8. DeepSeek-V3(V2)详读 5 (设施+预训练+后训练)
这个部分涉及 基础设施,预训练,后训练。只是对原文的整理,暂时没有扩展内容。
3. 基础设施
3.1. 计算集群
DeepSeek-V3 训练使用 2048 块 NVIDIA H800 GPU 的集群。每节点有 8 块 GPU,通过 NVLink 和 NVSwitch 互联,节点间通过 InfiniBand(IB)通信。

图 4 | 前向和反向块的重叠策略(transformer 块的边界未对齐)。橙色为前向,绿色为输入反向,蓝色为权重反向,紫色为流水线通信,红色为同步屏障。所有 all-to-all 和流水线通信都能完全隐藏,实现高效计算与通信重叠。
3.2. 训练框架
DeepSeek-V3 基于自研高效轻量级的 HAI-LLM 框架训练,采用 16 路流水线并行(PP)、64 路专家并行(EP,跨 8 节点)和 ZeRO-1 数据并行(DP)。
工程优化包括:
- 设计 DualPipe 算法,显著减少流水线气泡,并让前向与反向计算和通信高效重叠,解决跨节点通信瓶颈;
- 开发高效 all-to-all 通信内核,最大化 IB 和 NVLink 带宽利用,同时节省 SM 资源;
- 精细优化内存占用,无需昂贵的张量并行(TP)即可完成大模型训练。
3.2.1. DualPipe 与计算-通信重叠
跨节点专家并行会导致计算与通信比例低效(约 1:1)。为此,DeepSeek-V3 设计了创新的 DualPipe 流水线并行算法,通过高效重叠前向和反向计算-通信阶段,大幅减少流水线气泡并加速训练。
DualPipe 核心是将每个块细分为 attention、all-to-all dispatch、MLP 和 all-to-all combine 四部分,反向块进一步拆分输入和权重反向。各组件重排、手动分配 GPU 资源,实现计算与通信完全重叠,all-to-all 和 PP 通信可完全隐藏。最终实现双向流水线调度,即便模型更大,只要保持计算-通信比恒定,就能几乎消除通信开销。

图 5 | DualPipe 在 8 个 PP rank 和 20 个 micro-batch 下的调度示例,展示了两个方向的调度。反向 micro-batch 与前向对称,为简明起见省略了其 batch ID。被黑框包围的两个单元格表示它们的计算与通信完全重叠。
| 方法 | 气泡数(Bubble) | 参数量(Parameter) | 激活(Activation) |
|---|---|---|---|
| 1F1B | |||
| ZB1P | |||
| DualPipe(本方法) |
表 2 | 不同流水线并行方法的气泡数和内存使用对比。
表示前向块执行时间, 表示完整反向块执行时间, 表示“权重反向”块执行时间, 表示前向与反向块重叠时的执行时间。
即便在通信压力不大的场景下,DualPipe 依然更高效。表 2 显示,相比 ZB1P 和 1F1B,DualPipe 大幅减少流水线气泡,激活内存峰值仅增加
3.2.2. 跨节点 All-to-All 通信的高效实现
为提升 DualPipe 计算性能,DeepSeek-V3 定制了高效的跨节点 all-to-all 通信内核,结合 MoE 门控和集群网络拓扑,节省了通信所需的 SM 数量。集群内节点间用 InfiniBand(IB)通信,节点内部用 NVLink(带宽是 IB 的 3.2 倍)。我们将每个 token 最多分发到 4 个节点,减少 IB 流量,IB 与 NVLink 通信完全重叠,平均每节点可高效选择 3.2 个专家,通信开销低。
采用 warp specialization 技术,将 20 个 SM 分为 10 个通信通道,分发和合并任务由专用 warp 动态分配,负载均衡。分发与合并内核与计算流重叠,通过定制 PTX 指令和自适应 chunk 大小,降低 L2 缓存压力,减少对其他计算任务的干扰。
3.2.3. 极致省内存且额外开销极低
为降低训练内存占用,DeepSeek-V3 采用多项优化:
- RMSNorm 和 MLA 升投影重计算:反向传播时重算这些操作,无需长时存储激活,显著节省内存,计算开销极小。
