8. DeepSeek-V3(V2)详读 4(架构 + MTP)
DeepSeek-V3(V2)详读 4 (架构 + MTP)
今天我们继续撸 DeepSeek-v3 的 technical report,这一部分要讲的就是 Multi-Token Prediction(MTP)。MTP 是 DeepSeek 提升训练效率、增强推理能力的关键技术,也是一大 cost‑saving 技术。可以说,MTP就是 DeepSeek 降本增效的法宝。在正式讲细节前,还是top-down路线,先来一波大致框架,帮大家建立一个模糊的全局观。
1. 背景知识
先整体看 paper 背景结构,DeepSeek MTP 採用了两类已有方法:
- Meta MTP Gloeckle et al. (2024) 提出 Parallel Heads MTP,目标是:
- 一次预测多个 future tokens;
- 增加训练信号密度(densify training signals);
- 提升 generalization 能力;
- 降低训练成本。
- Speculative Decoding 方法体系(用于加速 inference):主要是提升推理效率,先去猜一些输出 token,然后主模型去验证。大致分为两类思路
- Independent 流派:用外部轻量(小)模型生成 draft(代表作来自 Google / DeepMind);
- Self 流派:用模型自身的一部分来 draft,进一步细分为
- Medusa:用 parallel heads 生成多个 draft tokens(并行);
- EAGLE:用 causal/sequential heads(自回归方式)生成 draft tokens,更接近原生语言模型结构,准确率更高。
Training 阶段的问题:
- 传统 LLM 只做 next‑token prediction,信号稀薄导致效率低。
- Meta MTP 方法可以 densify 信号,通过多个 heads 并行预测多个 tokens, 提升训练效果。
Inference 阶段的问题:- 传统 autoregressive decoding 一步一步出 token太慢。
- Speculative decoding 用 draft 模型或额外 heads 先预猜 tokens,再让主模型验证,可以提升 throughput。
不管是 Meta MTP,还是 Medusa/EAGLE 的 speculative decoding,本质都在做一件事:Predict Future Tokens。所以可以把它们抽象为一个统一的大类方法,多 token 预测。
DeepSeek 的做法非常巧妙,它把 Meta MTP 中的 parallel heads 替换成了 EAGLE 中的 causal heads;因为 EAGLE 已经实验证明:causal heads(顺序预测)比 parallel heads 更准确、更有效;不过需要注意的是:
- EAGLE 和 Medusa 原本是用于 inference 加速;
- 而 DeepSeek 是把它们借来用在训练阶段,解决 training signal sparse 的问题。
DeepSeek MTP = EAGLE 的 causal heads + Meta MTP 的训练思路 = 更强的训练效率 + 兼容推理加速!
一篇 paper 其实它本身就是前人多篇论文的“输入”结果。所以我们在读一篇 paper 的时候,光知道 what(这篇 paper 讲了啥)还不够,更要追溯它的背景,搞懂它的“前世今生”——也就是 why。如果只知道 what,不理解 why,也没有建立自己的直觉,那对知识的掌握其实还很浅。只有把 why 也搞清楚,建立了直觉理解(intuitive understanding),我们才能真正理解知识、并举一反三。一个知识点的来龙去脉都理顺,理解深了之后,找到不同知识点之间的联系,再进行外推和创新,这样就能产出自己的新东西。现在知识摄取也变得碎片化,大部分人只能关注某一个小点,忽略了知识的整体脉络。梳理整体脉络让知识变得立体、有“生长感”。
2. Training 细节与推理方式对比
先给大家介绍一下大语言模型 training 的一些细节。为了帮助大家理解,我先简单回顾一下 language model 的 inference 是怎么做的。
- Inference(推理)
- 比如说我想让 language model 生成
欢迎来到这这个句子。
[START]->欢:首先输入一个起始 token(比如 [START]),模型生成 “欢”;[START] 欢->迎:把刚才输出的 “欢” 和之前的 [START] 作为下一步的输入,模型再生成 “迎”;- 以此类推,逐步生成完整句子。
- 这是一个完美的例子,假设模型每一步都没犯错。
- 但实际上,模型推理时经常出错——比如该生成“迎”,结果生成了“乐”。因为推理时没有 ground truth,生成错了后面所有输入就都基于错误,最后输出就会越走越歪。
- Training(训练)
- 训练时和推理有点不一样:
- 训练阶段我们是有 ground truth 的,比如目标句子是
欢迎来到这。- 这里就用到了一个经典概念:teacher forcing。
- 什么是 Teacher Forcing?
