8. DeepSeek-V3(V2)详读 3(架构 + DeepSeekMoE)
DeepSeek-V3(V2)详读 3 (架构 + DeepSeekMoE)
本节主要内容:传统MoE架构、DeepSeekMoE、负载均衡(Load Balancing)、Switch Transformers(损失控制)、Switch Transformer的问题、DeepSeek的Loss-Free方法。
写在引用符号里的,都是添加的知识点和理解。没有添加的是原文翻译的concise整理
1. Transformer结构简述
- Transformer由两大核心层组成:Attention 和 FFN(Feed-Forward Network/MLP)。
- Attention层:负责信息交互与全局建模,参数量较少,但计算量较大。
- FFN层:
- 负责存储模型知识(参数量大),是模型scale-up时体量激增的主要来源。
- LLM的强大部分依赖于FFN的高容量,但FFN也带来了计算与资源的挑战。
2. MoE(Mixture of Experts)原理简述
先看一下 review paper 介绍的什么是MoE。
- 核心思想:把 Transformer 的 FFN 层拆分为多个专家(Expert)组,输入经过gate分配给不同expert。
- Gate(门控)
- 输入
,Gate网络通常也是一个小MLP/FFN,计算每个expert的权重/概率 - 类似于分类模型的softmax输出,每个expert像是一个类别
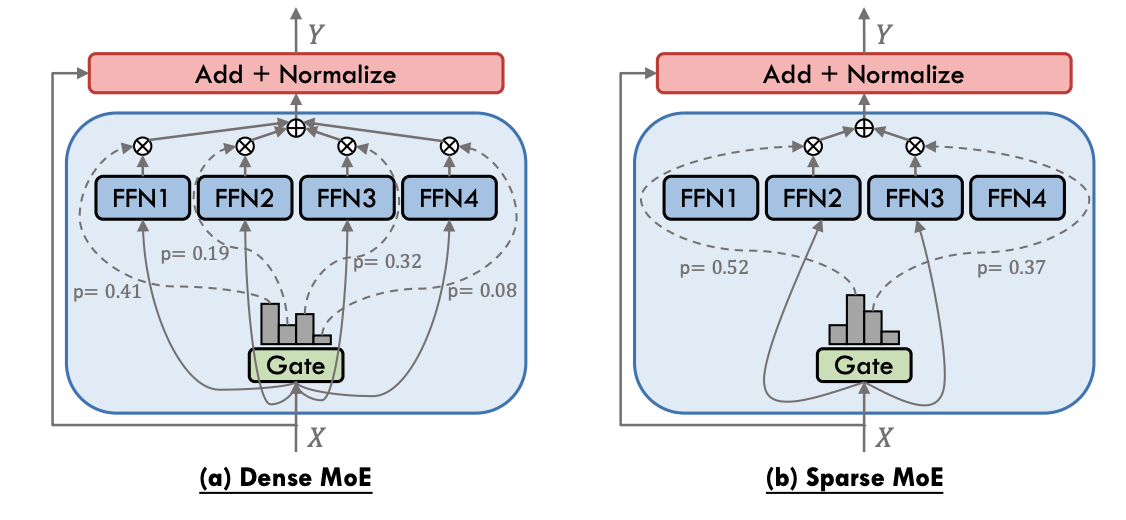
- 常见两大MoE:
- Dense MoE
- 图(a),全连接,每个都参与
- 每个 expert 都参与计算,Gate 生成的
作为权重,加权所有 expert 输出,做加权平均。 - Sparse MoE(主流)
- 输入
,经过Gate计算出一些列 , 把他们排序取 个experts参与计算。 - 只激活权重
个expert,其他expert不参与本次计算 - 图(b),使用
和 , 和 就不用了,然后 的输出和 做一个乘积,再sum起来。
- 优点
- 易扩展(scale up):可以轻松增大模型容量。
- 成本低(cost-saving):只需激活一小部分expert,computation就会减少
- 缺点
- 知识冗余:数据量大时,不同 expert 学到的知识可能重合(产生冗余),导致参数浪费。
- 区分度低:不同 expert 之间的能力不明显,容易所有 expert 学到类似的内容。希望某些expert擅长数学,某些擅长coding,但实际中这种区分往往不明显。
- MoE最大挑战之一:负载均衡(load balancing),防止部分 expert 被过度调用、部分 expert 闲置(后面细讲)。
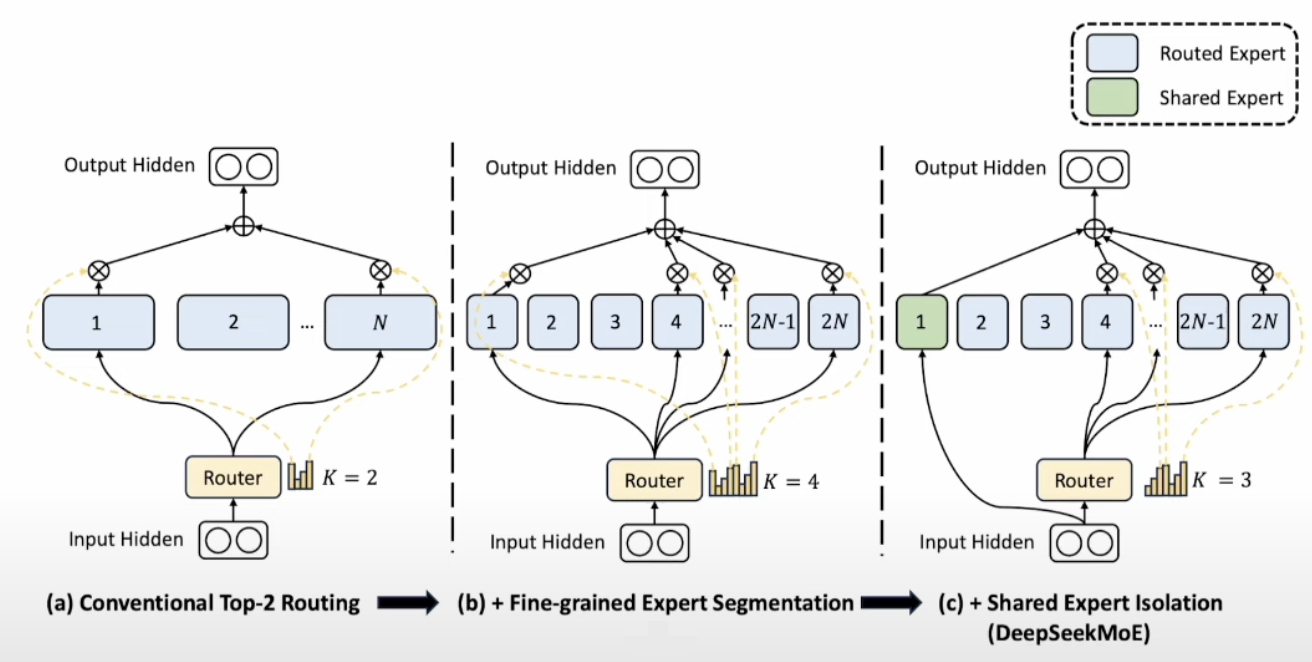
3. DeepSeekMoE 设计