- EMA 参数存储在 CPU:模型参数的 EMA 保存在 CPU 内存,异步更新,不增加额外内存或时间成本。
- 多 token 预测的参数共享:在 DualPipe 下,嵌入层和输出头放在同一 PP rank,实现主模型与 MTP 模块参数和梯度的物理共享,进一步提升内存效率。
3.3. FP8 训练
受低精度训练进展启发,DeepSeek-V3 引入细粒度混合精度框架,采用 FP8 数据格式训练。为扩展 FP8 动态范围,我们结合 tile 级和 block 级量化,配合高精度累加,大幅降低反量化开销,实现高效 FP8 GEMM。
为进一步节省内存和通信,激活采用 FP8 存储与调度,优化器状态用 BF16 存储。实验证明,在训练 1 万亿 token 下,FP8 模型相对 BF16 损失误差始终低于 0.25%,优于训练随机性误差。
3.3.1. 混合精度框架
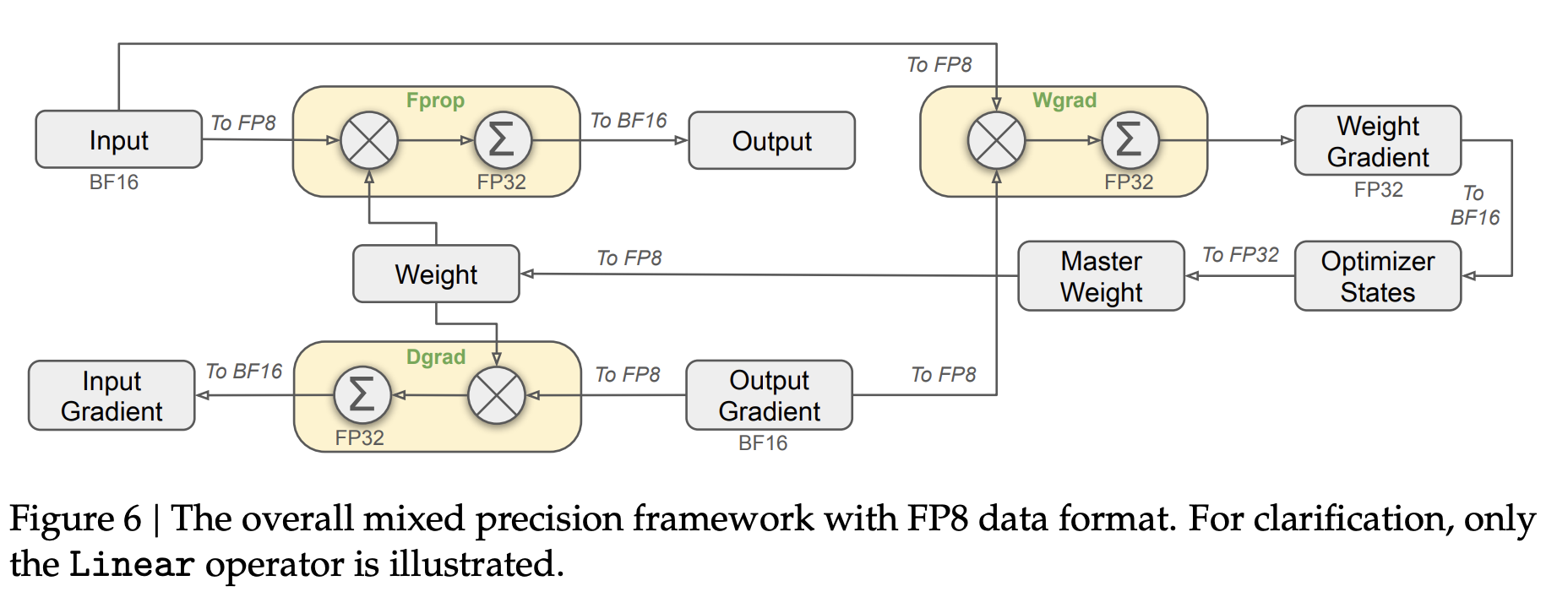
我们提出了一种用于 FP8 训练的混合精度框架,大部分计算密集操作采用 FP8 精度,部分关键操作保留高精度,以兼顾效率与数值稳定性(见图 6)。
为加速训练,核心 GEMM 运算(前向 Fprop、反向激活 Dgrad、权重反向 Wgrad)均用 FP8 实现,输入为 FP8,输出为 BF16 或 FP32。该设计可理论上提升计算速度一倍,并允许激活以 FP8 存储,显著降低显存占用。
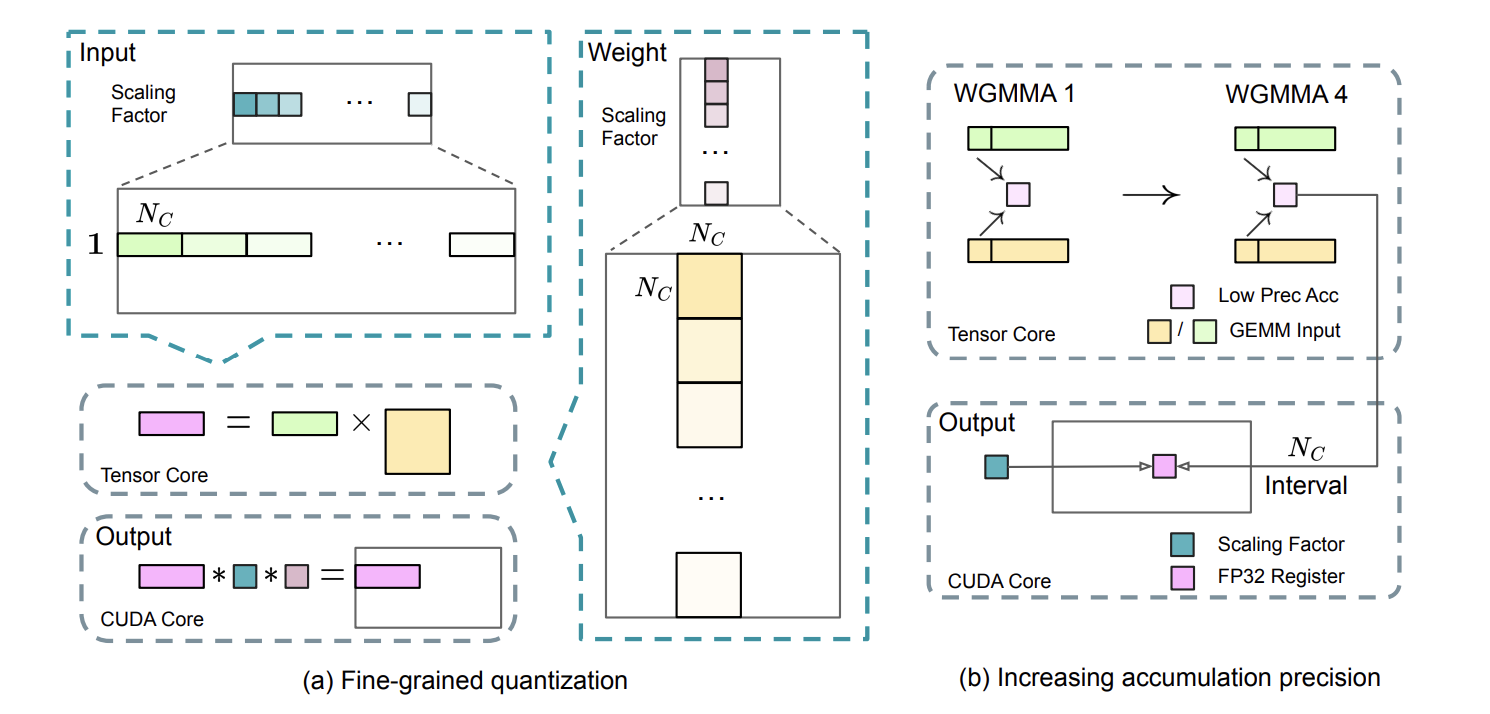
图 7 |(a)我们提出了一种细粒度量化方法,用于缓解特征异常值带来的量化误差;为方便展示,仅以 Fprop 为例。(b)结合我们的量化策略,通过将 FP8 GEMM 在 CUDA 核心上以
元素为间隔进行高精度累加,进一步提升了 FP8 GEMM 的精度。
尽管 FP8 高效,但部分算子对低精度敏感,需保留高精度(BF16/FP32),如嵌入模块、输出头、MoE 门控、归一化、注意力等。这样有助于训练稳定。主权重、权重梯度和优化器状态也都高精度存储,相关显存开销通过跨 DP rank 切分大幅降低,对整体成本影响有限。
3.3.2. 量化与乘法带来的精度提升
我们提出多种策略提升 FP8 低精度训练的准确性,重点优化量化方法和矩阵乘法。
细粒度量化。 FP8 动态范围有限,易因异常值造成量化误差。我们采用更细的分组缩放:激活用 1×128 tile 级分组,权重用 128×128 block 级分组,提升了对异常值的适应能力和量化精度(见图 7(a))。附录 B.2 讨论了激活采用 block 分组时可能引发的不稳定。
此外,在 GEMM 内维引入每组独立缩放因子,结合 FP32 累加方案,高效支持这一细粒度量化。这种方法与 Blackwell 架构 GPU 的微缩放格式高度一致,为适配新一代显卡提供了实践参考。
提升累加精度。 低精度 GEMM 运算易受溢出与下溢影响,训练准确性严重依赖高精度累加(通常为 FP32)。但 H800 GPU 上 FP8 GEMM 累加仅 14 位,K 维较大时误差明显放大,初步实验发现累加精度不足带来近 2% 相对误差。许多 FP8 框架默认低精度累加,限制了训练精度。
为此,我们将累加操作提升到 CUDA Core 的 FP32 精度:在 Tensor Core 执行 MMA 时,每累加
有效尾数优先于有效指数。 与以往用多种 FP8 格式(如 Fprop 用 E4M3,Dgrad/Wgrad 用 E5M2)不同,我们统一用 E4M3 格式以获得更高精度。这依赖于细粒度量化,tile/block 级缩放使同组元素可共享指数位,从而缓解动态范围受限问题。
在线量化。 我们摒弃历史最大值推断缩放因子的延迟量化方案,改为直接在每个 1×128 激活 tile 或 128×128 权重 block 上在线计算最大值,实时得到缩放因子并进行 FP8 量化,简化流程且更精确。
3.3.3. 低精度存储与通信
为降低显存和通信开销,DeepSeek-V3 结合 FP8 框架,将激活和优化器状态压缩至低精度。