- 在训练时,模型每次预测的 token 可能和 ground truth 不一样。比如第一次正确生成了
欢,第二次却生成了乐。- 这时就有两种选择:
- 用模型上一次预测出来的结果继续输入(比如用
乐);- 用 ground truth 的 token(比如
迎)作为下一步输入。- teacher forcing 的做法就是:不管模型生成了啥,都直接用 ground truth 做输入,每次都让模型在理想上下文里预测下一个 token。
- 所以,Training 时,输入永远是正确的(来自 ground truth);inference 时,只能用模型自己上一次的输出。这会导致 Training 和 inference 之间天然有 gap。
- Training 方式的两个核心问题
- 模型依赖完美上下文
- 训练时 context 总是 ground truth,但推理时 context 可能很快就歪了;
- 每次只预测一个 token
- 这种机制让模型“很近视”,因为它没有做更长远的 planning。人类说话往往先规划好一整个句子,而不是每次只想一个词。
- 结果:
- 模型的 planning 能力差,输出容易偏离主题;
- 训练时的信号也比较弱(每次只预测一个 token,监督信号 sparse,模型收敛慢)。
- 更强 training signal 的自然思路
- 既然一次只预测一个 token 有这些问题,能不能让模型一次预测多个 token?这样不就能:
- 提高 training signal 密度,
- 增强模型的 planning 能力,
- 加快训练收敛吗?
这个思路就是——Multi-Token Prediction(MTP)!
3. Transformer 并行训练机制
其实 Transformer 本身是可以做并行计算的,所以实际训练大语言模型的时候,流程比我前面说的“一步步输一个 token”要高效复杂不少。
- 如何利用 Transformer 的并行计算?
- 简单来说,我们会把整个序列(加上一个 start token)一次性扔进 language model 里;
- 比如序列是:
[START], 欢, 迎, 来, 到...- 目标是让模型预测每个 token 的下一个 token:
[START]的下一个 token 应该是欢;欢的下一个是迎;迎的下一个是来;- 以此类推;
- 输入序列就是原始句子,ground truth 就是把原始序列右移一个 token(shift one)。
- Self-Attention 的 Causal Mask
- 如果直接把整个序列扔进模型,Transformer 的 self-attention 机制理论上会让每个 token 看到序列中所有其它 token,包括“未来”的 token,这就不对了;
- 因为我们要训练的是一个自回归(causal)模型,每个 token 只能看“过去”,不能看“未来”。
- 怎么解决?—— 加 Mask
- 在 attention 里加一个 三角 mask,确保每个位置只能看到它自己以及它左边(前面的)所有 token,看不到右边的 future tokens。
- 三角 mask (lower triangular mask):左下角全是 1,右上角全是 0,屏蔽的是右上部分
2
3
4
5
6
7[
[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]
]
4. Meta 2024 MTP 论文(Multi-token Prediction)
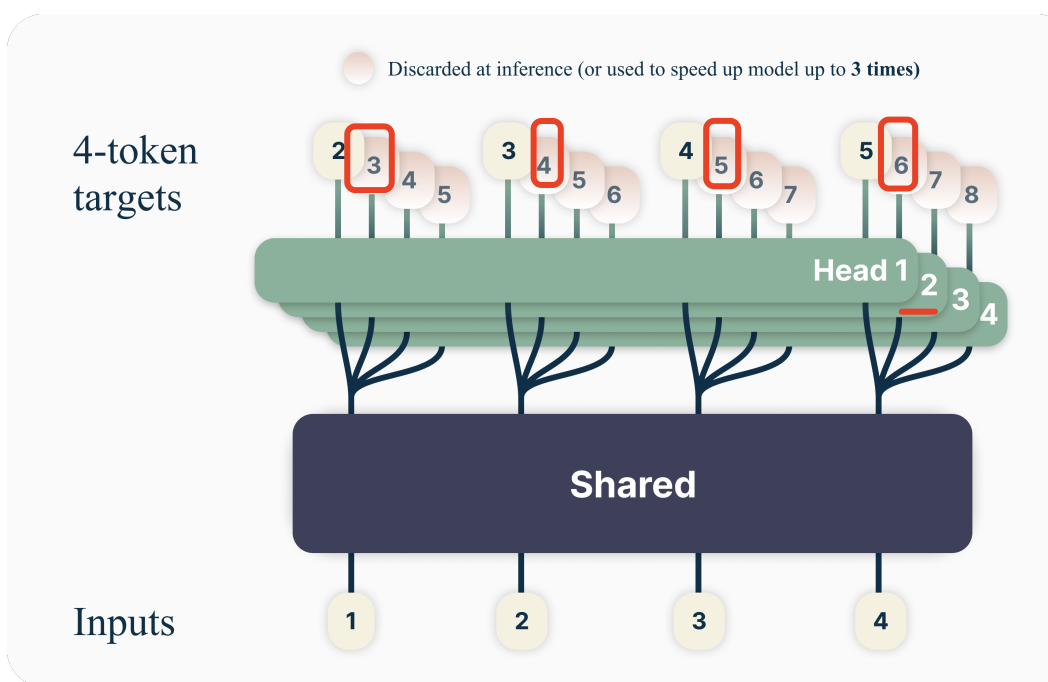
Meta 在 2024 年 4 月提出的 Multi-token Prediction(MTP)方案。论文提出:模型不再只预测下一个 token,而是“一次预测多个 future tokens”(这里以预测 4 个 future tokens 为例)
Head 分组