DeepSeekMoE在传统MoE基础上做了两大核心改进:
- 图(a): 传统MoE,每次
,输入只选 2 个 experts 参与计算。 - 图(b): DeepSeekMoE 第一改进细粒度分割,expert 数量加倍,
数量加倍,参数均摊。 - 图(c): DeepSeekMoE 第二改进引入 shared expert 学习通用知识
- Fine-Grained Expert Segmentation(细粒度专家分割)
- 将原本的
个专家(experts)扩展为 个小专家,并将路由机制中的 值从默认值从 增加到 。 - 具体做法:
- 把原本数量较少、规模较大的experts,拆分为数量更多、规模更小的expert。
- 每个 expert 内部由 2 个 MLP 组成,通过减小这两个 MLP 层中间隐藏层的维度来压缩单个专家的参数量,虽然单个小专家的质量略有下降,但专家总数增加,总体参数量保持不变。
- 性能提升原理:
- 保持总参数量不变的前提下,通过增加专家数量来提升模型性能。
- Model Ensemble(模型集成): 这个改进类似于 Kaggle 比赛中常用的 ensemble 方法。每个专家可以看作一个基础模型。增加专家数量相当于增加了集成的模型数量,虽然每个小模型(小专家)的能力变弱了,但集成后的整体效果通常更好。
- Bias-Variance Tradeoff(偏差-方差权衡):从 machine Learning 的角度就是,单一模型若方差(variance)过高,易导致过拟合。通过model ensemble可以降低模型的 variance,哪怕每个模型性能变差了(bias增加),最终ensemble之后,整体性能因 variance 减小而得到优化。
- 数量-质量的互换:数量提升了,质量降低了,但性能提升了,在科研里面也是用的比较多的。
- Shared Expert Isolation(共享专家隔离)
- 在LLM推理的时,不同任务间有一些共同的knowledge,引入共享expert,负责学习common knowledge(通用知识)。
- 对于每一个输入,这个共享expert总是被激活,不参与 gate 的 top K 竞争。
- 因此,实际路由的top-K值从默认的
降至 ,系统始终优先调用共享expert,再从剩余专家中动态选择3个最相关的专才expert。 - 这样最终的输出是:共享expert + 3个专才expert的加权平均。
- 优势:
- 提供“全才+专才”机制:共享expert 懂得广但不深,专才expert 在特定领域表现突出。
- 高效性:模型的参数量没有增加。
- 计算守恒: 激活的专家总数
保持不变,因此计算量 (FLOPs) 也基本维持不变。 - 共享expert起到error correlation(错误相关性)的缓冲作用,可以补足专才expert偶发的盲区。
