8. DeepSeek-V3(V2)详读 2(架构 + MLA)
DeepSeek-V3(V2)详读 2 (架构 + MLA)
这个部分是讲 架构 + MLA 的内容,补充了一些在 DeepSeek-V2 的内容,Attention,Multi-head Attention,softmax,KV cache,比较不同注意力变种(MHA, GQA, MQA, MLA)的 KV cache差异,RoPE,Decoupled RoPE。
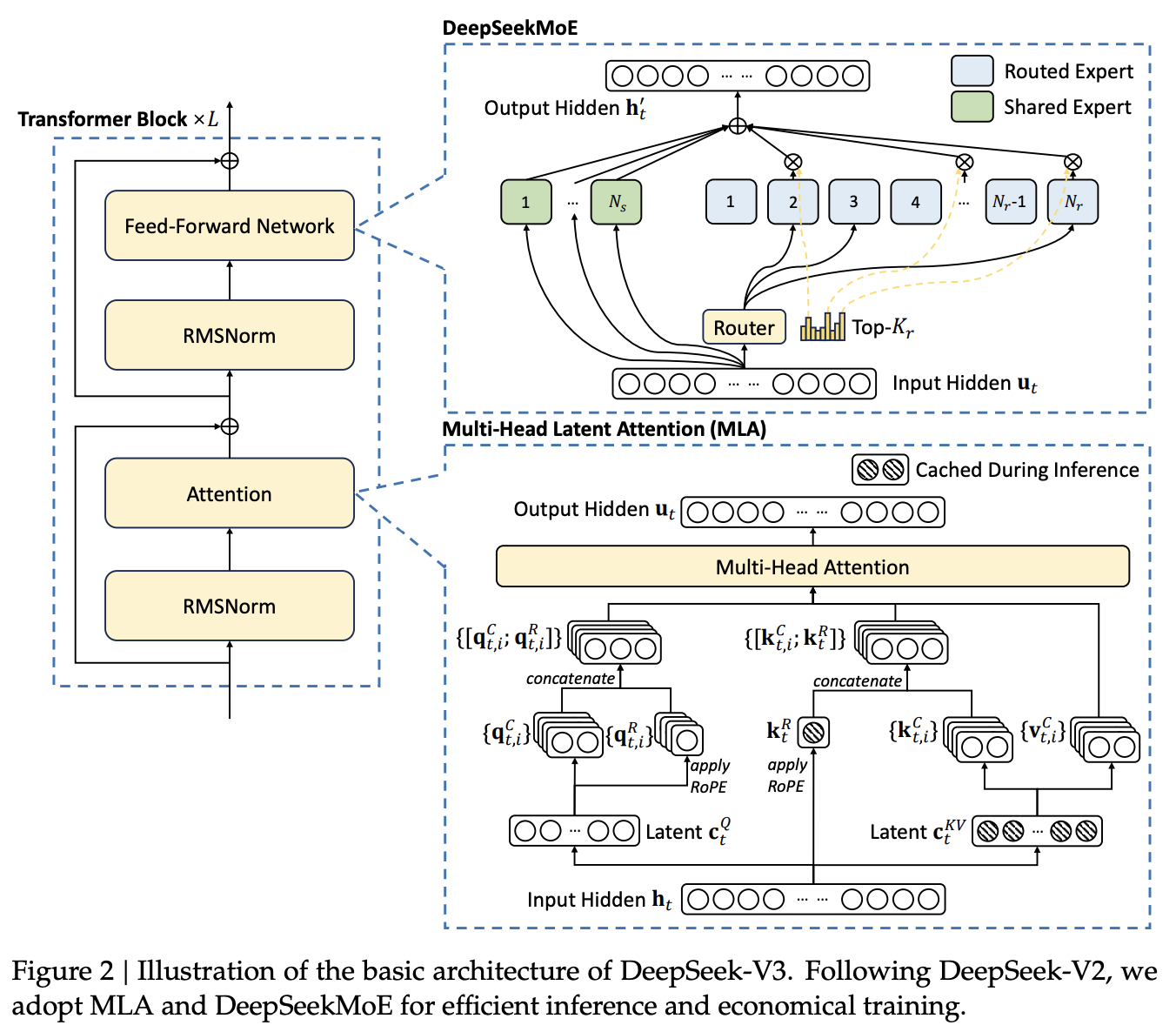
2. 架构
DeepSeek‑V3 采用多头潜在注意力(MLA)提升推理效率,结合 DeepSeekMoE 降低训练成本,并引入多令牌预测(MTP)训练目标,整体性能进一步提升。其余细节基本延续自 V2。
主要讲3个东西
- MLA (多头潜在注意力:在推理方面资源减少)
- DeepSeekMoE (MoE架构:在整个架构上的设计,瞄准在training)
- MTP (多Token预测:增强模型性能)
图2来自DeepSeek-V2,学术上严禁复用,属于学术摽窃,即使是自己的。
图2,DeepSeek主要的改进就是
- Feed forword层:使用MoE 架构
- Attention层:使用MLA 架构。
2.1 基础架构
基础上仍采用 Transformer 框架,同时集成 MLA 和 DeepSeekMoE,实现高效推理与经济训练。新版本还加入无辅助损失的负载均衡策略,减少性能损失。
先补充一些 Deepseek-V2 就提及的内容:
- Attention: Intuitive understanding 可以说是做 Inner Product 来衡量相似度,虽然有时被类比为 correlation,二者数值和含义都不同,只是直觉上都在做“相似度”比较,但数学上不是一回事。