- Multi-Head Attention 的多个 head 被“分组”,每个 head 专门预测某个 future token:
- Head 1 预测下一个 token(Next token prediction);
- Head 2 预测第二个 future token(再往后推一格);
- Head 3 预测第三个 future token;
- 以此类推…
- 拆开理解每个 head
- 只看 Head 1: 这就是标准的 Transformer 并行训练,输入序列是 1,2,3,4,输出是 2,3,4,5,也就是说,input 1 通过 Head 1 预测 Token 2,input 2通过 Head 1 预测 Token 3,以此类推。shift by 1 token(输入序列右移一位)就是 ground truth(GT)。
- 看 Head 2: 类似地,输入还是 1,2,3,4,但输出要预测 3,4,5,6(相当于 shift by 2 tokens)。也就是每个 token 不再预测下一个,而是预测它后面第二个 token。
- Head 3/Head 4 也是同理: 比如 Head 3 是 shift 3 个 token(输出 4,5,6,7),Head 4 shift 4 个 token(输出 5,6,7,8),每个 head 负责预测更远的 future。
这样做带来了什么好处?
- 更丰富的 Training Signal
- 原来只预测 next token,训练信号有限(比如只学 2,3,4,5),
- 现在每个 head 都会计算 loss,模型能同时学到更多 future 的信息,训练信号更密集、更丰富,学习更高效。
- 解决模型“近视”问题
- 原来的 next-token prediction,本质上是“近视眼”,只能考虑下一个 token,planning 能力弱。
- 如果一次预测 4 个 token,模型就需要考虑更长远的序列(近视好了),planning 能力明显增强。
- teacher forcing gap 减少
- 传统 next-token prediction,Training 用的是 GT,在做 inference 时只能用模型上次输出,二者 gap 比较大;
- MTP 让模型能学到更长依赖(long distance transition),即使有些关键 token 预测错了,模型也能更快适应、恢复。
5. Meta MTP 如何解决 Teacher Forcing 问题 & 实验现象
- 直观解释:MTP 为什么更强
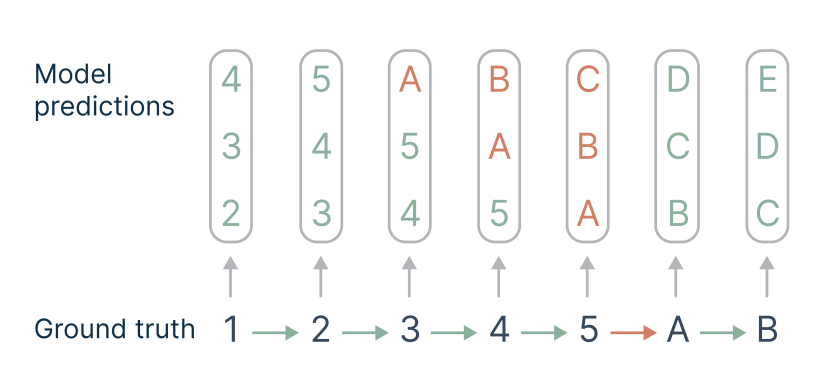
- 作者用一个“transition”例子来说明 multi-token prediction 的优势。
- 假设 ground truth 序列是
1 2 3 4 5 A B,其中5→A是个难预测的“hard transition”,其它 transition 都很简单。- 如果用传统的 next-token prediction,模型每次只能学到
1→2, 2→3, 3→4...,整个训练集里 hard transition 的占比很低(如图只占 1/7≈0.14),模型对难点学得慢。- 如果一次预测多个 future tokens(比如预测 3 个),模型就被迫在同一序列上学到更多的 hard transitions:像
3→A、4→A、5→A等,这些难点 transition 的占比一下提升(如图占 6/21≈0.28),这样的 hard transition 会多次出现在 loss 计算 ( loss被隐式加权) 里,权重提升了,模型会自动把精力多花在这些“难点”上。- 总结:MTP 让模型自然而然学会如何跨越那些最难的、最有意义的序列转折点。
- 图示理解:如图展示了用 4-token prediction 后,各种规模模型的 MBPP Pass@1 提升幅度:
