9. RAFT(RAG + SFT):让LLM更聪明地做领域特定 RAG
RAFT(RAG + SFT)
1. 背景与问题
大语言模型(LLM)在通用知识推理上已经非常强,但在专业领域(医疗、法律、企业文档等)里,单靠预训练的“常识”并不够。通常有两条路来注入领域知识:
- RAG(检索增强生成):推理时调用检索器,给 LLM 提供相关文档参考。
- 微调(Fine-tuning):直接用领域数据训练,让模型“学”到相关知识。
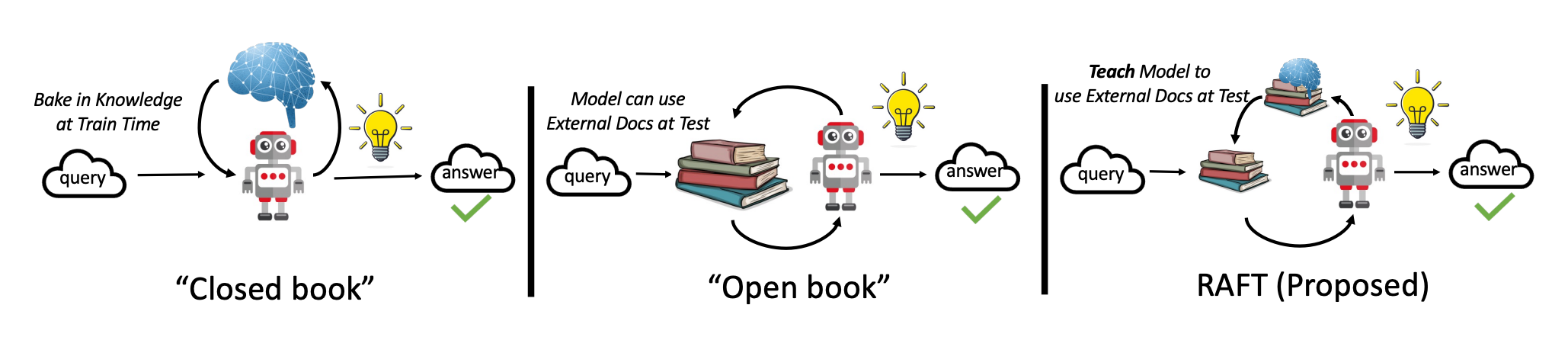
问题在于:
- 纯 RAG:像“开卷考试不复习”,模型不会利用提前可得的领域文档来训练自己。
- 纯微调:像“闭卷考试刷题”,没学会如何在推理时有效利用外部文档,容易被检索器的噪声误导。
RAFT(Retrieval-Augmented Fine-Tuning) 就是要结合二者优点:既让模型学会领域知识,又训练它识别干扰信息,提高领域内 RAG 表现。
2. RAFT 方法核心
RAFT 的训练目标是模拟 领域特定的开卷考试,让模型学会:
- 从检索到的文档中找到关键信息(Golden Document)。
- 忽略无关或误导性信息(Distractor Documents)。
- 用 Chain-of-Thought(CoT)推理,并引用原文支持结论。
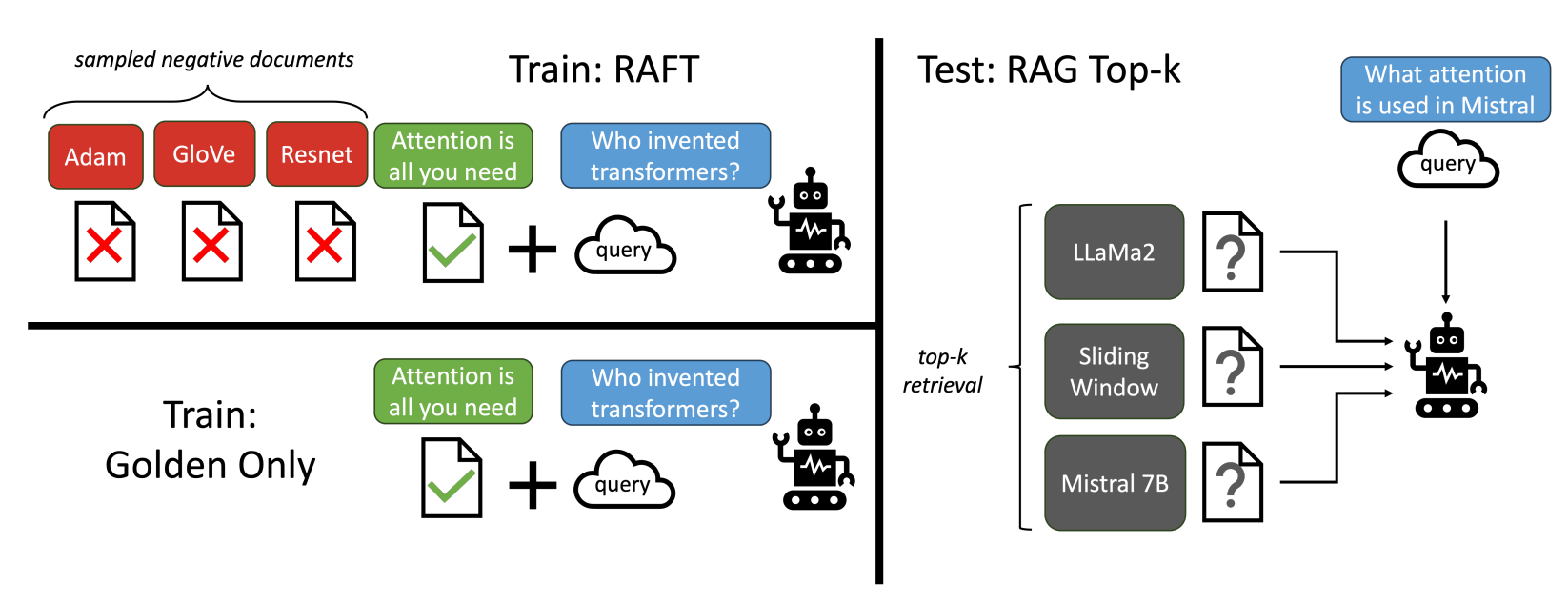
2.1 训练数据构造
对每个训练样本,准备:
:问题(Question) :黄金文档(Golden Document,包含答案) :干扰文档(Distractor Documents) :带推理链(Chain-of-Thought, CoT)的答案,并引用原文( ##begin_quote##…##end_quote##),然后给出详细推理过程。
数据混合策略:
的样本: 的样本: (无黄金文档,强迫模型依靠记忆回答)
这样既训练了利用上下文的能力,又保留了直接回答的能力。
3. 理论部分
在经典的监督微调(Supervised Fine-Tuning, SFT)中,训练与推理可表示为:
在 RAFT 中,训练集包含两种形式:
- 对于
的样本(包含黄金文档 ):
- 对于
的样本(无黄金文档,仅干扰文档):
在实验中,还引入了干扰文档数量
:训练集中包含黄金文档的比例,取值范围 :每个样本中提供的干扰文档数量(不含黄金文档)
4. 实验设计
-
数据集
- 通用领域:Natural Questions、TriviaQA、HotpotQA
- 代码/API:HuggingFace Hub、Torch Hub、TensorFlow Hub(来自 Gorilla APIBench)
- 医疗领域:PubMedQA
-
对比方法
- LLaMA2-7B(0-shot 与 RAG)