- error correlation(错误相关性):多个专家(experts)如果都是专才型,可能在同一个知识盲区上一起犯错——也就是说,他们的错误是“相关”的(有重叠/同源)。 而共享expert由于知识更广,可以“独立于”这些专才的错误,起到一个兜底、纠错的作用,缓冲这种“集体盲区”。
4. MoE训练中的Load Balancing问题
问题起源:
- 初始随机性: MoE模型在训练初期,所有专家(Expert)均处于随机初始化状态,性能均较弱。
- “赢家通吃”效应 (Winner-Takes-All / Self-Reinforcing): 训练过程中,某些专家(如Expert 1)可能因随机性或特定输入而较早表现出相对优势。模型发现将更多输入路由给这些表现较好的专家(Expert 1)能更快地降低损失(Loss)。
- 恶性循环: 这导致模型倾向于将越来越多的输入给这些 Expert 1,形成马太效应(强者愈强)。表现较弱的 experts 因接收到的训练数据不足导致训练的不好。
导致的后果:
- 模型训练完成后,只有少数experts 得到充分训练,而大部分experts训练不足。
- MoE的核心优势在于利用多个experts做sparse ensemble,提升模型容量与泛化性。若只有少数专家有效,就没有了做model ensemble的意义。最后只有一个expert训练的比较好,就会过拟合,影响模型泛化。
解决方案:
为了解决 token 分配不均(load balancing)问题,当前主要有两种方法:
- Switch Transformers 的 Loss Control 方法
- 在训练时,在 loss 函数中增加一个平衡项,对 token 分配极不均衡的情况进行惩罚(penalise)。
- 这样可以促使 gate 将输入更公平地分配给各个 expert。
- DeepSeekMoE 的 Loss-Free 方法
- 不在 loss 里加额外项,而是在 softmax 层内加入 bias(偏置)
- 动态控制各 expert 被选中的概率,实现 tokens 分配的平衡。
5. Switch Transformers
先讲一下 Switch Transformers 中提出的 loss control 去做 load balancing。
核心概念
- 目标:保证输入 tokens 在不同 experts 之间均匀分配,避免某些 experts 超载、某些 experts 闲置。
- Loss 设计:
- 相比 Shazeer et al. (2017) 的“双损失”(负载均衡+重要性加权),Switch Transformer 用一个可微的 auxiliary loss 实现负载均衡。
- 整体逻辑就是只用一个 loss 就能搞定 expert 负载均衡。
数学公式
- (1) 负载均衡损失(Load Balancing Loss)
:超参数(hyperparameter),控制 loss 权重 :experts 数量 :被 dispatch 到 expert 的 tokens 占比 :router 分给 expert 的概率占比 - (2)