低精度优化器状态。 AdamW 优化器的一阶、二阶矩用 BF16 替代 FP32 存储,无性能损失。主权重和累积梯度仍保留 FP32 以保证数值稳定。
低精度激活
- Wgrad 操作及 Linear 反向过程激活值缓存为 FP8。
- Attention 后 Linear 输入用定制 E5M6 格式存储,反向时从 1×128 tile 转为 128×1 tile,缩放因子取 2 的整数幂,减少量化误差。
- MoE 中 SwiGLU 输入缓存为 FP8,反向时重算输出,同样采用细粒度量化,兼顾内存和精度。
低精度通信。 MoE 上采样前的激活量化为 FP8 后 dispatch,缩放因子为 2 的整数幂,与 FP8 Fprop 兼容。MoE 下采样前激活梯度亦如此。前向/反向 combine 操作保留 BF16,确保关键环节精度。
3.4. 推理与部署
DeepSeek-V3 在 H800 集群部署,节点内用 NVLink、节点间用 IB 全互联。为兼顾 SLO 和高吞吐,采用预填充与解码分离策略。
3.4.1. 预填充
- 部署单元:最小为 4 节点(32 GPU)。attention 用 TP4 + SP,结合 DP8,MoE 用 EP32,并采用训练同款 all-to-all 通信。浅层稠密 MLP 用 1 路 TP 节省通信。
- 负载均衡:引入冗余专家,将高负载专家复制、动态分配到不同 GPU,每张 GPU 除原有 8 个专家,还多 1 个冗余专家,共 32 个冗余专家,平衡负载且不明显增加通信。
- 吞吐提升:attention 与 MoE 不同 micro-batch 的操作重叠,提升整体吞吐、隐藏通信开销。
- 动态冗余探索:预分配更多专家,推理时仅激活部分,先算全局最优路由后分配专家,进一步提升负载均衡。
3.4.2. 解码
- 路由策略:共享专家视为高负载路由专家,每 token 选 9 个专家。最小部署单元为 40 节点(320 GPU),attention 用 TP4+SP+DP80,MoE 用 EP320,每 GPU 只托管 1 个专家,64 GPU 专用于冗余与共享专家。dispatch 和 combine 操作全程 IB 直连,配合 IBGDA 降低延迟。
- 负载均衡:定期统计在线负载,动态选冗余专家,但因每 GPU 只托管 1 专家,无需节点内分配调整。探索更细粒度动态冗余需更复杂的全局路由与 kernel 融合。
- 吞吐与资源分配:并行处理两组 micro-batch,attention 与另一组的 dispatch+MoE+combine 操作重叠。MoE 阶段 batch size 小,瓶颈在内存访问,不会影响计算。为不拖慢 attention,只为 MoE 分配极少量 SM 资源。
3.5. 硬件设计建议
针对 DeepSeek-V3 的 all-to-all 通信和 FP8 训练,我们向 AI 芯片厂商提出以下硬件设计建议。
3.5.1. 通信硬件
DeepSeek-V3 通过计算与通信重叠降低了对通信带宽的依赖,但当前的通信实现占用了宝贵的 SM(如 H800 GPU 的 132 个 SM 中需保留 20 个用于通信),限制了计算吞吐量,且让 SM 执行通信任务效率低下。
目前,SM 主要负责:
- 在 IB 和 NVLink 域间转发和聚合数据;
- 在 RDMA 缓冲区和输入/输出缓冲区之间搬运数据;
- 执行 all-to-all combine 的归约操作;
- 管理 chunked 数据在 IB 和 NVLink 域间跨专家传输。
我们建议厂商开发专用硬件协处理器(如 GPU 协处理器或 NVIDIA SHARP)卸载这些通信任务,让 SM 专注于计算。同时,建议新硬件支持统一的编程模型,简化 IB 和 NVLink 的通信操作,支持 computation unit 使用简单原语完成通信操作,并优化 IB-NVLink 域的调度。
3.5.2. 计算硬件
提高 Tensor Core 的 FP8 GEMM 累加精度