- Multi-head Attention: 把输入向量分割成多个子空间(heads),每个 head 独立计算 attention,再把所有的结果拼接起来,从而让模型可以在不同“子视角”下关注不同的信息,提升表达能力。
- Softmax: 就是做归一化attention scores(即
结果),方便用来加权平均 Value(V),方便在同一个 scale 上面可以做比较。
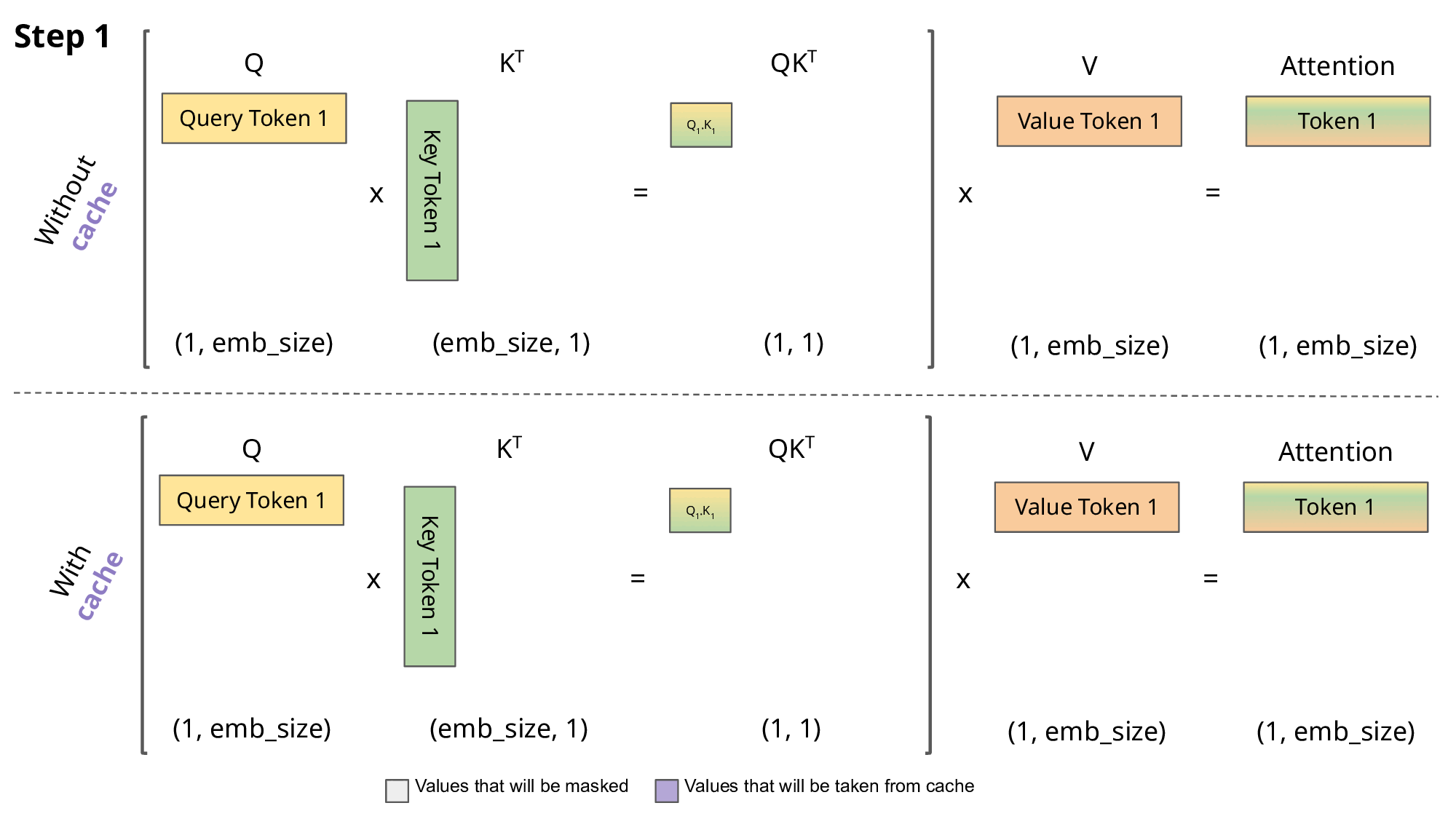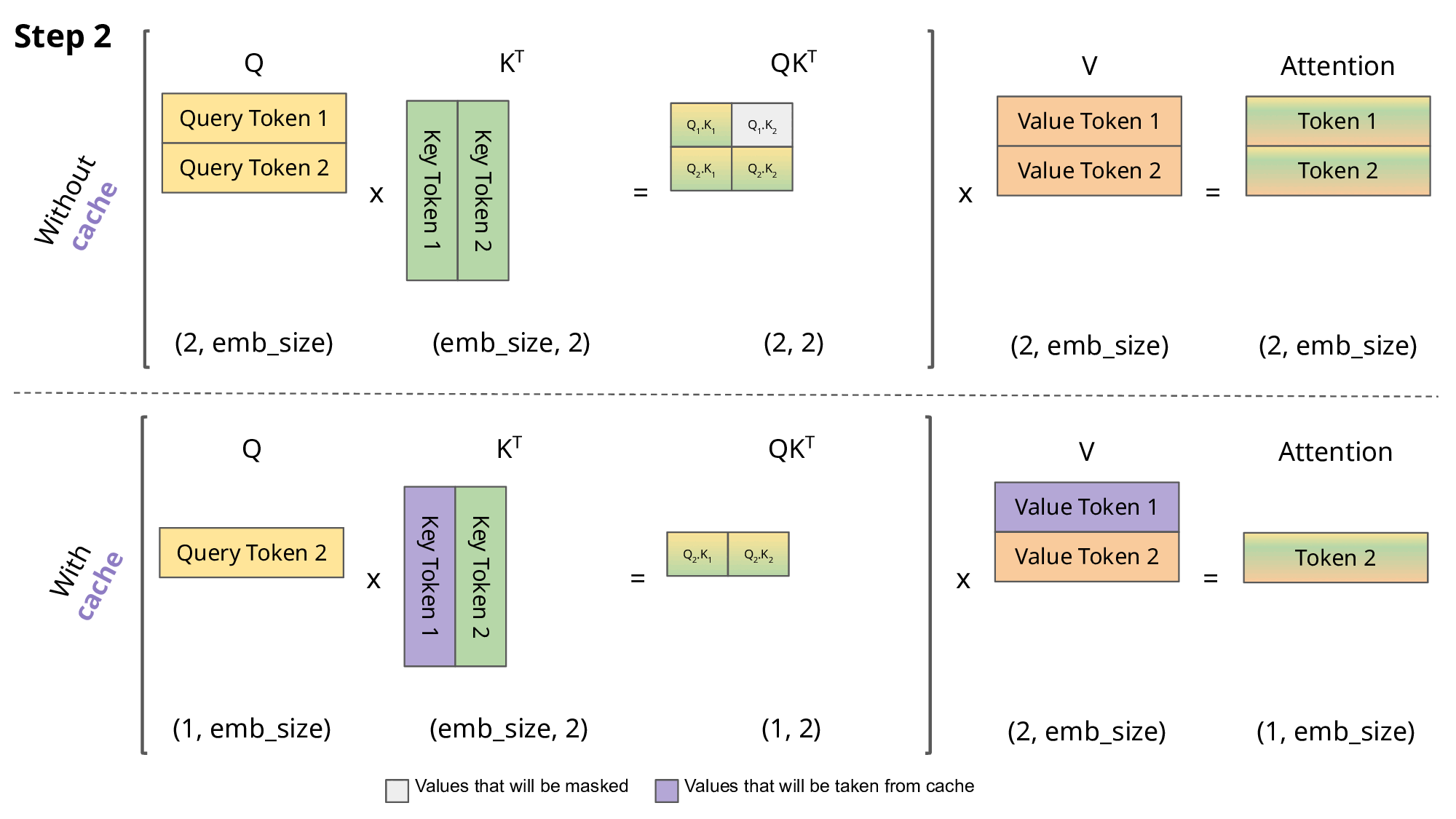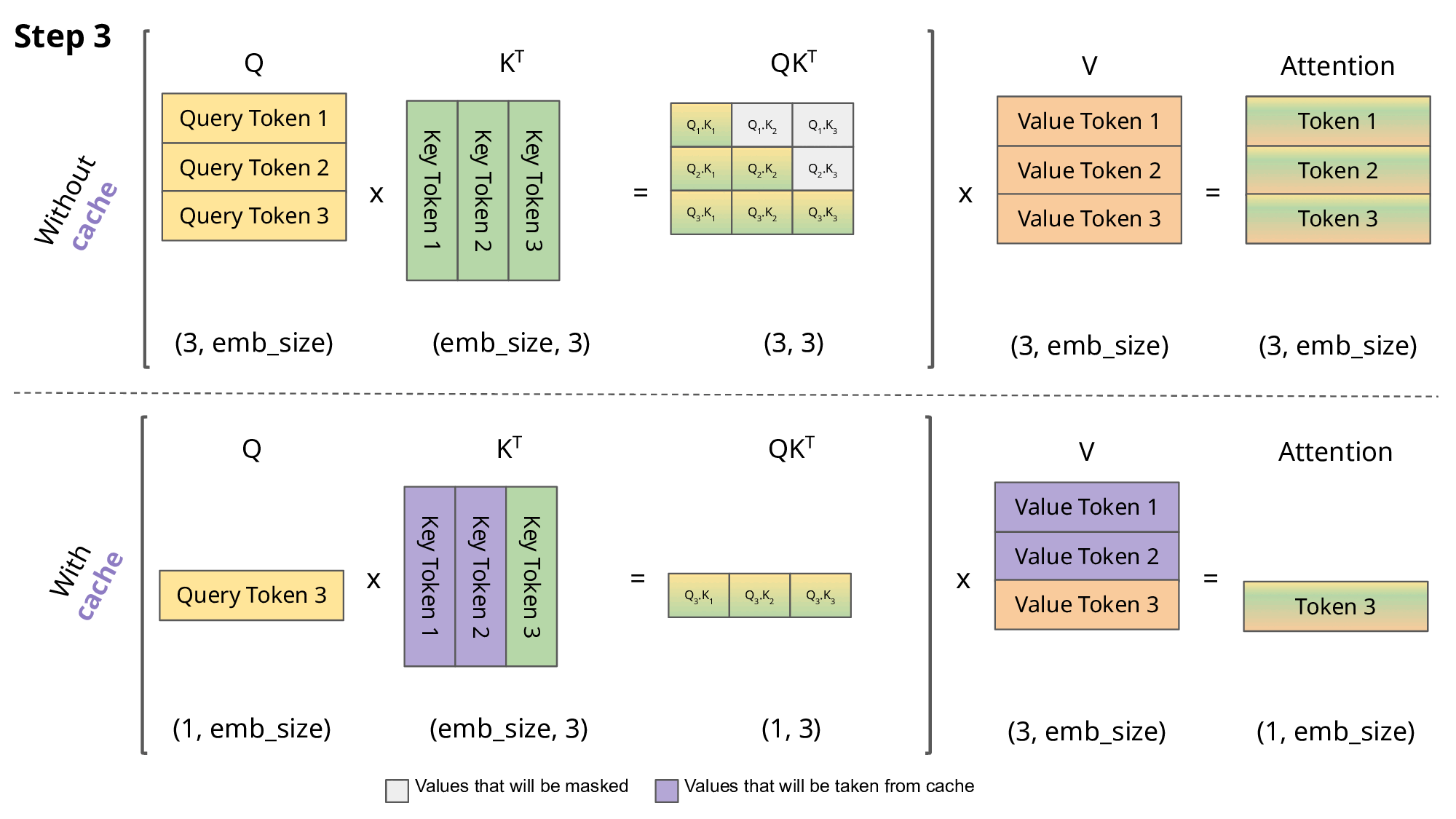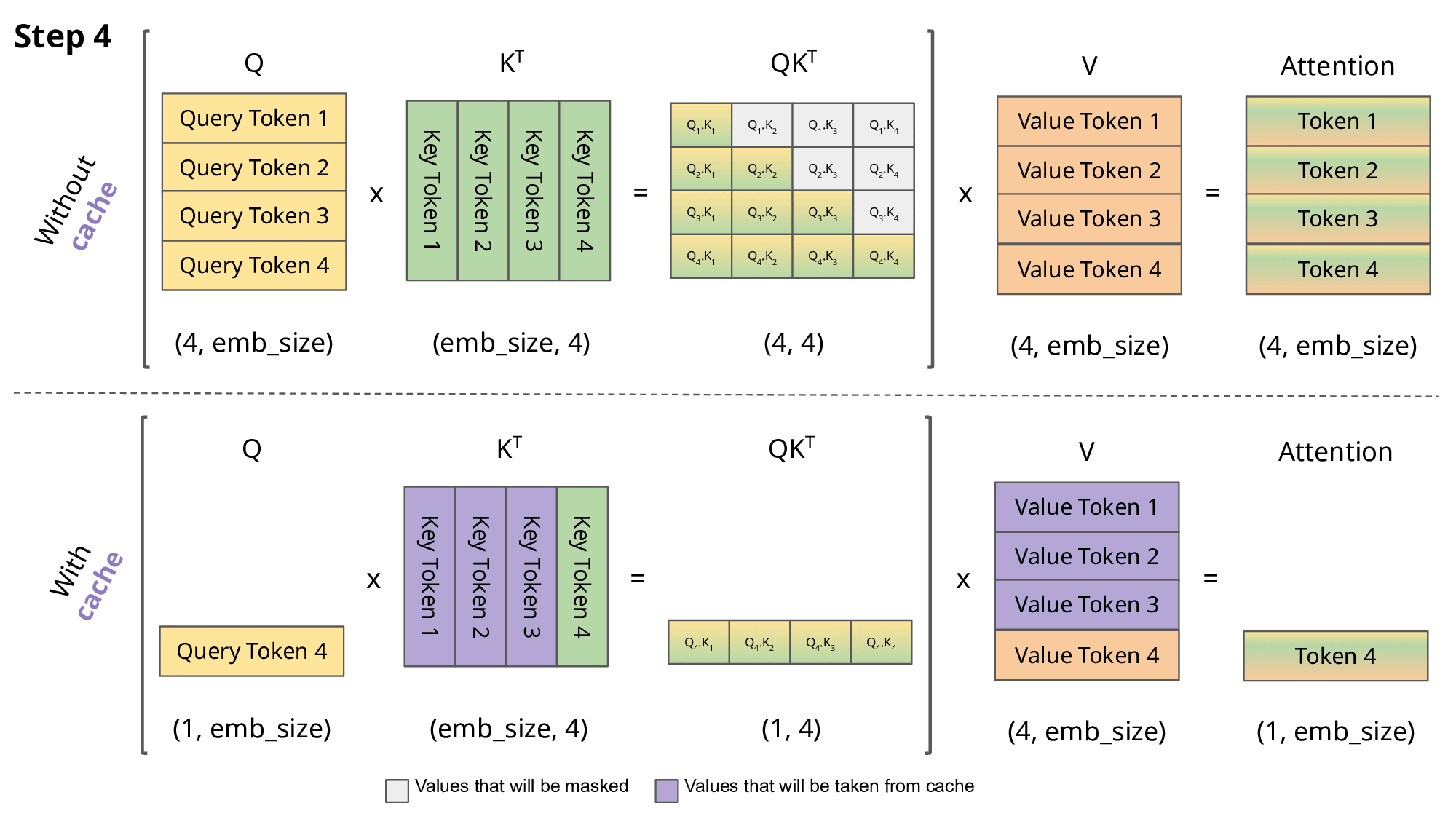
KV cache:
- top-down:GPT 这类 LLM 属于 Decoder-only 架构,是典型的自回归模型。在推理/生成时,每次只生成一个 token,生成 n 个 token 需要迭代 n 次,每次的输入序列都包含之前所有已生成的 token。这种方式每次都要重复计算前面所有 token 的 Key、Value,产生大量冗余计算,而 KV cache 的本质:就是“用空间换时间”,将前面的 K/V 存起来,下次直接复用,提升推理速度。
<s> → 【LLM】 → 欢<s> 欢 → 【LLM】 → 迎<s> 欢 迎 → 【LLM】 → 来没有 KV cache 的情况下(存在冗余):
- LLM每次都完整重新算一遍 self-attention,每步都对历史的K、V重复运算。
- 可以看到,前面的
、 …会被多次重复计算,这就是“冗余”。 - 灰色部分(被 mask)用
填充,softmax 后输出为 0,防止未来 token “偷看”。 - 参考图:
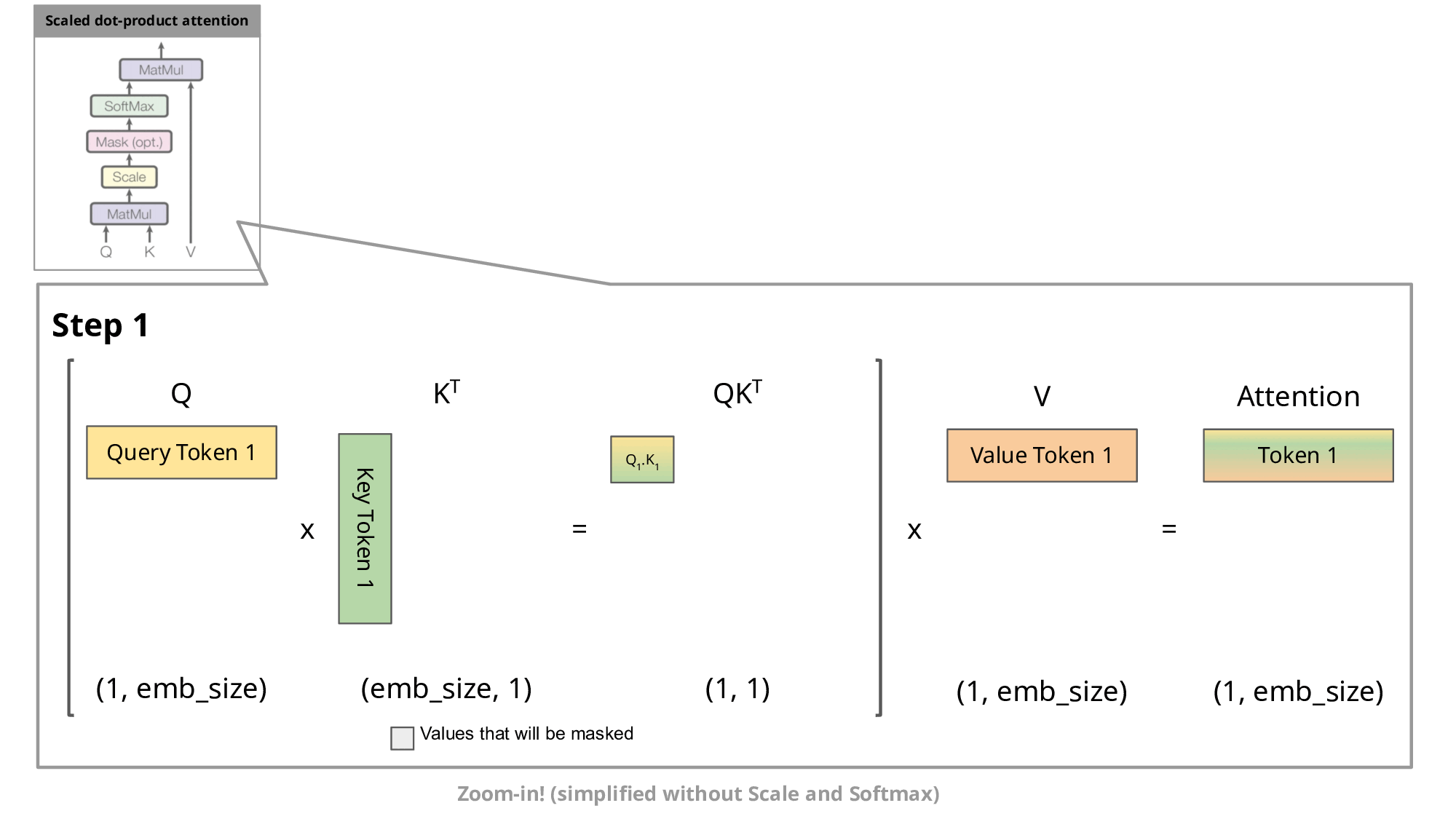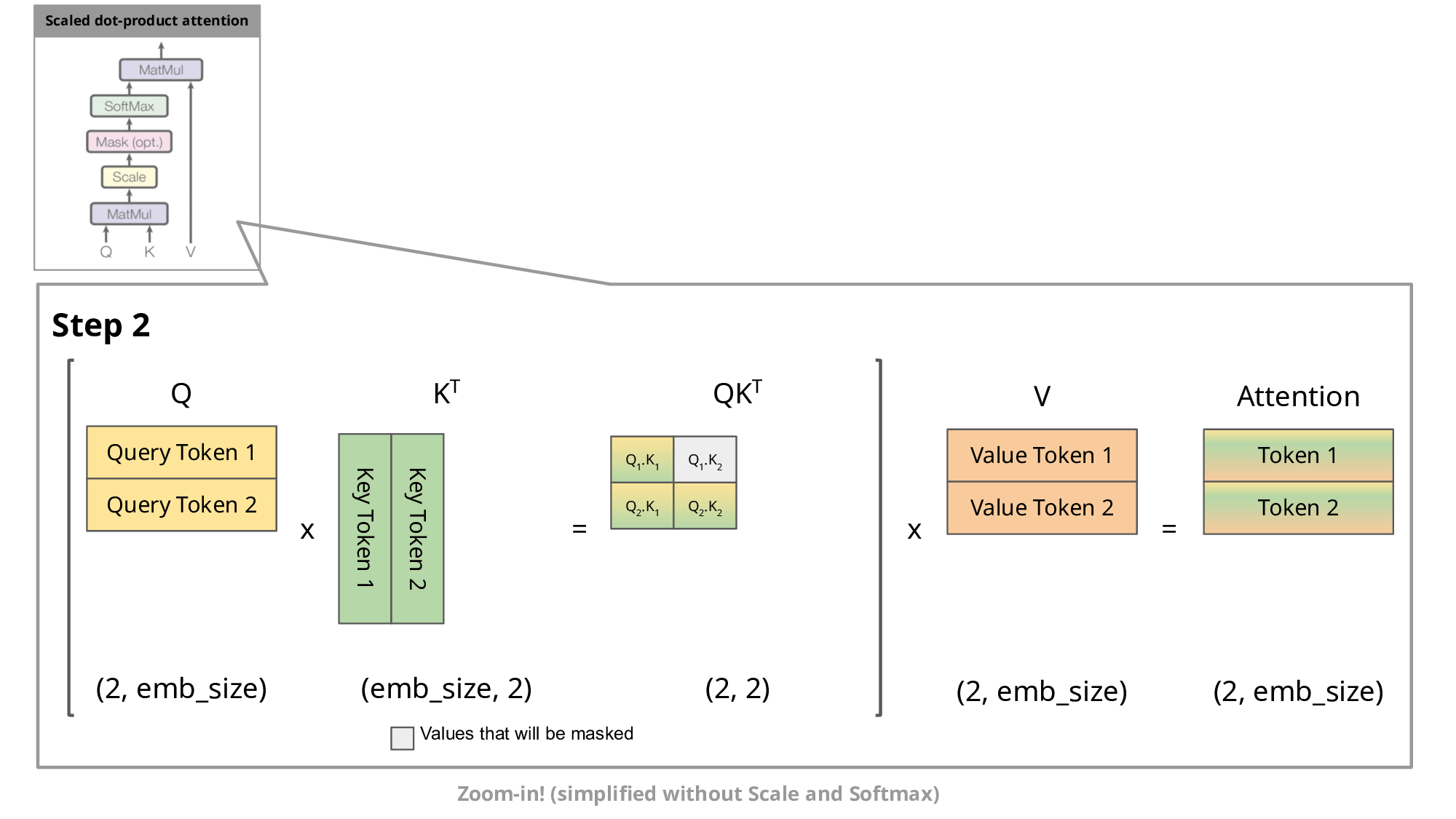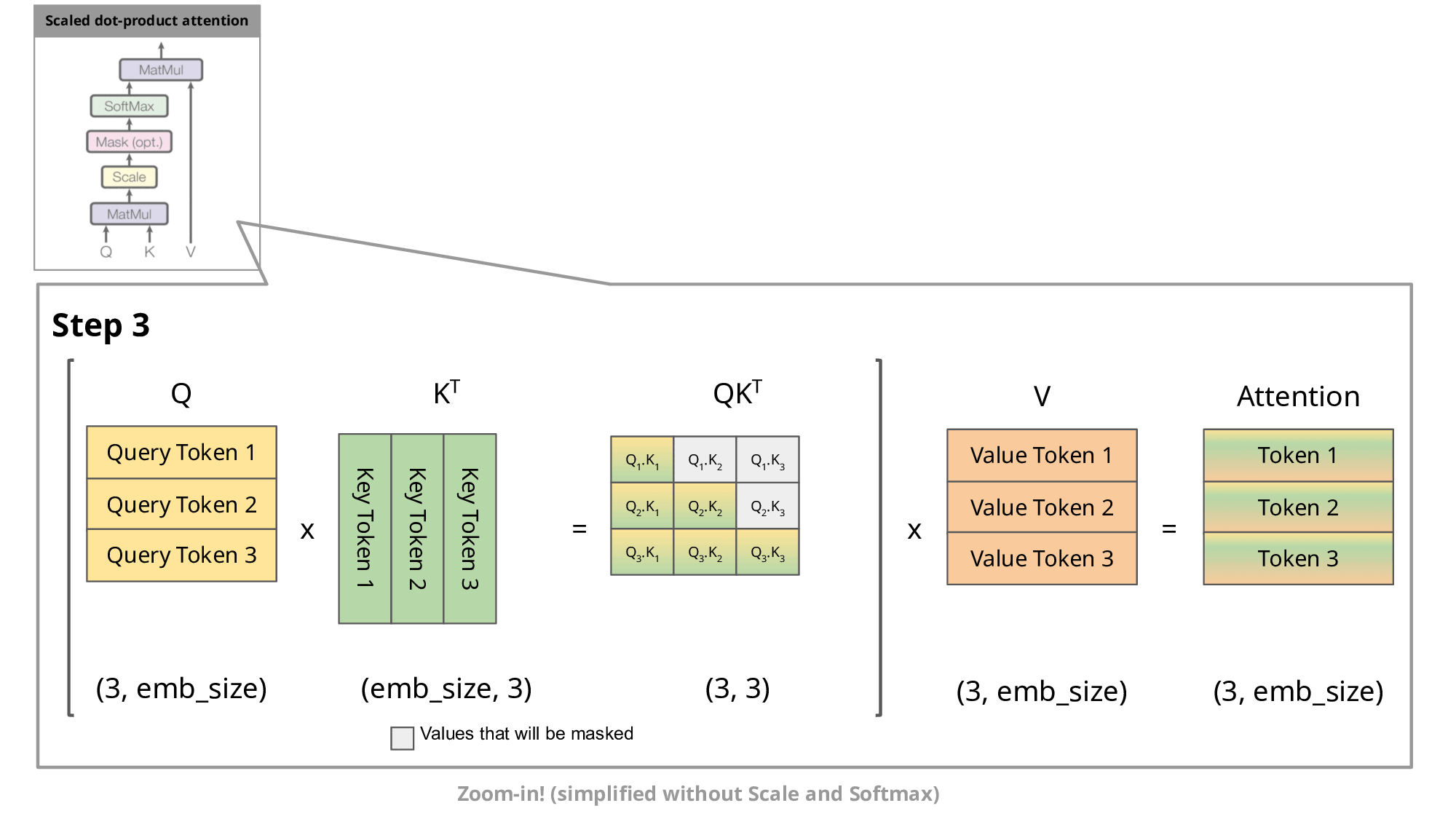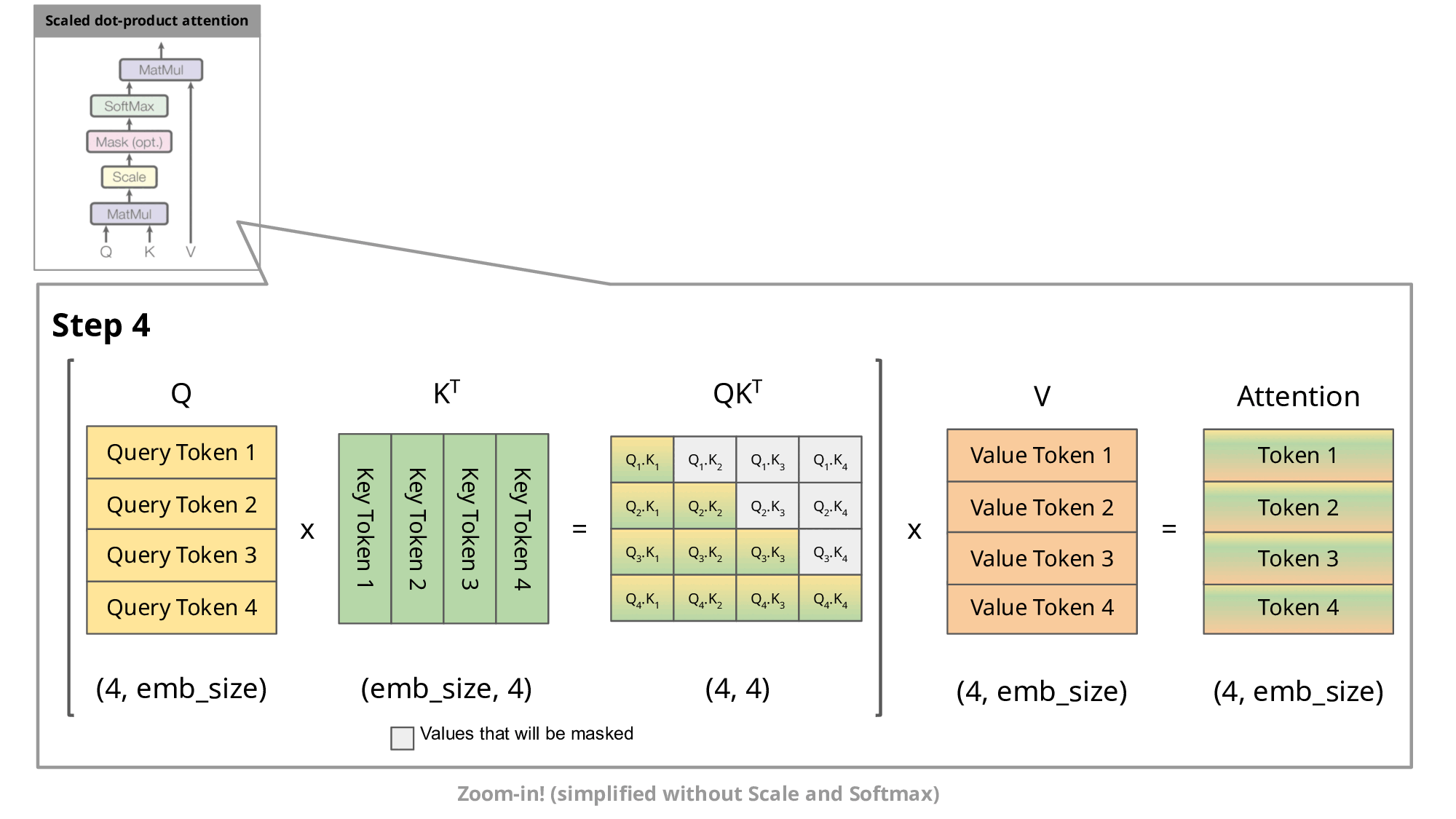
- 有 KV cache 的情况下:
- 只计算当前步的
、 ,其余历史 、 直接从 cache 取,concatenate拼接即可,极大减少重复算力消耗(注意只cache K/V,不cache Q)。 - 对比如下图,紫色部分表示复用 cache:
- 缺点:KV cache 需要存下每步的 K/V,推理到后面序列变长时,对 GPU 显存压力会很大。常用优化有:
- 量化 KV,降低精度以减少存储(如 INT4/INT8 quantization)
- 裁剪、压缩历史 KV(如 Deepseek V2,定期只保留部分 KV)通过减少输入,来减少它cache的数据。
GPT-2代码实现 KV cache 合并(核心片段):
2
3
4
5
6
7
8
9
10# 如果layer_past被缓存过,就提取出来和当前 K,V 合并(按序列长度 dim=-2 拼接)
if layer_past is not None:
past_key, past_value = layer_past
key_states = torch.cat((past_key, key_states), dim=-2)
value_states = torch.cat((past_value, value_states), dim=-2)
# 如果使用了cache就把K,V存一下
if use_cache is True:
present = (key_states,value_states)
else:
present = None
2.1.1 多头潜在注意力(Multi-Head Latent Attention,MLA)
对于注意力机制,DeepSeek-V3 采用了 MLA 架构。设
