RAG(检索增强生成)基础
1. 背景
大模型应用开发的三种模式,在选择使用哪种模式时,需要考虑 知识实时性、专业深度 以及 模型幻觉控制:
- Prompt(提示词工程) – 问题没问清楚
- 通过精心设计提示词,引导大模型生成期望输出。
- RAG(Retrieval-Augmented Generation) – 缺乏背景知识
- 结合信息检索与文本生成,实时检索外部知识增强生成能力。
- Fine-tuning(微调) – 模型能力不足
- 用特定领域数据微调预训练模型,使其更适配任务。
快速搭建本地知识库:
- 无代码轻量平台:
dify、coze- 有技术团队:
LangChain+Llama-Index
2. RAG 技术概览
RAG(Retrieval-Augmented Generation)是一种结合了信息检索+文本生成的技术,它通过实时检索相关文档或信息,并将其作为上下文输入到大模型中,从而提升生成内容的时效性和准确性。
2.1 RAG 的优势
- 解决知识时效性问题:大模型的训练数据通常是静态的,无法涵盖最新信息,而RAG可以实时检索外部知识库,确保信息是最新、最准确的。
- 减少模型幻觉:通过引入外部知识,RAG能有效减少模型生成虚假或不准确内容的可能性。
- 提升专业领域回答质量:RAG能够结合垂直领域的专业知识库,生成更具深度和专业性的回答。
- 支持内容溯源:RAG生成的内容可以追溯到原始文档,增强了答案的可信度(即可解释性)。
2.2 核心原理和流程
Step 1:数据预处理,构建索引库
- 知识库构建:收集和整理来自文档、网页、数据库等多种来源的数据。
- 文档分块:将文档切分成大小适中的文本片段(chunks)。分块策略需要在语义完整性与检索效率之间取得平衡。
- 向量化处理:使用嵌入模型(如 BGE, M3E, Chinese-Alpaca-2 等)将文本块转换为向量,并存储在向量数据库中。
- 收集多源数据 → 切分文档 chunk → 嵌入向量 → 写入向量库
Step 2:检索阶段
- 查询处理:将用户输入的问题转换为向量,然后在向量数据库中进行相似度检索,找到与问题最相关的文本片段。
- 重排序:对检索到的结果进行相关性排序,选出最相关的片段作为生成阶段的输入。
- 将用户 Query 嵌入向量 → 相似度检索 → 重排序
Step 3:生成阶段
- 上下文组装:将检索到的文本片段与用户问题结合,构建成一个增强的上下文输入。
- 生成回答:大模型基于这个增强的上下文生成最终的回答。
- 组装检索片段 + Query → LLM 生成回答
划重点:RAG 本质就是构造了一个更强大的 Prompt!
3. Native RAG 三步曲
| 阶段 | 关键问题 | 难点 |
|---|---|---|
| Indexing | 如何更好地把知识存起来 | 分块策略、向量化模型 |
| Retrieval | 如何精准检索少量有用知识 | 相似度计算、重排序 |
| Generation | 如何让模型用好检索结果 | Prompt 构建、模型优化 |
4. LangChain快速搭建本地知识库检索
4.1. 环境准备
- 本地安装好 Conda 环境
- 推荐使用 ChatGPT 或者 阿里百炼
- 百炼平台使用
- 注册登录
- 申请api key
依赖安装:pip下面这些包到conda,pypdf2,dashscope,langchain ,langchain-openai,langchain-community,faiss-cpu,推荐Python 3.10
4.2. 搭建流程
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
4.3 RAG 代码实现流程
-
加载 PDF 文件并提取文本与页码 →
PyPDF2.PdfReader和extract_text_with_page_numbers(pdf)- 作用: 读取 PDF 文件,从每一页中提取文本内容,并记录每行文本的原始页码,便于后续结果溯源。
-
处理文本并创建向量存储 →
process_text_with_splitter(text, page_numbers, save_path)- 文本分块 →
RecursiveCharacterTextSplitter(separators=["\n\n", "\n", ".", " ", ""], chunk_size=512, chunk_overlap=128)- 作用: 将长文本分割成小块(chunks),便于后续向量化和检索,同时设置重叠保证上下文连续性。