目前 NVIDIA Hopper 架构的 Tensor Core 实现下,FP8 GEMM 累加精度有限——仅使用每个尾数乘积最高 14 位,多余位被截断,累加结果也只有 14 位精度。我们的实现通过将 128 次 FP8×FP8 相乘的结果用 CUDA core 的 FP32 精度寄存器累加,部分缓解了这一限制。这有助于 FP8 训练成功,但本质上只是对 Hopper 架构 FP8 GEMM 累加精度缺陷的妥协。未来芯片需提升这一精度。
支持 tile/block 级量化
当前 GPU 仅支持 per-tensor 级别量化,缺乏对 tile/block 细粒度量化的原生支持。现有实现通过频繁将数据从 Tensor Core 移至 CUDA Core,降低了算力利用率。我们建议未来芯片直接支持更细粒度的量化,使 Tensor Core 能处理分组缩放的 MMA 操作,避免数据搬运,提高效率。
支持在线量化
现有实现的在线量化效率低,因频繁读写 HBM 影响性能。我们建议芯片将 FP8 cast 和 TMA 操作合并,直接在激活数据传输时进行量化,减少多次读写。同时,建议支持 warp 级 cast 指令加速流程,提升 layernorm 与 FP8 cast 的融合效率。另一方案是采用 near-memory 架构,将计算逻辑置于 HBM 附近,减少内存访问。
支持转置 GEMM 操作
当前架构将矩阵转置与 GEMM 融合时存在困难。在我们的工作流中,前向激活量化为
4. 预训练
4.1 数据构建
DeepSeek-V3 预训练数据在 DeepSeek-V2 基础上,提升了数学与编程样本比例,扩展多语言覆盖,优化数据处理流程,减少冗余且保证多样性。受 Ding 等人启发,采用文档打包,确保数据完整但不加跨样本注意力掩码。总语料量为 14.8T 高质量分词。
引入 Fill-in-Middle(FIM)策略,采用前缀-后缀-中间(PSM)数据框架(格式:<|fim_begin|>f_pre<|fim_hole|>f_suf<|fim_end|>f_middle<|eos_token|>),文档级应用,FIM 占比 0.1。
分词器升级为基于字节的 BPE,词表扩展至 128K,优化多语言压缩,并引入标点+换行符组合 token。为减缓 token 边界偏差,训练时随机拆分部分组合 token,使模型能适应多行和特殊情况。
4.2 超参数
模型超参数
- Transformer 层数:61,隐藏维度:7168,参数初始化标准差:0.006
- MLA:注意力头数
,单头维度 - KV 压缩维度
,query 压缩 ,解耦 query/key 头 - 除前 3 层外,FFN 全为 MoE,每层含 1 个共享专家和 256 路由专家,专家中间隐藏 2048
- 每 token 激活 8 个专家,最多路由到 4 个节点
- 多 token 预测深度
- 增加 RMSNorm 层和缩放因子,总参数 671B,每 token 激活 37B 参数
训练超参数
- 优化器:AdamW,
, ,weight_decay=0.1 - 最大序列长度 4K,训练 14.8T token
- 学习率:前 2K 步线性增至
,10T token 保持不变,后 4.3T 余弦衰减至 ,最后 500B 阶段降至 - 梯度裁剪阈值 1.0,batch size 从 3072 增至 15360
- 各层路由专家分布于 8 节点、64 GPU,token 最多路由 4 节点
- bias 更新速率
:前 14.3T 为 0.001,后 500B 为 0 - balance loss
,MTP loss 权重 :前 10T 为 0.3,后 4.8T 为 0.1,最后 500B 为 0。
4.3 长上下文扩展
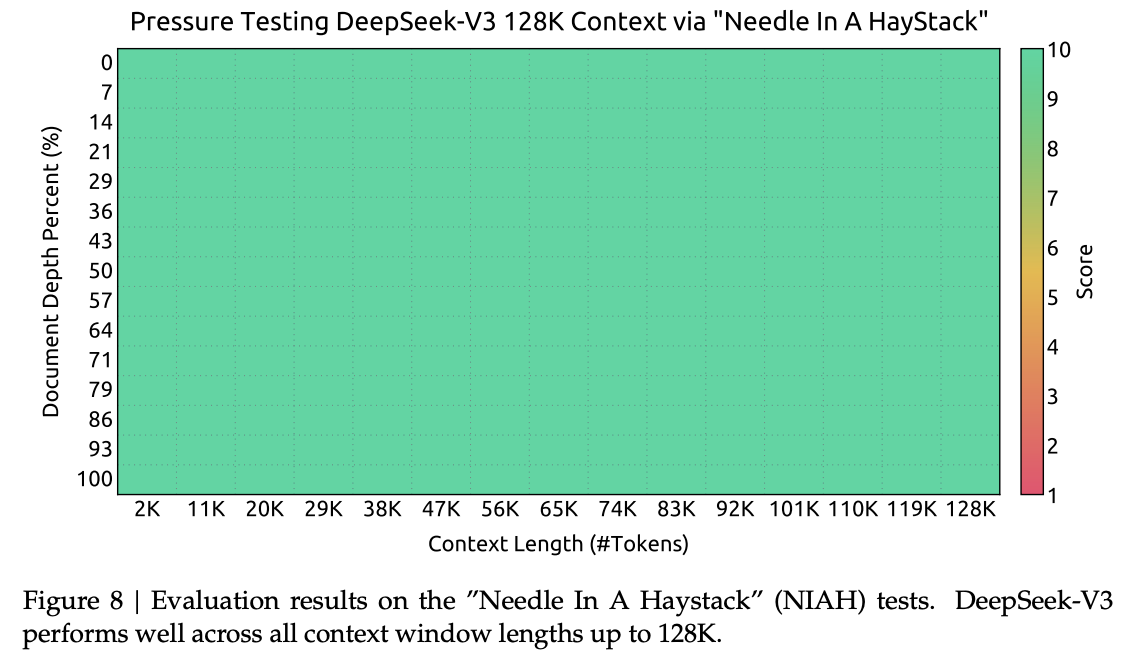
DeepSeek-V3 采用与 V2 类似的策略,通过 YaRN(Peng et al., 2023a)分两阶段扩展上下文长度:每阶段 1000 步,将窗口从 4K 扩展到 32K,再到 128K,配置与 V2 保持一致,仅作用于解耦共享 key。两阶段超参数:
这种双阶段训练让 DeepSeek-V3 支持最长 128K 上下文,并在 NIAH 测试中保持高性能和强健性。
4.4. 评测
4.4.1. 评测基准