其中,
是降维投影矩阵; 是 Key 和 Value 的升维矩阵; 用于生成带有旋转位置嵌入(RoPE)的 Key 向量; - RoPE(·) 表示应用 RoPE 矩阵的操作;
表示拼接。
注意:对于 MLA,只需要缓存蓝色框出的
对注意力查询(Query)同样采用低秩压缩,从而减少训练时的激活内存占用:
其中,
最终,注意力的查询(
其中
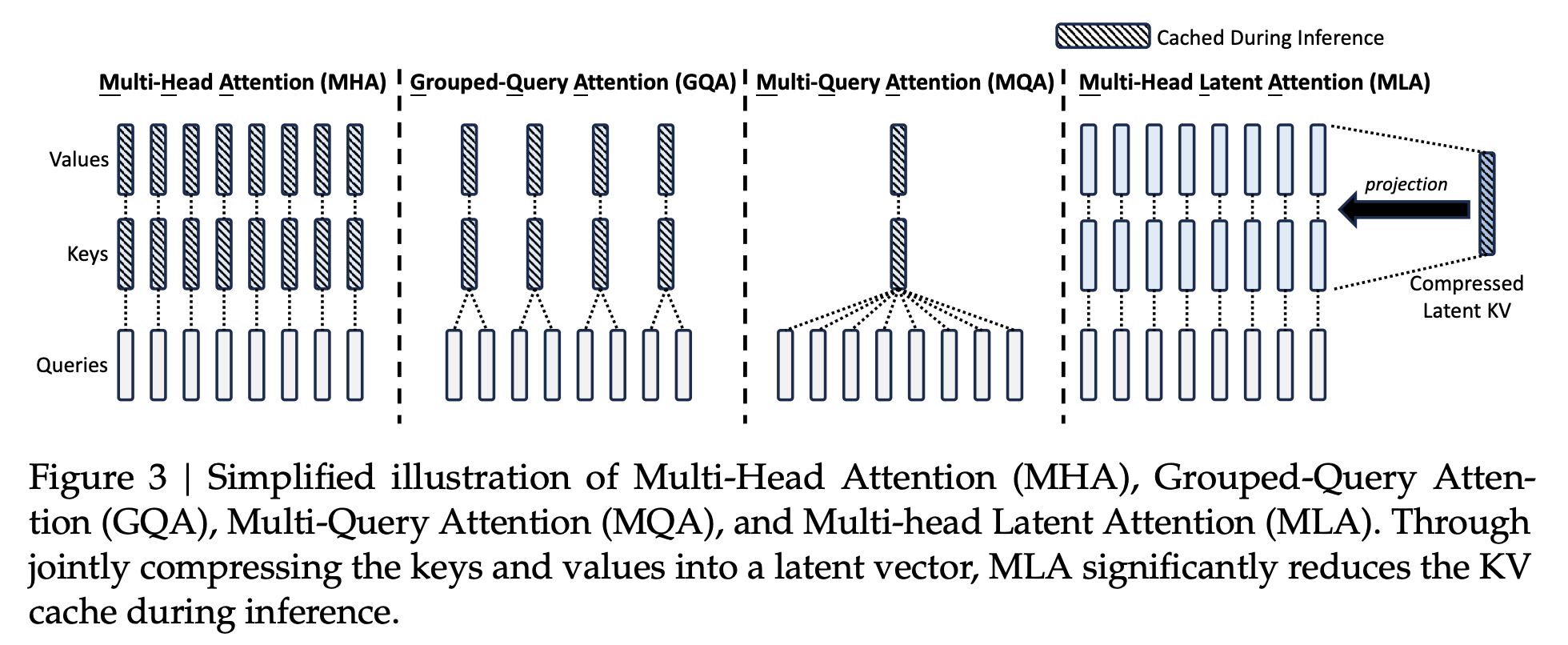
Deepseek-V2 作者比较了不同注意力变种(MHA, GQA, MQA, MLA)的 KV 缓存差异:
- MHA:所有 head 都有独立的 K/V,推理时需要cache全部,显存开销最大。
- GQA:多个 Q head 共享一组 K/V,可减少 cache 大小。
- MQA:所有 Q head 共享同一组 K/V,极端方法 cache 最小化。
- MLA:将所有的 K/V 用线性变换映射到低维 latent space,推理时只需缓存这个 latent 向量
,大幅减少 KV 缓存的存储量。
- 这种结构类似 autoencoder 的 bottle-neck:将高维输入(K/V)压缩到低维 latent 表示,再按需升维还原。
- 类似 stable diffusion、DiT 等大模型中的 latent trick:例如把一个高分辨率图像先 encode 到 latent space,再在低维空间做计算,最后 decode 回原始尺寸,既快又省显存。
KV 的压缩与重建过程,参考式子 (1, 2, 5):
- MLA 的流程如下:
- 首先对输入
进行线性投影降维: - 然后通过升维矩阵
重建出各 head 的 K/V 表示:
- 位置信息通过旋转位置编码(RoPE)动态注入 Key:
- 最终 Key:
- 推理时,只需缓存框出的
和 ,其余部分可以按需即时计算,降低缓存成本。 - 注意:
, 是实际存在的矩阵,用于“延迟计算”,而不是被吸收到其他矩阵或完全省略。
关于缓存优化和计算 trick:
- 传统 attention 要 cache 每个 step 的完整 K/V:
- MLA 中,推理时只需要 cache:
:用于还原出所有 head 的 和 :用于位置信息的旋转编码 - 实际上,K/V 的升维矩阵并没有被省略,而是在解码过程中即时使用(不是预计算好的)
- 进一步优化时的数学 trick:
- 以前 attention 要先重建出
再跟 做点积,现在作者发现可以直接“跳过还原这一步”。 - 推理思路是这样的:
- 这就等于少存一个
,少算一步升维,注意力得分直接用 latent 向量计算,显存和算力都省。 - 类似的 trick 也适用于
。 - 本质是:在数学结构允许的前提下,提前合并多个线性层,跳过中间变量生成,直接上结果。
现在来讲 Decoupled Rotary Position Embedding(RoPE 解耦版)
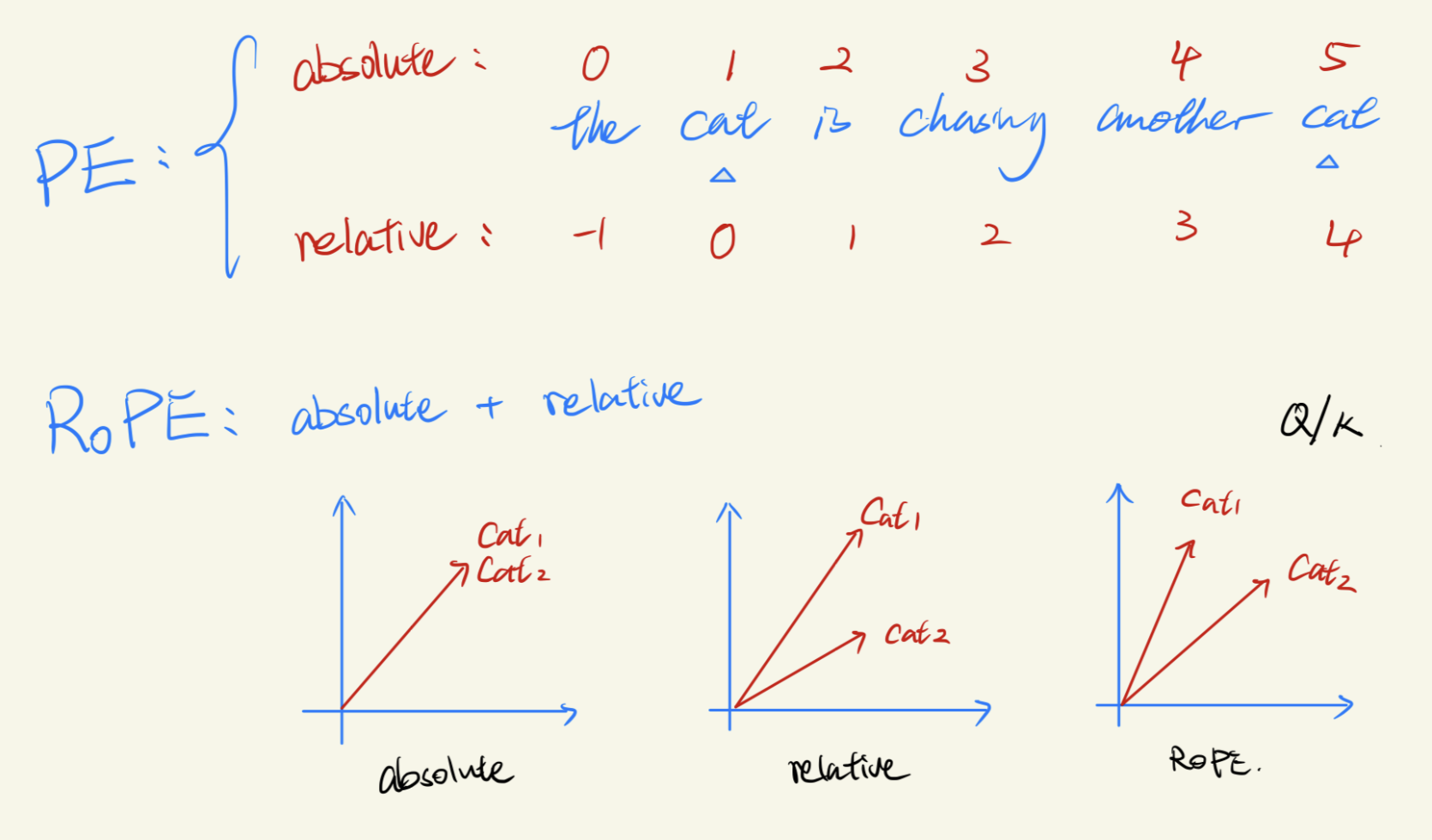
Position Embedding(PE)分类:
the cat is chasing another cat
- Absolute PE(绝对位置):
- 给每个 token 一个固定位置编号,例如:[0, 1, 2, 3, 4, 5]
- 缺点:在训练时序列较短的情况下能很好工作,但在 inference 时序列长度变长时会出现泛化问题,因为位置编码(PE)的维度不再对齐。- Relative PE(相对位置):
- 以当前 token 为锚点,相对位置:[-1, 0, 1, 2, 3, 4]
- 更关注的是“相对谁”,具备更好的泛化能力,但计算更复杂RoPE 位置旋转编码 = Absolute + Relative
- RoPE** 使用二维旋转的方式将绝对位置和相对位置同时编码到 Q、K 向量中。