(实际分配比例 actual dispatch ratio)
:batch 内 token 总数 :indicator function - 物理意义:expert
实际处理了多少 tokens - (3)
(router 概率分配比例)
:router 认为 token 属于 expert 的概率 - 物理意义:router 对 expert
的“软分配”概率均值
为何点积能促进负载均衡?- 设理想情况下每个 expert 分到的比例都是
,用 Cauchy-Schwarz 不等式 可以推导: - 只有
时取等号。均匀分布下 。 - 此时
达到最小。 - 结论:loss 最小时,
和 都接近Uniform(均匀分布)——这就是点积促进负载均衡的数学原理。
5.1 Loss control 的直观例子
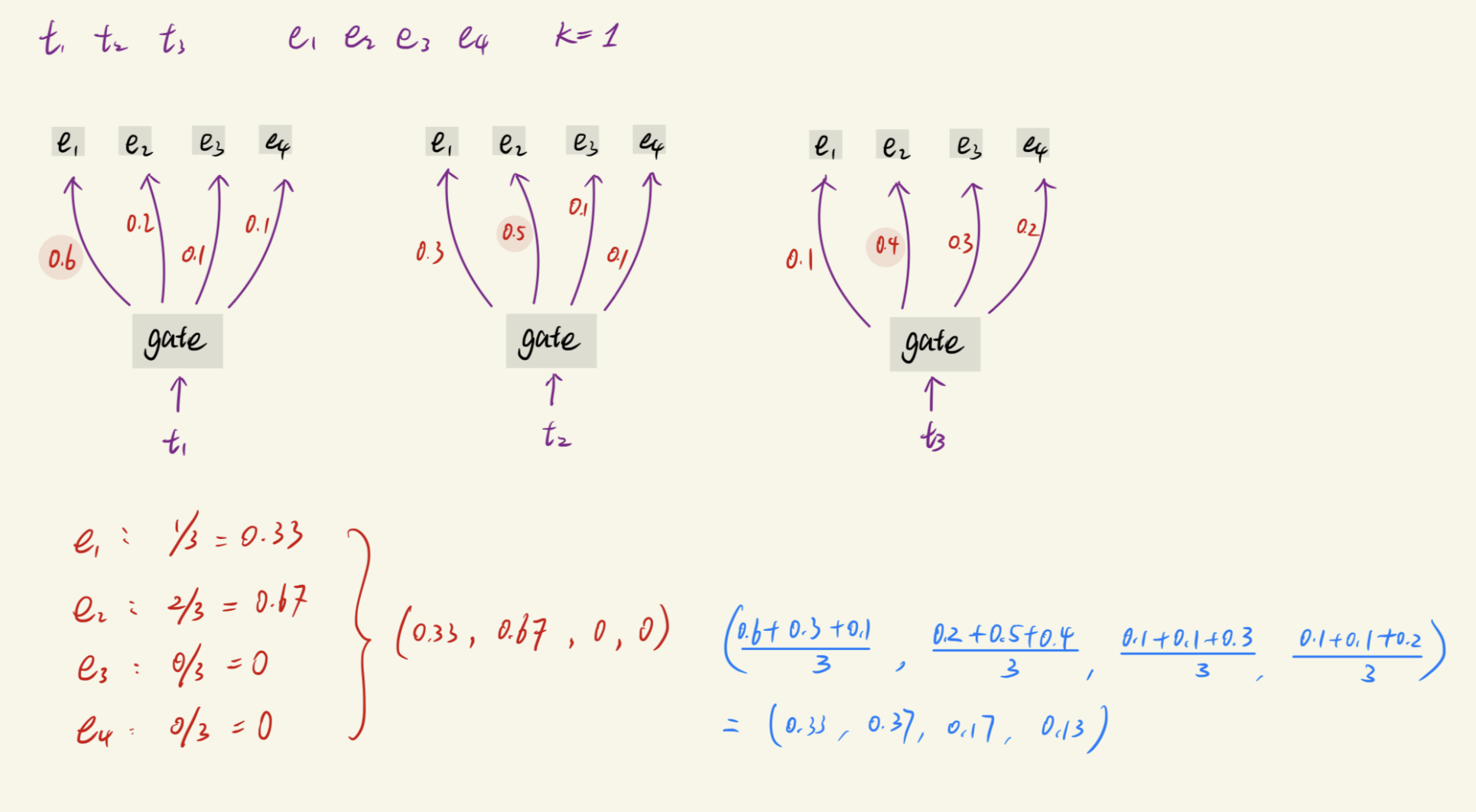
如果数学的东西很直观(可以跳过),看不懂的看下面这个例子:
- 假设有一个 batch,包含 3 个 tokens(t1, t2, t3),4 个 experts(e1, e2, e3, e4)
- 红色向量:表示实际分配到每个 expert 的 token 百分比,也就是观测到的每个 expert 实际接收到多少 tokens。
- 蓝色向量:表示 gate 层 softmax 的平均值(即分配概率的期望),代表理论上每个 expert 应该分到多少 tokens。
- Switch Transformer 的核心思想:
- 计算“实际分配向量(红色)”与“理论分配向量(蓝色)”之间的差距。
- 用这两个向量的关系(具体为
的和)作为一个 penalty loss(即 load balancing loss 或 auxiliary loss),加到训练目标里。 - 通过优化这个 penalty loss,使实际分配更接近期望分配(减小差距),实现 token 分配的负载均衡。
6. 理论问题与新方法
- 常见误区澄清
上面数学理论是错误的,文献认为当负载均衡损失(如)最小时,token 分配一定是均匀分布(uniform)。但实际上这并不总成立。普林斯顿大学的一份 lecture note 给出反例:当 (expert数), (token数)时, 此时分布明显不是均匀,但内积更小(图示如下)。
- DeepSeek 2024 年的 Auxiliary-Loss-Free 方法
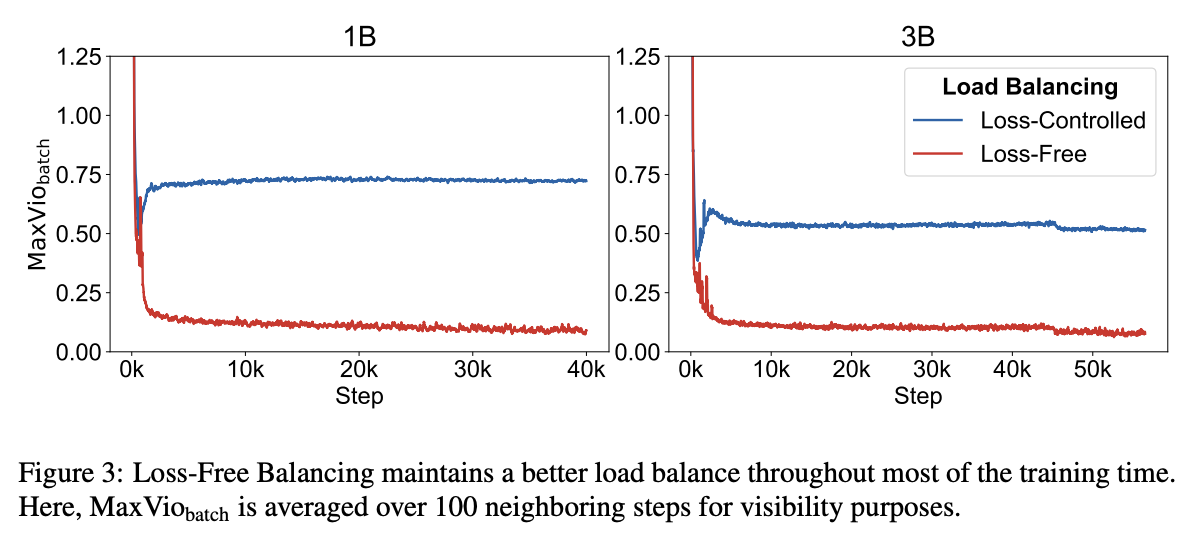
DeepSeek 在 2024 年提出了 Auxiliary-Loss-Free 的负载均衡方法。该 paper 对比了传统 loss control 方法和 loss-free 方法。图3:
- 纵坐标:DeepSeek 定义的负载均衡度量
- 横坐标:训练步数
- 结果:Loss-Free 方法(红线)负载均衡效果始终优于传统 Loss-Control 方法(蓝线),表现为衡量值更低、更平稳。Switch Transformer 出现负载异常上升,且难以收敛到理想状态。