DeepSeek-V3 基础模型在多语言(以中英文为主)语料上预训练,评测覆盖中英文及多语言基准,评测体系集成于 HAI-LLM 框架。基准分为:
- 多学科多选题:MMLU、MMLU-Redux、MMLU-Pro、MMMLU、C-Eval、CMMLU
- 语言理解与推理:HellaSwag、PIQA、ARC、BBH
- 封闭式问答:TriviaQA、NaturalQuestions
- 阅读理解:RACE、DROP、C3、CMRC
- 指代消解:CLUEWSC、WinoGrande
- 语言建模:Pile
- 中文理解与文化:CCPM
- 数学:GSM8K、MATH、MGSM、CMath
- 代码:HumanEval、LiveCodeBench-Base、MBPP、CRUXEval
- 标准化考试:AGIEval(含中英文子集)
评测方式:多数采用困惑度,阅读理解、代码、数学等采用生成式评测。Pile 上用 BPB 衡量,保证 tokenizer 公平性。
4.4.2. 评测结果
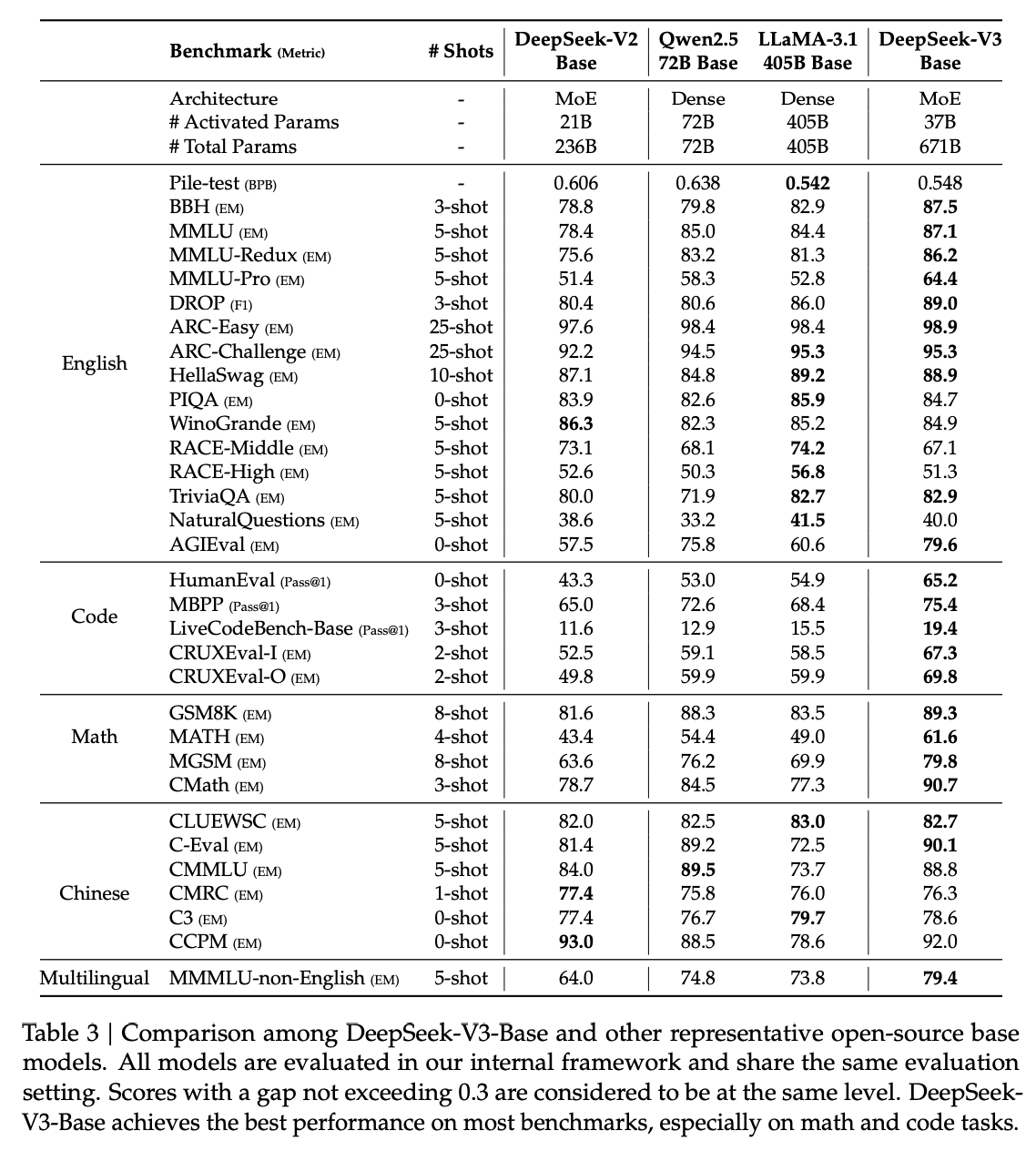
表 3 展示 DeepSeek-V3 Base 与主流开源基础模型(DeepSeek-V2-Base、Qwen2.5 72B Base、LLaMA-3.1 405B Base)的对比,均在相同评测框架下测试。总体上,DeepSeek-V3-Base 在绝大多数基准上全面超越 DeepSeek-V2-Base 和 Qwen2.5 72B Base,并在多项基准上超过参数量大约 11 倍的 LLaMA-3.1 405B Base,成为最强开源基础模型。
具体亮点:
- 相较 DeepSeek-V2-Base,结构、规模、数据全面升级,性能大幅提升。
- 面对 Qwen2.5 72B Base,即使激活参数仅一半,DeepSeek-V3-Base 在英多语、代码、数学评测表现更佳,中文评测也大多胜出。
- 对比 LLaMA-3.1 405B Base,DeepSeek-V3-Base 在多语种、代码、数学表现更优。
整体来看,DeepSeek-V3-Base 在 BBH、MMLU、DROP、C-Eval、CMMLU、CCPM 等评测中尤其突出。 凭借高效架构与优化,每万亿 token 仅需 18 万 H800 GPU 小时,训练成本远低于同级大模型。
4.5. Discussion
4.5.1. 多 Token 预测(MTP)消融实验
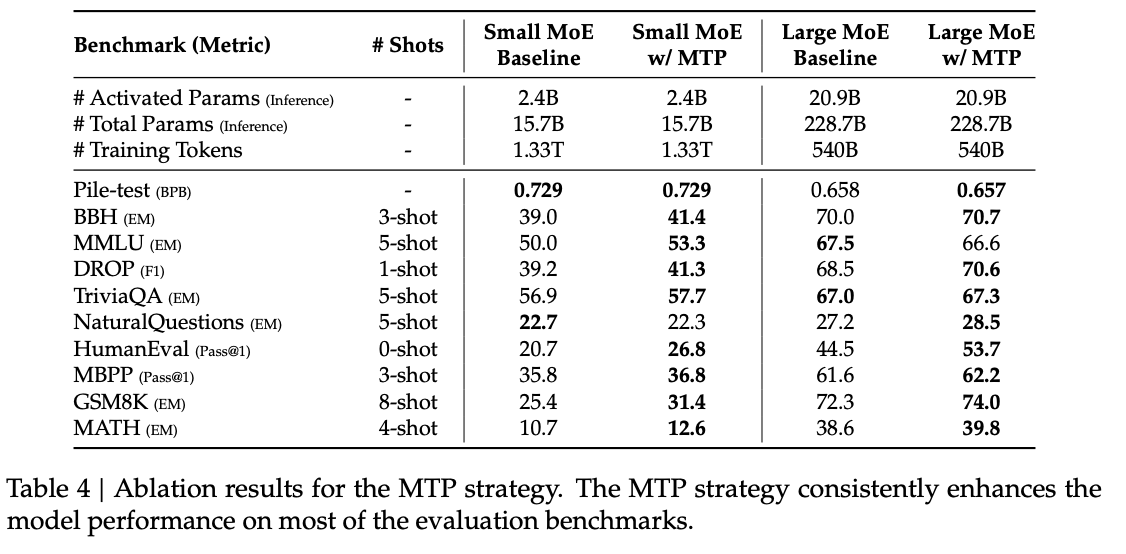
表4展示了 MTP 策略在两个不同规模基线模型上的消融实验:小模型(157亿参数,1.33万亿token)、大模型(2287亿参数,5400亿token)。结构和数据一致,仅加入深度为1的MTP模块。推理时MTP模块被舍弃,推理成本不变。结果显示,MTP 能在大多数基准上持续提升模型表现。
4.5.2. 无辅助损失负载均衡消融实验
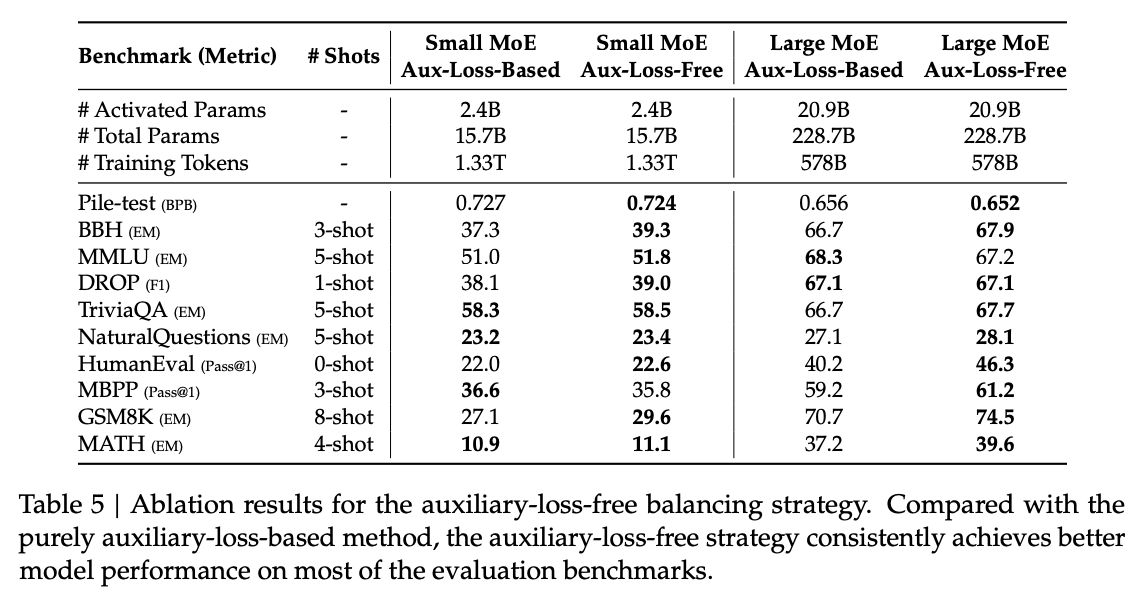
表5展示了无辅助损失负载均衡策略在同两组基线模型上的对比。与仅用辅助损失的基线(sigmoid门控+top-K归一化,超参数同DeepSeek-V2-Lite/V2)相比,移除辅助损失,改为无辅助损失策略后,多数评测基准表现更优。
4.5.3. 批量负载均衡 vs. 序列负载均衡
- 批量辅助损失更灵活,仅约束整体 batch,不强制每个序列平衡,有助于专家在不同领域专精。实验证明,辅助损失自由(auxiliary-loss-free)模型展现更强专家专精。
- 引入批量级辅助损失(鼓励每个 batch 内负载均衡),实验显示与无辅助损失方法表现相近,均优于序列辅助损失。
- 验证损失(1B MoE):序列辅助损失 2.258,辅助损失自由 2.253,批量辅助损失 2.253。3B MoE:分别为 2.085 和 2.080。
- 虽然批量负载均衡在性能上更优,但也带来:① 某些小批次负载不均;② 推理时领域迁移负载不均。前者通过大规模并行自然缓解,后者可用冗余专家部署优化(见 3.4 节)。
5. 后训练
5.1. 监督式微调
- 构建包含 150 万条多领域指令微调数据集,每领域采用不同生成策略。