- 大模型(13B/6.7B/3B)提升明显;
- 小模型(0.3B/0.6B)反而性能下降,出现负提升(-1.7)。
- MTP 对大模型的效果是正向的,但对小模型可能“难度太大”,导致泛化能力反而下降。
- MTP 的两大优点
- 提高 training efficiency
- 更密集的监督信号,不浪费每一批数据,提升收敛速度。
- 在大模型时代,训练一发就是烧钱,效率直接关系到能不能玩得起大模型。
- 增强模型 reasoning 能力
- 不再是“近视眼”模型,只能盯着下一个 token。
- 强化模型对复杂跨步逻辑、长距离依赖的掌控。
- Meta MTP 并行方案的缺陷
- 虽然理论好,但它让每个 token 的未来输出是“并行”预测出来的:比如 input token 1 直接同时输出 2、3、4、5。
- 这其实和我们真正使用 LLM 时的 autoregressive 生成流程有 gap:现实里,LLM 是一步步地基于前文条件分布,不断 sample 新 token。
- 所以直觉上说,Meta MTP 并行 heads 方案违背了 autoregressive 的自然生成逻辑。比如生成
4其实要依赖的2、3都已经被正确生成。- 这就引出了后续另一条线:EAGLE。EAGLE 把这些并行 heads 换成 autoregressive heads,更贴合 LLM 的本质,但它的原始动机其实是为了解决 inference效率问题(而不是 training 效率问题)。
6. Speculative Decoding 动机与直观例子
- 大语言模型推理的最大痛点:慢!
- 主要问题:推理速度慢,带来的后果就是推理成本高、用户体验差。
- 领域现状:大家都在想办法提速。常见方法有 KV cache,另一种就是 speculative decoding。
- 为什么推理会慢?(系统层面剖析)
- GPU 结构分 memory(主要存储数据和参数)和 cache(计算用的高速缓存),其实和 CPU 类似。
- 真正的算力瓶颈不在于矩阵乘法本身,而在于数据从 memory 拷贝到 cache 的传输!
- 大模型参数量极大,推理时数据搬运就慢,小模型虽快但精度不够。
- 能不能用“小模型的速度”带动“大模型的精度”?
- Speculative Decoding 的核心思路
- 核心想法:用一个“快但不太准”的小模型(学徒)先猜,然后再由“慢但很准”的大模型(大师傅)来检查和修正。
- 类比一:学徒与大厨
- 5星米其林餐厅,有大厨和学徒:
- 大厨慢但精致,每道菜10分钟;
- 学徒快但粗糙,每道菜1分钟。
- 需求:10道菜。
- 全由大厨做要100分钟;全由学徒做只需10分钟但不达标。
- 折中做法:
- 让学徒10分钟内先做好10道菜,大厨来检查,合格的直接用,不合格的重做(比如只需补做4道菜,40分钟)。
- 总耗时 = 10分钟*4 + 1分钟*6 = 46分钟,比大厨全做快了一倍,菜品也达标。
- 类比二:CPU 的分支预测(Branch Prediction)
- 写的代码经常有 if/else 分支,比如
if a: 执行X,否则执行Y,真正要走哪一条,其实得等a的结果出来后才能决定。- 两种选择:
- 保守做法:CPU 等到
a的值被算出来,再去选择执行 X 还是 Y。这是最保险但也最慢的方式。- 提速做法(branch prediction):CPU 直接根据历史经验猜测一下哪个分支更可能成立,提前把某个分支的代码先执行起来。
- 如果猜对了,直接拿提前算好的结果,完全不浪费时间。
- 如果猜错了,那就把另一条分支重新执行一遍,整体来说大部分情况还是更快的。
- CPU 怎么猜? 并不是瞎猜,而是根据以往运行的数据、统计规律推断哪个分支更常走,这样准确率会更高。
7. Speculative Decoding 的核心思路
如果前面的“学徒/大厨”和“CPU分支预测”例子你已经明白了,那理解 speculative decoding 就非常容易了!