- 现实状况
虽然 Switch Transformer 理论有问题,但由于引用量高依然被广泛沿用。即便如 DeepSeek-V3 的技术报告,也采用了 Switch Transformer 的一个变种。

2.1.2. 带无辅助损失负载均衡的 DeepSeekMoE
DeepSeekMoE 的基本架构。 DeepSeek-V3 的前馈神经网络(FFN)采用 DeepSeekMoE 架构。相比传统 MoE(如 GShard),DeepSeekMoE 使用更细粒度的专家,并设置部分为共享专家。
对于第
其中,
先来看一下图2 中 DeepSeekMoE架构,绿色的是shared expert 每个输入都会经过,不会做选择,蓝色的是 routed expert 就是会选择
经过。最后把两部分结果做加权平均。 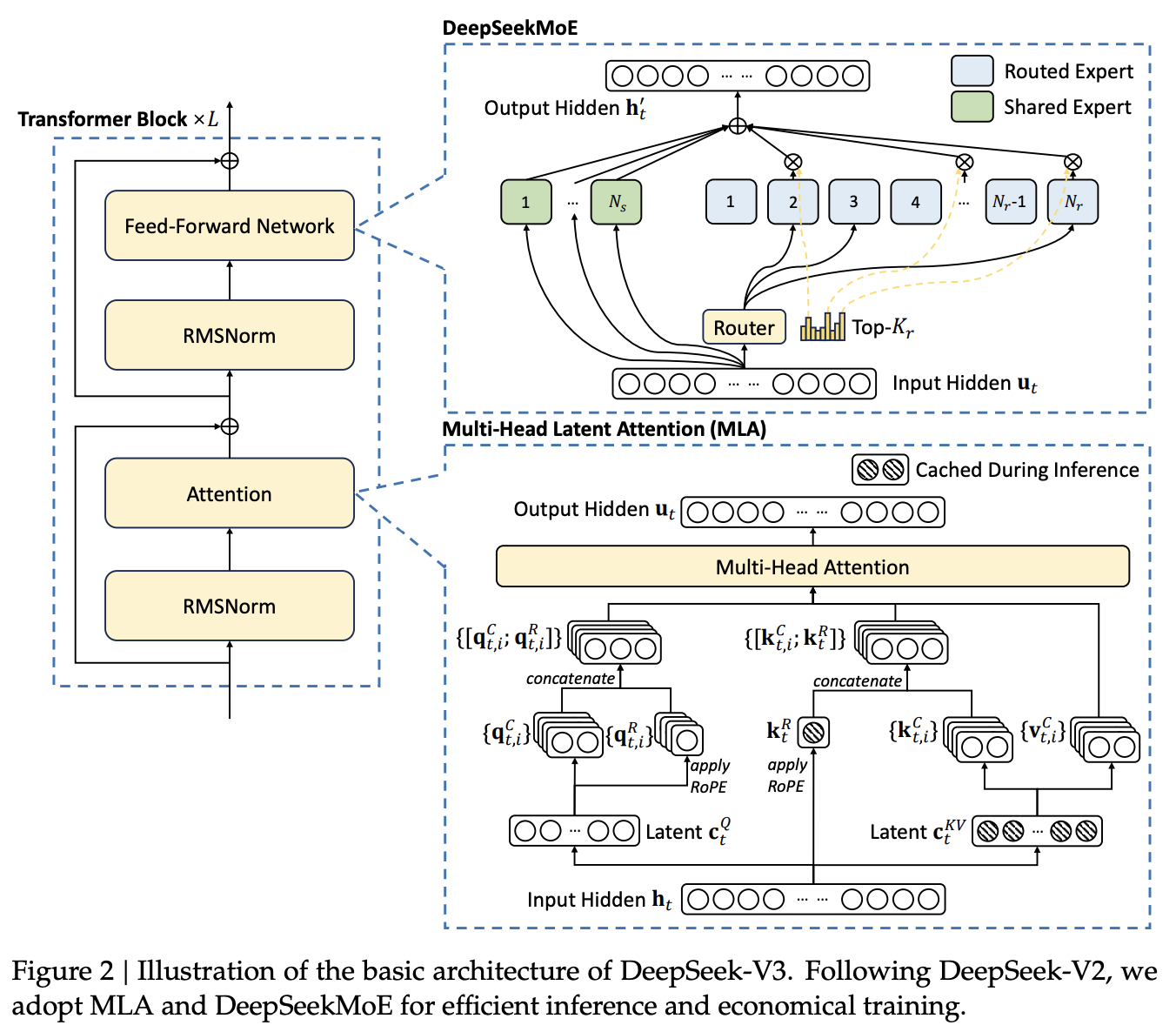
无辅助损失负载均衡(Auxiliary-Loss-Free Load Balancing)。 MoE 模型中,专家负载不均会导致路由崩溃和效率降低 (Shazeer et al., 2017)。传统依赖辅助损失平衡负载,但过大会影响性能。DeepSeek-V3 创新引入无辅助损失负载均衡,为每个专家添加偏置项
注意,偏置项只影响路由选择,最终门控值仍由原始亲和度
Switch Transformer 采用在主损失外添加辅助损失(auxiliary loss)来改善 load balancing。作者发现这个方法会影响模型性能,因为这个 loss 的最终目的是让 token 平均分配到每个 expert,本身并不直接优化模型能力。如果过度去 minimize 这个 loss(尤其是 loss 很大时),模型性能就会受影响。
针对这个问题,DeepSeek 提出了 Loss-Free 方法:
- 在 Top-K 路由选择阶段,每个 expert 增加一个 bias term
,与亲和度分数 相加,控制最终选择哪些 expert。 - 如公式(16),bias 只影响路由选择,门控值
不变,主 loss 也不变。 - 动态调整机制:
- 训练过程中,实时监控每个 expert 实际收到的 token 数量。
- 如果某 expert token 过多,就减小对应
;如果 token 过少,就增大 。 - 每次调整步长由超参数
控制。 - 这是一个动态调整,LLM的loss是不变的,这种方式既能控制 load balancing 也不会影响模型性能。
补充的序列级辅助损失(Complementary Sequence-Wise Auxiliary Loss)。 虽然 DeepSeek-V3 主要采用无辅助损失负载均衡,但为防止单个序列内负载极端不均,还引入了一个序列级平衡损失:
其中,平衡因子
除了上面介绍的 Loss-Free 方法,作者还提到了Sequence-Wise 的负载均衡方法:
- 这个方法本质上和 Switch Transformer 的 load balancing loss 类似,只不过是把负载均衡从 token level 拓展到了 sequence level,对应公式(17)。
- 说白了,还是“换汤不换药”——只是统计的粒度变了,思想没变。
- 这个 loss 的目的,是保持 Sequence 维度上的负载均衡(Sequence-Wise Balance Loss)。
- 但这种 loss 依然有问题,所以在实际训练时,只给了一个极小的权重(extremely small weight)。,所以这个 loss 在整体训练上作用不是很大。
节点限制路由(Node-Limited Routing)。 DeepSeek-V3 采用节点限制路由机制,每个 token 最多只被分配到
在 LLM 训练中,模型的不同部分通常会分布在不同的 GPU 上。对于大型 GPU 集群来说,每个 cluster 有多个 node,每个 node 里有多张 GPU。
- 问题:node 之间的数据通讯非常昂贵。如果一个 token 在计算过程中需要频繁跨 node 移动,会大大增加开销。
- DeepSeek 提出的方法:给每个 token 的路由加一个限制——每个 token 最多只能被分配到
个不同的 node 上。 - 这样可以有效减少 token 跨 node 通讯的次数,降低整体的分布式通信成本,提高训练效率。
无 token 丢弃(No Token-Dropping)。 凭借高效负载均衡,DeepSeek-V3 在训练和推理过程中都无需丢弃 token,确保任务完整、高效运行。
如果某些 expert 的负载(load balancing)已经很高了,这时再继续分配 token 只会让负载更不均衡。
- 常见做法是把这些 token “drop 掉”,其实并不是直接丢弃 token。
- 实际上,由于 Transformer 结构有 residual connection,所谓 “dropping” 是指不让 token 经过该 expert 的 FFN 层,而直接走 residual 路径,相当于跳过专家网络。这就是 token dropping 的实际意义。
- 之所以可以这样做,是因为前面的负载均衡机制已经保证了整体的 balance,所以不需要额外的 token-dropping 机制。
参考资料
- DeepSeek AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv:2405.04434
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437
- Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., & Liu, Y. (2024). A Survey on Mixture of Experts in Large Language Models. arXiv preprint. arXiv:2407.06204
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint. arXiv:2101.03961
- Zhou, Y., Lei, T., Du, H., Huang, L., & Zhao, J. (2024). Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts. arXiv preprint. arXiv:2408.15664v1
- Z. Lu and W. Xia, "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," COS597G Lecture 16, Princeton University, 2022. Online. Available: COS597G Lecture 16
- F. Glacial, A. B. Author2, and C. D. Author3 (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint. arXiv:2404.19737
- Y. Leviathan, M. Kalman, and Y. Matias (2023). Fast Inference from Transformers via Speculative Decoding. arXiv preprint. arXiv:2211.17192
- K. Zhang, J. Zhao, and R. Chen, (2024). KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning. arXiv preprint. Available: arXiv:2408.08146
- Transformers KV Caching Explained: How caching Key and Value states makes transformers faster
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part1 | 开源最强模型 | 性价比之王
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part2 | 开源最强模型 | 性价比之王的核心技术MLA
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part3 | 可能存在的问题
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part4 | 从入门到精通DeepSeek MTP
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付