- 推理数据:数学、代码、逻辑题等数据由 DeepSeek-R1 生成,虽准确但有格式/冗长等问题。为此,先用专家模型(SFT+RL 训练)作为数据生成器,生成两种 SFT 样本(原始答案/系统提示+R1答案)。系统提示引导模型生成结构化回答。RL 阶段让模型融合 R1 风格,后用拒绝采样筛高质量样本,保证数据既简洁又有 R1 优势。
- 非推理数据:如创意写作、问答等由 DeepSeek-V2.5 生成,人工审核确保质量。
- SFT 设置:DeepSeek-V3-Base 用 SFT 数据集分两轮微调,学习率 5×10⁻⁶ 余弦降到 1×10⁻⁶。训练时样本拼接,但用屏蔽策略确保样本间相互不可见。
5.2 强化学习
5.2.1 奖励模型
- 基于规则的奖励模型(Rule-Based RM)
针对可规则验证的问题(如数学题、LeetCode),要求模型输出指定格式便于自动校验,确保高可靠性,不易被利用。 - 基于模型的奖励模型(Model-Based RM)
针对开放式/主观题(如创意写作),使用奖励模型判定回复与标准答案或偏好一致性。奖励模型基于 DeepSeek-V3 SFT 检查点训练,偏好数据同时含最终奖励与推理链,以提升鲁棒性,防止被攻击。
5.2.2. 群组相对策略优化(Group Relative Policy Optimization, GRPO)
类似于 DeepSeek-V2,我们采用群组相对策略优化(GRPO)。该方法摒弃了通常与策略模型等规模的critic模型,而用群组分数估计基线。具体来说,对于每个问题
其中,KL 散度项为:
其中,
我们在 RL 过程中引入了来自代码、数学、写作、角色扮演和问答等多领域的提示。这种方法不仅使模型更贴近人类偏好,也能在有监督微调数据有限的情况下提升基准任务表现。
5.3 评估
5.3.1. 评测设置
- 评测基准:除基础测试外,还在 IFEval、FRAMES、LongBench v2、GPQA、SimpleQA、C-SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench(2024年8-11月)、Codeforces、高中数学奥赛(CNMO 2024)、AIME 2024 等多数据集上评测。
- 对比基线:对比 DeepSeek-V2-0506、V2.5-0905、Qwen2.5 72B Instruct、LLaMA-3.1 405B Instruct、Claude-Sonnet-3.5-1022、GPT-4o-0513 等主流开源/闭源模型,闭源模型通过官方API评测。
- 评测配置:MMLU、DROP、GPQA、SimpleQA 用 simple-evals 标准提示词,MMLU-Redux 用 Zero-Eval 格式(zero-shot),其他用官方协议和默认提示词。
- 代码与数学基准:HumanEval-Mul 涵盖 8 种主流编程语言。LiveCodeBench 用 CoT 和 non-CoT 两种方法,Codeforces 以选手百分比为指标,SWE-Bench Verified 用 agentless 框架,Aider 基准用 diff 格式。
- 数学评测:AIME、CNMO 2024 温度 0.7,结果为 16 次平均,MATH-500 用贪婪解码。所有模型每个 benchmark 最多输出 8192 个 token。
5.3.2. 标准评估
- 评测基准:除基础评测外,新增 IFEval、FRAMES、LongBench v2、GPQA、SimpleQA、C-SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench(2024年8-11月题)、Codeforces、CNMO 2024、AIME 2024 等。
- 对比基线:DeepSeek-V2-0506、DeepSeek-V2.5-0905、Qwen2.5 72B Instruct、LLaMA-3.1 405B Instruct、Claude-Sonnet-3.5-1022、GPT-4o-0513(闭源模型用 API 测试)。
- 评测细节:
- MMLU、DROP、GPQA、SimpleQA 用 simple-evals 框架;MMLU-Redux 用 Zero-Eval zero-shot 设置。
- 代码和数学:HumanEval-Mul 覆盖 8 种语言;LiveCodeBench 用 CoT 与非CoT,Codeforces 按参赛百分比评测,SWE-Bench 用 agentless,Aider 用 diff 格式。
- 数学测试:AIME、CNMO 温度 0.7,取 16 次均值,MATH-500 用贪婪解码。所有模型单次输出最长 8192 tokens。
- 代码&数学结果:
- 工程类任务(如 SWE-Bench)DeepSeek-V3 略逊于 Claude-Sonnet-3.5-1022,但明显优于开源模型,对开源代码模型进步有推动意义。
- 算法类任务(如 HumanEval、LiveCodeBench)DeepSeek-V3 全面领先对比模型,得益于知识蒸馏提升代码生成与解题能力。
- 数学基准(AIME、MATH-500、CNMO 2024)DeepSeek-V3 均领先 Qwen2.5-72B 约 10 个百分点,体现了 DeepSeek-R1 蒸馏的强大作用。
- 中文基准:
- SimpleQA 上 DeepSeek-V3 比 Qwen2.5-72B 高出 16.4 分。
- C-Eval、CLUEWSC 等高难度中文任务两者表现相近,说明两款模型在中英任务均有极强优化。
5.3.3. 开放式任务评测
- DeepSeek-V3 在开放式生成任务(如 AlpacaEval 2.0、Arena-Hard,裁判为 GPT-4-Turbo-1106)中表现卓越。
- Arena-Hard 上,V3 胜率超 86%,与 Claude-Sonnet-3.5-1022 等顶级模型相当,是首个开源模型突破 85% 胜率,显著缩小开源与闭源差距。
- AlpacaEval 2.0 上,DeepSeek-V3 胜率也领先于闭源/开源竞品,尤其在写作和简单问答场景表现突出,比 V2.5-0905 高 20%。
5.3.4. DeepSeek-V3 作为生成式奖励模型
- DeepSeek-V3 作为奖励模型,在 RewardBench 基准下,与 GPT-4o-0806、Claude-3.5-Sonnet-1022 水平持平,优于其他版本。
- 利用投票等技术,V3 的判断能力可进一步提升,因此支持自我反馈和对齐,增强奖励过程的有效性与稳健性。
5.4. 讨论
5.4.1. 来自 DeepSeek-R1 的蒸馏
- 消融实验表明,DeepSeek-R1 蒸馏数据显著提升了 LiveCodeBench 和 MATH-500 表现,但也增加了平均响应长度。V3 训练时精心权衡性能和效率。
- 蒸馏优化后训练是有前景方向,尤其对复杂推理任务如数学和编程领域。未来将拓展至更多任务领域。
5.4.2. 自我奖励(Self-Rewarding)
- RL 奖励关键,某些领域如编程/数学可用外部工具直接验证。但通用场景需 LLM 自身评判。
- DeepSeek-V3 采用“宪法式 AI”方法,利用模型自身投票输出作反馈,有效提升了主观评估表现。
- 结合宪法式指令,模型可更好对齐预期方向。未来还将继续探索更通用、可扩展的奖励机制以推动模型持续进步。
5.4.3. 多Token预测评估
- DeepSeek-V3 使用多Token预测(MTP)技术,每次直接预测下两个 token,结合 speculative decoding,显著加快解码速度。
- 第二个 token 的接受率达 85%~90%,多场景下表现稳定可靠,使 TPS 提升至 1.8 倍。
6. 结论、局限性与未来方向
- DeepSeek-V3 是 671B MoE 大模型,激活参数 37B,训练数据 14.8T tokens。首创无辅助损失负载均衡和多Token预测目标,结合 MLA、DeepSeekMoE 架构,训练成本效益高(总计 2.788M H800 GPU 小时)。
- 后训练蒸馏了 DeepSeek-R1 推理能力,性能媲美 GPT-4o、Claude-3.5-Sonnet 等闭源模型,是最强开源模型之一。