- Speculative Decoding 的两大关键
- Quick Guess(快速猜测):由一个小而快、但精度一般的模型来生成初步结果。
- Cheap Verification(低成本验证):由一个大而慢、但很准的大语言模型来验证这些初步结果。
- 两种主流实现流派
- Independent 流派
- 用一个完全独立的小模型负责 draft(比如 MiniLM、DistilLM 等),大模型用来做判断和修正。
- Self 流派
- 不引入独立模型,而是在大模型内部划分出一些 heads 来生成 draft,再由主模型本体验证。
- 以
欢迎来到这为例讲 Independent 流派
- 假设大模型生成一句话需要 10 分钟,小模型只要 1 分钟。
- 步骤如下:
- 小模型先快速生成全句 draft,比如
欢迎来到这;- 大模型拿到 draft,每个 token 都计算一次概率分布,判断小模型给的 token 是不是自己认为最有可能的;
- 如果全部 token 都通过,大模型直接接受结果,推理速度≈小模型速度;
- 如果某个 token(比如
欢乐)概率不是最大,说明这里有错,大模型就从这里开始(也就是LLM接受 第一个 token欢,reject 后面所有的 token),把剩下的 token 都重新自己生成。- 这样,大部分情况下只需要小模型的推理时间,只有出错时才用大模型补救,整体效率大幅提升。
- Sampling 与分布一致性
- 上面是极简描述,实际上大模型每次生成 token 会采样(sampling),不是死取概率最大值。
- Google 和 DeepMind 的论文证明:这种 speculative decoding(小模型先 draft + 大模型再验证和修正)的方式,最终生成的概率分布与纯大模型单独推理出来的是一样的,结果不变,但推理速度更快。
- Google 2023 Paper: Speculative Decoding 实际案例解析
- 我们来看 Google 2023 年 5 月的 Speculative Decoding 论文,这张图展示了用“小模型+大模型”生成长文本的全过程:
- 绿色 token:小语言模型快速生成的建议(drafts),速度快但偶尔会错。
- 蓝色 token:大语言模型用来修正错误的部分(即 rejected token 的替换)。
- 红色 token:被大模型判定为错误的小模型结果。
- 具体流程:
- 第一阶段,输入
[START],小模型一口气生成一堆 token,比如 "japan’s benchmark bond n"(bond n 是错误)。- 把这个序列直接交给大模型,大模型逐个验证。如果发现 “bond” 不合理,就拒绝,自己生成正确的 token(比如 "nikkei"),并继续接受剩下小模型生成的 token。
- 进入下一个阶段,继续用小模型生成后续内容,还是把已验证的内容作为 context,然后再交给大模型逐一验证和修正。
- 这个过程会不断重复,直到生成结束。绿色部分越多,整个生成就越快,因为大模型只需要修正小模型出错的地方,大部分时候都可以直接“跳过”生成。
- 优点:
- 小模型即插即用:不需要专门为某个大模型重新训练小模型,off-the-shelf(现成的 )小模型(比如 Llama 7B vs 70B)就能用,直接拿来加速。
- 部署灵活:对于大部分主流大模型,配一个小模型就能用,节省大量开发和训练成本。
- 缺点:
- 无法无限套娃:如果你想加速小模型本身(让它实时 real-time),但又找不到比它更小、又能跟得上指令能力的模型,这招就行不通了。
- 系统更复杂:实际应用要同时跑两个模型,工程复杂度高,稳定性和资源消耗也变大。按照第一性原理,复杂的系统都可以(而且应该)继续简化。
- 进阶思考:把小模型集成进大模型(Self流派)
- 一个非常直接的想法是:能不能把小模型的功能直接做进大模型里?