- DSF(Domain-Specific Fine-tuning)(有/无 RAG)
- RAFT(本方法)
- GPT-3.5+RAG(参考上限)
5. 实验结果
表 1:主要结果(准确率
| 模型 | PubMed | Hotpot | HuggingFace | Torch Hub | TensorFlow |
|---|---|---|---|---|---|
| LLaMA2-7B | 56.50 | 0.54 | 0.22 | 0.00 | 0.00 |
| LLaMA2-7B+RAG | 58.80 | 0.03 | 26.43 | 8.60 | 43.06 |
| DSF | 59.70 | 6.38 | 61.06 | 84.94 | 86.56 |
| DSF+RAG | 71.60 | 4.41 | 42.59 | 82.80 | 60.29 |
| GPT-3.5+RAG | 71.60 | 41.50 | 29.08 | 60.21 | 65.59 |
| RAFT (LLaMA2-7B) | 73.30 | 35.28 | 74.00 | 84.95 | 86.86 |
亮点:
- HotpotQA 提升高达 +30.87%(相对 DSF)
- HuggingFace 提升 +31.41%
- 部分任务超过 GPT-3.5+RAG
- PubMedQA 与 DSF+RAG 差距不大(因任务是二分类)
6. 关键实验发现
-
Chain-of-Thought(CoT)重要性
- 不加 CoT → HotpotQA:
- 加 CoT → HotpotQA:
- 加 CoT → HuggingFace 提升 +14.93%
- 不加 CoT → HotpotQA:
-
黄金文档比例
- 最优比例不是
! - 不同数据集最佳
- NQ:40%
- TriviaQA:60%
- HotpotQA:100%
- 原因:部分样本不提供黄金文档,能提升模型的记忆与泛化能力
- 最优比例不是
-
干扰文档数量
- 训练中混入干扰文档能显著提升模型在测试时应对 top-k 检索结果的鲁棒性
- 如 NQ 最佳是
干扰,HotpotQA 最佳是 干扰
7. 总结与意义
RAFT 的贡献:
- 结合 RAG 与微调优势,让 LLM 真正学会在特定领域做“开卷考试”。
- 训练中引入干扰文档,显著提升抗噪能力。
- 混合黄金/非黄金文档,增强模型的推理与记忆能力。
- 在多个专业领域任务中大幅超越 DSF 与 GPT-3.5+RAG。
代码开源:github.com/ShishirPatil/gorilla
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
9. RAFT(RAG + SFT):让LLM更聪明地做领域特定 RAG
http://neurowave.tech/2025/06/29/11-9-RAFT/