- 局限性:推理资源需求高、部署单元较大,对小规模系统有压力;推理速度虽提升两倍,仍有优化空间。
- 展望:硬件升级有望进一步解决部署和速度限制。
- DeepSeek 坚持开源、长期主义,致力于迈向 AGI。未来战略方向包括:
- 持续优化模型架构,提升训练与推理效率,实现更高效的无限上下文支持,尝试突破 Transformer 限制。
- 改进训练数据量与质量,拓展多样化训练信号来源,覆盖更广泛领域。
- 深化模型的推理和思考能力,提升智能水平和问题解决深度。
- 推动更全面多维的模型评估,避免过度优化单一基准,准确反映模型基础能力。
参考资料
- DeepSeek AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv:2405.04434
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437
- Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., & Liu, Y. (2024). A Survey on Mixture of Experts in Large Language Models. arXiv preprint. arXiv:2407.06204
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint. arXiv:2101.03961
- Zhou, Y., Lei, T., Du, H., Huang, L., & Zhao, J. (2024). Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts. arXiv preprint. arXiv:2408.15664v1
- Z. Lu and W. Xia, "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity," COS597G Lecture 16, Princeton University, 2022. Online. Available: COS597G Lecture 16
- F. Glacial, A. B. Author2, and C. D. Author3 (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint. arXiv:2404.19737
- Y. Leviathan, M. Kalman, and Y. Matias (2023). Fast Inference from Transformers via Speculative Decoding. arXiv preprint. arXiv:2211.17192
- K. Zhang, J. Zhao, and R. Chen, (2024). KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning. arXiv preprint. Available: arXiv:2408.08146
- Transformers KV Caching Explained: How caching Key and Value states makes transformers faster
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part1 | 开源最强模型 | 性价比之王
- EZ撸paper: DeepSeek-V3 技术报告详细解读 part2 | 开源最强模型 | 性价比之王的核心技术MLA
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part3 | 可能存在的问题
- EZ撸paper: DeepSeek-V3 论文中的隐藏细节 part4 | 从入门到精通DeepSeek MTP
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付