- 答案是可以的!我们可以在大语言模型内部,额外加上一些参数量很小、计算很快的 heads 或小模块,让它们充当“小模型”角色。
- 这样的话,实际部署时就只需要跑一个大模型,系统结构也变简单。
- 这种方法对 7B 这样的中小模型也完全适用。
- 注意点:这些额外的 heads(draft 头)需要单独训练,不是“买一送一”的那种一键加速方案。
- 这就引出了下一个话题——这种“内置小模型”思路的两个代表作,接下来会详细讲解它们的原理和差异。
- Medusa
- EAGLE

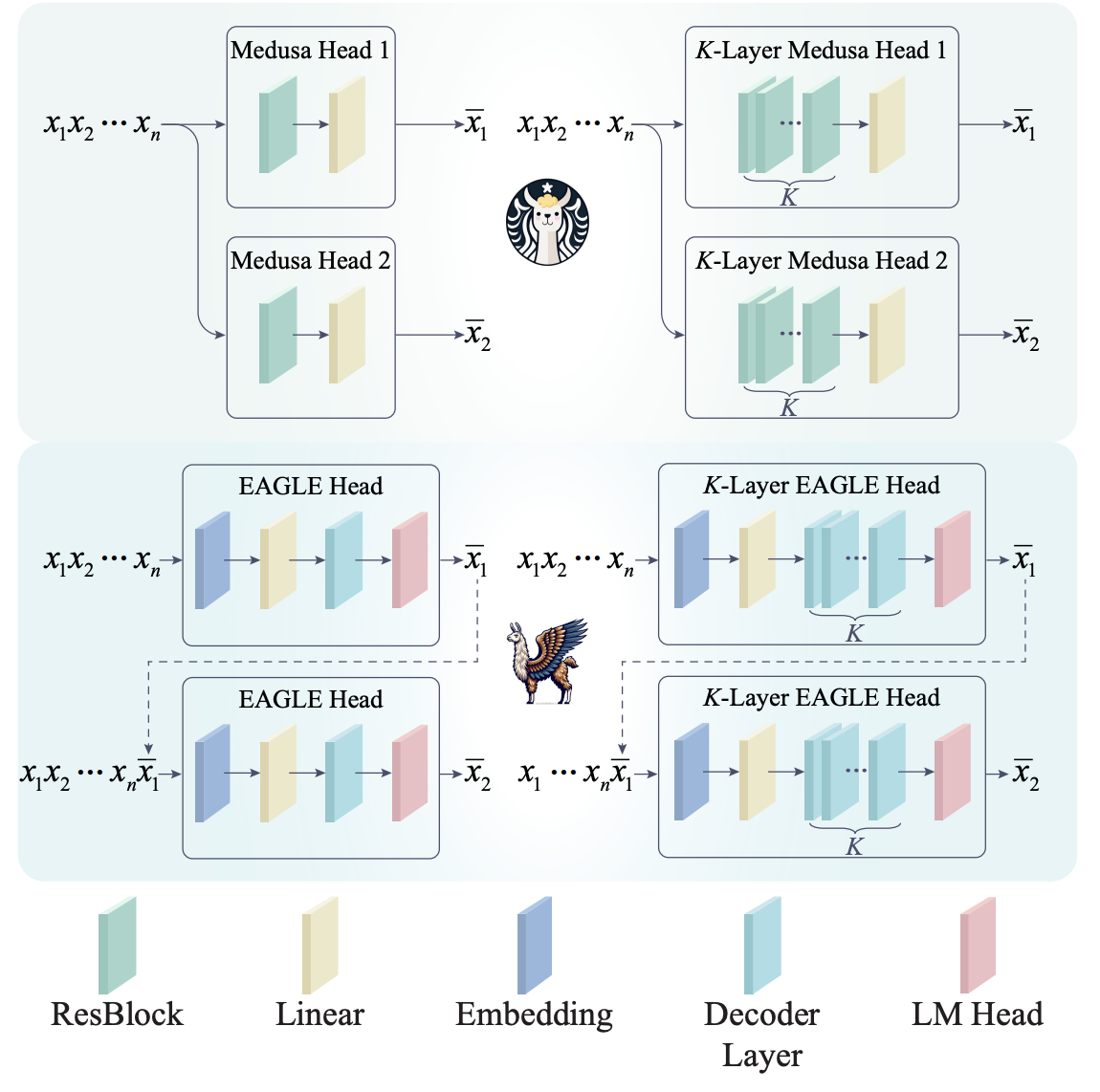
8. Medusa v.s. EAGLE
Medusa vs EAGLE:架构差异
- Medusa 方法:
- 原理:添加额外的 head,Head 1 用于传统的 next-token prediction(预测下一个 token),Head 2 用于预测未来第二个 token。
- 架构特点:两个 head 是并行的(parallel heads)。简单来说,每个 head 各自负责预测不同的 future token。
- EAGLE 方法:
- 原理:在预测第一个 token 后,生成的 token 会作为输入传递到下一个 head,并与之前的所有 token 进行 concat(拼接),然后再预测第二个 future token。
- 架构特点:这种方式类似于自回归(autoregressive)模型的生成方式,每个 token 依赖前一个 token 的生成结果。
- 直观对比:
- 直觉上,EAGLE 的架构更符合语言模型生成的自然逻辑,因为它保留了 autoregressive(自回归)结构。
- 实验结果:EAGLE 在效果上也优于 Medusa,生成质量更好。
DeepSeek MTP 的思路
- DeepSeek MTP 目标:提高 LLM 的训练效率,减少成本。
- 思路来源:DeepSeek 的作者受到 Meta MTP 和 speculative decoding 思路的启发,特别是希望通过减少推理时间和训练时间来降低大模型的整体成本。
- LLM train:Meta MTP(parallel heads)
- LLM inference:speculative decoding -> Medusa(parallel)/EAGLE(causal ✅)
- MTP 方法的应用:
- Meta 的 MTP 使用 parallel heads 来预测所有 future tokens,但这种方式有些直观上的问题,尤其是它不符合 autoregressive 模型的自然顺序。
- DeepSeek 的作者看到这种不一致性后,决定将 Meta MTP 的 parallel heads 换成 EAGLE 中的 causal heads,从而使得方法更加符合自回归的结构。
2.2. 多 token 预测(Multi-Token Prediction)
