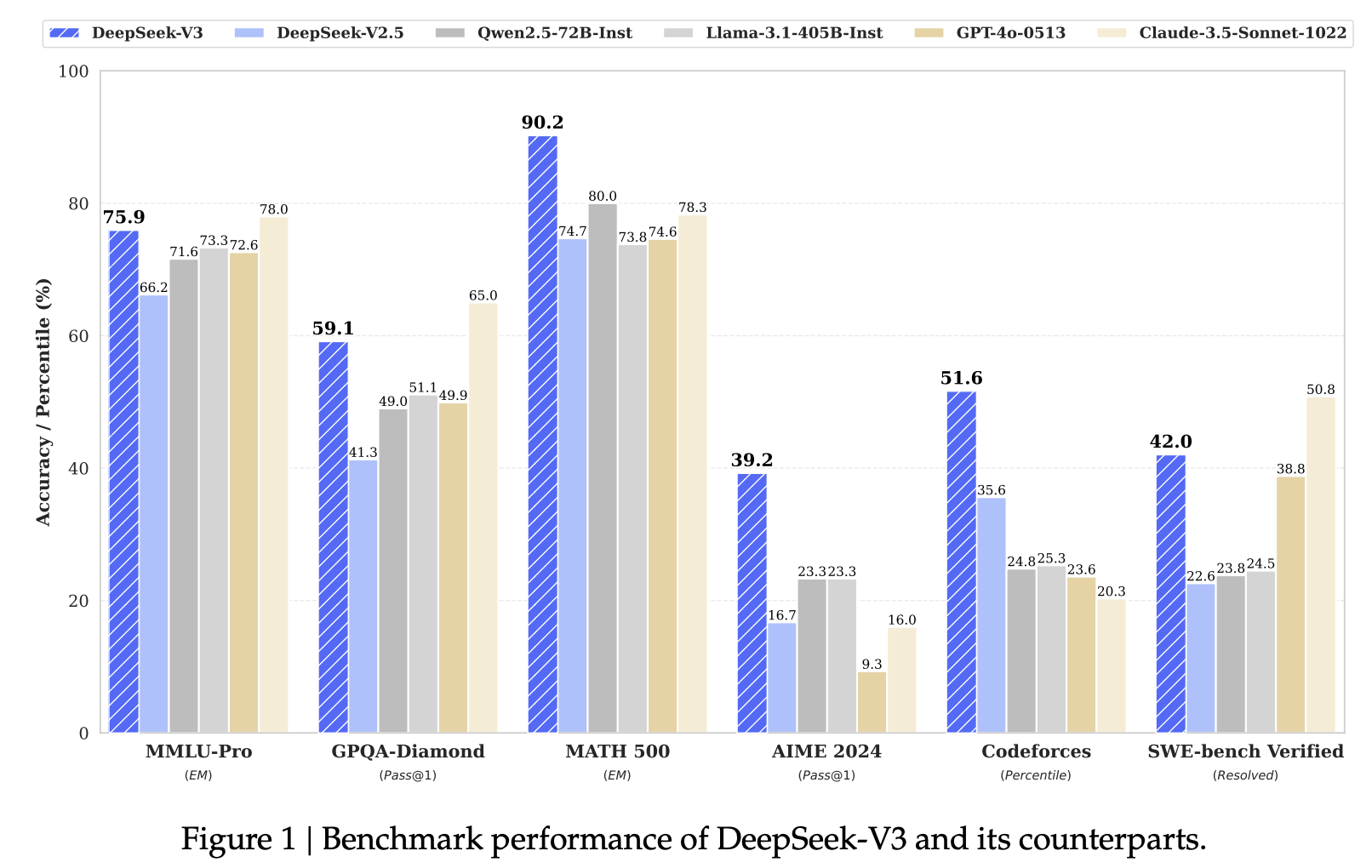
先介绍一下数据集:
- MMLU-Pro:测试模型综合能力的数据集。是一个2024年才推出了的数据集(之前有个版本MMLU),这个数据集有12k个问题,不光需要模型的 knowledge,还需要模型的reasoning,是大家喜欢用的一个数据集来benchmark自己的模型。
- 提升就是将4个options增加到10个options,这样随机猜对的概率就会降低。
- 之前跟多考察模型的knowledge,现在增加一下考察reasoning的问题
- 现在加了很多干扰的选项,让模型猜对的概率降低。
- 可以查看一下domain knowledge,基本生活日常的数据集都涵盖(数学,物理,化学,法律,工程,经济学,健康,心理学,商学,生物,哲学,计算机,历史,其他)
- DeepSeek第一个选用的数据集就是这个
GPQA:测试模型是否能超过人类专家的数据集,性能天花板级别测试。是一个小的数据集,只有448个问题,但这些问题非常非常的难,需要博士生和博士学位的人才能回答的一类问题,而博士生们回答问题的正确率也只有65%。这个数据集是测试language model是否能超过人类专家。可以看到目前GPT-4 based baseline也只能达到39%的准确率。
MATH500:考察模型的推理能力。是一个比较老的数据集,2023年由OpenAI做的一个数据集。通过数学的问题考察模型推理的能力。
AIME 2024:考察模型的推理能力。这是每一年美国数学学会考试的题,所以这个数据集也是衡量模型在推理方面的能力。
Codeforces:代码能力测试。是一个在线的编程比赛的网站,会有很多人类的程序员在这个网站提出一些challenge的问题,大家来解决,拼通过这种方式来比赛。考察编程能力并和人类程序员比较。
SWE-bench Verified:代码能力测试。是OpenAI 2024年8月份发布的,主要来自于Github的issue,会给language model一些代码并告诉模型里面有bug这样类似的问题,让模型解决。
1. 引言(Introduction)
近年来,大型语言模型(LLMs)飞速发展,开源模型如 DeepSeek、LLaMA、Qwen 和 Mistral 等持续追赶闭源水平。DeepSeek-V3 是一款 671B 参数的专家混合(MoE)模型,每个 token 激活 37B 参数,兼顾高性能与低成本。
LLaMa 和 Qwen都 是dense架构,mistral 和 DeepSeek 都是 MoE架构
模型采用多头潜在注意力(MLA)和 DeepSeekMoE 架构,并创新引入无辅助损失的负载均衡和多 token 预测目标,进一步提升性能。训练上支持 FP8 混合精度,采用 DualPipe 算法实现高效流水线并行,优化通信与内存,无需昂贵的张量并行,显著提升训练效率。
- 现在大模型用FP32撑不起来,但FP8 精度有限,会导致训练有稳定性方面的问题。DeepSeek使用 FP8 混合精度,应该有一些 trick来调节。
- DualPipe 是流水线并行的方法,主要是利用多GPU 加速这个training 的过程。
- 他们还会用一些方法改善 cross-node all-to-all communication的问题。现在都会用Nvidia 的GPU,提供的InfiniBand(IB) 和NVlink去增加GPU之间互相通讯的带宽。
- 还对内存的使用进行了优化,避免使用tensor parallelism。tensor parallelism是一个比较简单的并行方法,但是会消耗很多计算资源。
DeepSeek-V3 预训练用 14.8T 高质量、多样化 tokens,过程稳定无重大损失波动。模型通过两阶段扩展上下文长度先到32k 再到128k,随后经 SFT、RL 微调对齐人类偏好,并从 DeepSeek-R1 蒸馏推理能力,实现生成质量与效率的平衡。
- 在pre-traning 阶段,他们没有观察到任何的loss spikes 或 roll back,这是非常了不起的。不光将training的消耗降的很低,还非常的稳定。
- 在post-training阶段,用标准的SFT 和 RL
训练成本表
| 训练成本 | 预训练 | 上下文扩展 | 后训练 | 总计 |
|---|---|---|---|---|
| H800 GPU 小时 | 2664K | 119K | 5K | 2788K |
| 美元(USD) | $5.328M | $0.238M | $0.01M | $5.576M |
表1:DeepSeek-V3 的训练成本,假设 H800 租用价格为 $2/GPU 小时。
DeepSeek-V3 在多项基准测试中表现卓越,尤其在代码和数学任务上,已成为当前最强的开源基础模型。对话版性能也超越其他开源模型,在多个标准和开放测试中接近 GPT-4o、Claude-3.5-Sonnet 等顶级闭源模型。
训练成本极低:每万亿 tokens 仅需 18 万 H800 GPU 小时。预训练仅用时两个月,总计 278.8 万 GPU 小时,约合 557.6 万美元(按每小时 $2 计算),显著优于同类大模型。这得益于算法、框架和硬件的协同优化。注意,成本仅包含正式训练,不含前期研究和实验。