- 向量角度 = 相对位置,长度 = 绝对位置
- 图解总结:
- Absolute PE:同一个词(如 “cat”)在不同位置的向量具有相同的方向,但长度不同。
- Relative PE:方向会根据不同的相对位置发生变化,但长度保持一致。
- RoPE:两者结合,既有角度差异又统一长度,编码更合理
数学上怎么做的?
- 传统 Attention:
- RoPE 中是先将 Q 和 K 都加上旋转矩阵:
- 合成矩阵
,是 RoPE 的核心:
- 说的是如何从「绝对位置」编码出「相对位置」的
- 是一个跟位置差有关的旋转矩阵,也就是说它其实就是 encode「相对位置」的信息;
- 所以虽然
和 是基于「absolute PE」生成的,但最终的 就是 encode 「relative PE」 的方式。 - 注意:不同位置的 Q/K 有不同的旋转矩阵,Key 的旋转会随着 token 推进不断变化;所以,RoPE 下的 K 是无法 cache 的!
RoPE 的问题:打破了数学 trick
- 之前我们说过 MLA 的优化 trick 是:
- 但用了 RoPE 后,K 前面多了一个旋转矩阵
: - 这时候 R 是跟位置相关的,而两个
是位置无关的 - 所以这个
没法提前吸收到 或 中去,优化就失败了 - 也因此:RoPE 无法使用之前省计算图的数学简化公式,做 inference 的时候就得在把k 重新算一遍。
解决:用 Decoupled RoPE 把 RoPE 拆到另一个分支里单独算,然后再拼回来
- Query 分为两部分(公式 6-9):
:是从 latent vector 来的,没有加 RoPE,方便优化 :是从另一个分支生成的,专门为了加 RoPE - 最终:
→ 拼起来 - Key 同理(公式 1-4):
从 latent 变换来 是直接从 来,用 RoPE 编码 - 最终:
→ 拼起来 可以看图2 中MLA部分:
- 左侧是 Q 路径:
, → concatenate - 右侧是 K 路径:
, → concatenate - 推理时,只缓存了
和 ,节省空间 - 中间的 RoPE 操作是即时应用在
和 上的
参考资料
- DeepSeek AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv:2405.04434
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437
- Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., & Liu, Y. (2024). A Survey on Mixture of Experts in Large Language Models. arXiv preprint. arXiv:2407.06204
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint. arXiv:2101.03961
- Zhou, Y., Lei, T., Du, H., Huang, L., & Zhao, J. (2024). Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts. arXiv preprint. arXiv:2408.15664v1
- Z. Lu and W. Xia, "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," COS597G Lecture 16, Princeton University, 2022. Online. Available: COS597G Lecture 16
- F. Glacial, A. B. Author2, and C. D. Author3 (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint. arXiv:2404.19737
- Y. Leviathan, M. Kalman, and Y. Matias (2023). Fast Inference from Transformers via Speculative Decoding. arXiv preprint. arXiv:2211.17192
- K. Zhang, J. Zhao, and R. Chen, (2024). KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning. arXiv preprint. Available: arXiv:2408.08146
- Transformers KV Caching Explained: How caching Key and Value states makes transformers faster
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part1 | 开源最强模型 | 性价比之王
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part2 | 开源最强模型 | 性价比之王的核心技术MLA
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part3 | 可能存在的问题
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part4 | 从入门到精通DeepSeek MTP
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付