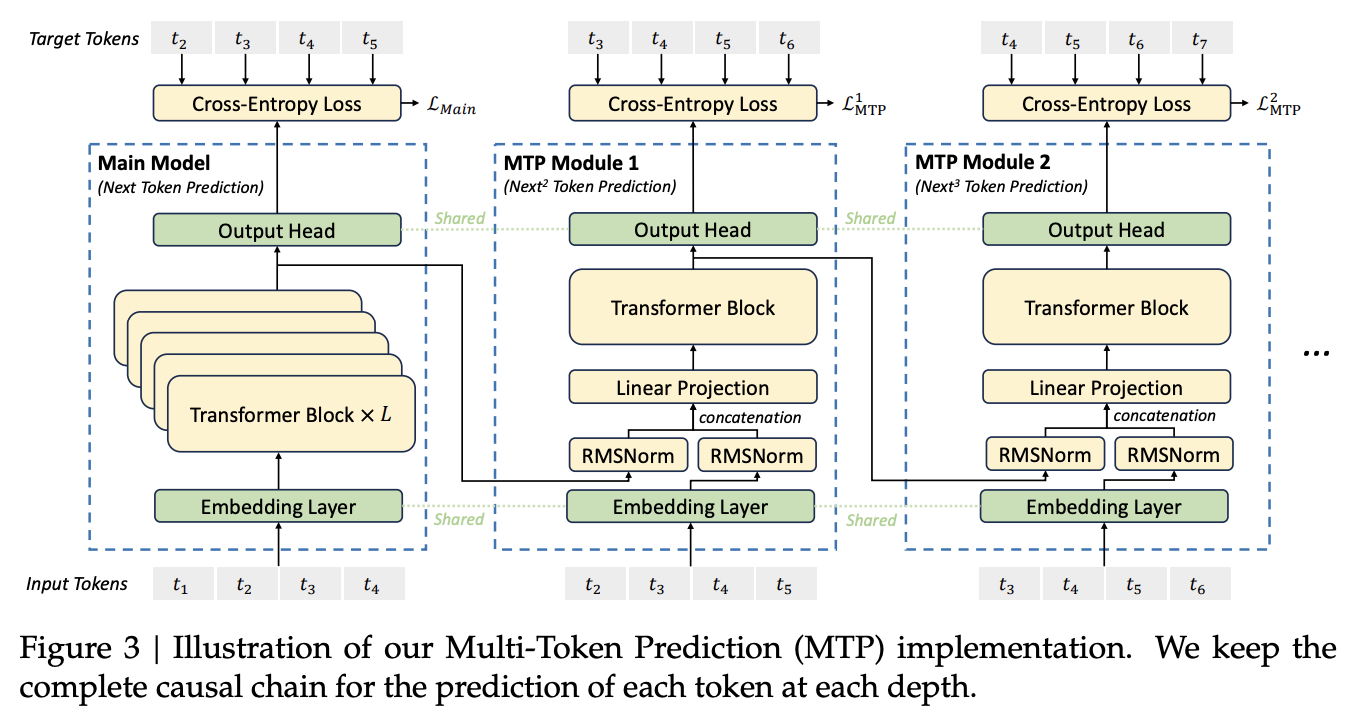
受 Gloeckle 等人启发,DeepSeek-V3 采用多 token 预测(MTP)目标,将每个位置的预测范围扩展为多个未来 token。这样既增强了训练信号密度,提高了数据利用率,也有助于模型提前规划、优化预测。不同于以往直接并行预测
- 架构总览
- DeepSeek 技术报告里 Fig 3 展示了 MTP 的整体架构。
- 三个模块:
- Main module:主干网络,跟传统 Transformer 一样,输入
,预测 ground truth ,也就是 shift one。 - 两个 MTP modules:分别预测第二个 future token(shift two)和第三个 future token(shift three)。
- 细节拆解
- Main module 的输出不是 token,而是 feature。
- 这个 feature 会直接传给下一个 MTP module,并与下一个 token 的 embedding 做 concat,也就是每一层的输入都包含了前面模块的输出和当前 token 的信息。
- 这种串联和特征传递,本质就是 EAGLE 提出的 causal heads 方案。
- Loss 设计
- 训练时,三个模块各自都有 loss,最后总 loss 就是三者相加。
- 推理时,只用 main module,MTP modules 可以直接丢掉——完全不影响正常推理速度。
- 功能&效果
- 这种设计让模型在训练时 feature 就蕴含了 future token 的信息,自带一定的 planning 能力,提升 reasoning。
- 结果实验显示:
- 不管是小的 MoE 模型,还是大的 MoE 模型,加上 MTP 之后在绝大多数数据集上性能都提升了(加粗的数字)。
- 结论:DeepSeek 的 MTP 架构不仅简单实用,对训练效果提升很有帮助。
MTP 模块。 MTP 使用
其中
输出头
MTP 训练目标。 对于每一个预测深度,计算交叉熵损失
其中
这个损失作为 DeepSeek-V3 的额外训练目标。
推理阶段的 MTP。 MTP 主要用于提升训练性能,推理时可直接舍弃,主模型可独立运行。如有需要,也可用 MTP 模块实现“推测解码”,进一步降低生成延迟。
参考资料
- DeepSeek AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv:2405.04434
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437
- Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., & Liu, Y. (2024). A Survey on Mixture of Experts in Large Language Models. arXiv preprint. arXiv:2407.06204
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint. arXiv:2101.03961
- Zhou, Y., Lei, T., Du, H., Huang, L., & Zhao, J. (2024). Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts. arXiv preprint. arXiv:2408.15664v1
- Z. Lu and W. Xia, "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," COS597G Lecture 16, Princeton University, 2022. Online. Available: COS597G Lecture 16
- F. Glacial, A. B. Author2, and C. D. Author3 (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint. arXiv:2404.19737
- Y. Leviathan, M. Kalman, and Y. Matias (2023). Fast Inference from Transformers via Speculative Decoding. arXiv preprint. arXiv:2211.17192
- K. Zhang, J. Zhao, and R. Chen, (2024). KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning. arXiv preprint. Available: arXiv:2408.08146
- Transformers KV Caching Explained: How caching Key and Value states makes transformers faster
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part1 | 开源最强模型 | 性价比之王
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part2 | 开源最强模型 | 性价比之王的核心技术MLA
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part3 | 可能存在的问题
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part4 | 从入门到精通DeepSeek MTP
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付