pre-training的成本 5.328M USD 只是 claude 的 十分之一。
架构创新:在 DeepSeek-V2 基础上,DeepSeek-V3 推出无辅助损失的负载均衡策略,显著减少性能损失,并引入多 token 预测(MTP)训练目标,提升模型性能与推理速度。
预训练效率:首次大规模采用 FP8 混合精度训练,配合算法、框架和硬件协同优化,解决跨节点通信瓶颈,实现高效计算与通信重叠,大幅降低训练成本。仅用 266.4 万 GPU 小时完成 14.8 万亿 tokens 预训练,后续训练只需 10 万 GPU 小时。
后训练与知识蒸馏:通过蒸馏 DeepSeek-R1 系列模型的推理能力,显著提升推理表现,并能灵活控制输出风格和长度。
DeepSeek:
- Input price
- Cache hit:就是如果问过的问题,可以不再计算token,直接 retrieve,价格是 $0.014/ 1M tokens
- Cache miss: 对于新问题,价格是$0.14/ 1M tokens
- Output price:$0.28/1M tokens
ChatGPT 4o:
- Input price: $2.5/1M tokens
- Cached ** : $1.25/1M tokens
- Output price: $10/1M tokens
Output 成本相差35倍!
参考资料
- DeepSeek AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv:2405.04434
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437
- Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., & Liu, Y. (2024). A Survey on Mixture of Experts in Large Language Models. arXiv preprint. arXiv:2407.06204
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint. arXiv:2101.03961
- Zhou, Y., Lei, T., Du, H., Huang, L., & Zhao, J. (2024). Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts. arXiv preprint. arXiv:2408.15664v1
- Z. Lu and W. Xia, "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," COS597G Lecture 16, Princeton University, 2022. Online. Available: COS597G Lecture 16
- F. Glacial, A. B. Author2, and C. D. Author3 (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint. arXiv:2404.19737
- Y. Leviathan, M. Kalman, and Y. Matias (2023). Fast Inference from Transformers via Speculative Decoding. arXiv preprint. arXiv:2211.17192
- K. Zhang, J. Zhao, and R. Chen, (2024). KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning. arXiv preprint. Available: arXiv:2408.08146
- Transformers KV Caching Explained: How caching Key and Value states makes transformers faster
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part1 | 开源最强模型 | 性价比之王
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part2 | 开源最强模型 | 性价比之王的核心技术MLA
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part3 | 可能存在的问题
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part4 | 从入门到精通DeepSeek MTP
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付