- 创建嵌入模型 →
DashScopeEmbeddings(model="text-embedding-v2")(或OpenAIEmbeddings())- 作用: 初始化文本嵌入模型,将文本块转为向量表示。
- 向量化存储 →
FAISS.from_texts(chunks, embeddings)- 作用: 使用 FAISS 向量数据库存储文本向量,支持高效相似度检索。
- 存储页码信息 →
knowledgeBase.page_info = page_info及pickle.dump(page_info, f)- 作用: 将每个文本块对应的页码信息存储在
knowledgeBase对象中,并可选地保存到本地文件系统,实现查询结果的溯源。
- 作用: 将每个文本块对应的页码信息存储在
- 文本分块 →
-
加载本地知识库 →
load_knowledge_base(load_path, embeddings)- 作用: 从本地路径加载已保存的 FAISS 向量数据库及相关页码信息。
-
检索增强生成 (RAG):
- 相似度搜索 →
docs = knowledgeBase.similarity_search(query)- 作用: 根据用户输入的查询
query,在向量数据库中查找语义最相似的文档片段docs。
- 作用: 根据用户输入的查询
- 初始化大语言模型 →
ChatOpenAI(...)(或Tongyi(...))- 作用: 初始化对话型大模型,用于后续生成回答。
- 加载问答链 →
chain = load_qa_chain(chatLLM, chain_type="stuff")- 作用: 构建一个问答链,将检索到的文档作为上下文与用户问题结合,引导大语言模型生成回答。
- 执行问答链 →
response = chain.invoke(input={"input_documents": docs, "question": query})- 作用: 运行问答链,生成基于检索结果的答案。
- 成本跟踪 →
with get_openai_callback() as cost:- 作用: 监控 API 调用的成本。
- 相似度搜索 →
-
结果溯源:
- 显示来源页码 →
source_page = knowledgeBase.page_info.get(text_content.strip(), "未知") - 作用: 从
knowledgeBase中获取每个检索到的文档片段对应的原始页码,并打印出来,实现答案的溯源。
- 显示来源页码 →
pdf 文本分块,向量化存储,保存+加载向量数据库及页码信息,测试输出:
1 | |
处理文本并创建知识库,同时保存到磁盘,测试输出:
1 | |
设置查询问题,检索增强生成(RAG),测试输出:
1 | |
通过Tongyi做结果溯源(显示来源页码),测试输出:
1 | |
5. 三大阶段有效提升RAG质量方法
5.1 数据准备阶段
常见问题
- 数据质量差:企业数据(尤其是非结构化数据)缺乏治理,未标记/评估的数据可能包含敏感、过时、矛盾或错误的信息。
- 多模态信息挑战:难以准确提取+理解文档中的标题、配色、图像、标签等不同元素。
- 复杂PDF提取:PDF格式为人类阅读设计,机器解析难度大。
如何提升数据准备阶段的质量?
-
构建完整的数据准备流程(数据部门做,提升数据质量)
- 数据评估与分类
- 数据审计:全面审查现有数据,识别敏感、过时、矛盾或不准确的信息。
- 数据分类:按类型、来源、敏感性和重要性来分类
- 数据清洗
- 去重:删除重复数据
- 纠错:修正格式错误、拼写错误等
- 更新:替换过时信息,确保数据时效性
- 一致性检查:解决数据矛盾,确保逻辑一致
- 敏感信息处理
- 识别敏感数据:使用工具或正则表达式识别敏感信息,如个人身份信息
- 脱敏或加密:对敏感数据进行脱敏处理,确保合规。
- 数据标记与标注
- 元数据标记:为数据添加元数据,如来源、创建时间等
- 内容标注:对非结构化数据进行标注,便于后续检索和分析
- 数据治理框架
- 制定政策:明确数据管理、访问控制和更新流程
- 责任分配:指定数据治理负责人,确保政策执行
- 监控与审计:定期监控数据质量,进行审计
- 数据评估与分类
-
智能文档技术(针对复杂的pdf )
- 利用智能文档技术提升多模态和复杂结构文档的数据处理效率
- 阿里文档智能:阿里云 DocMind
- 微软 LayoutLMv3:LayoutLMv3 介绍
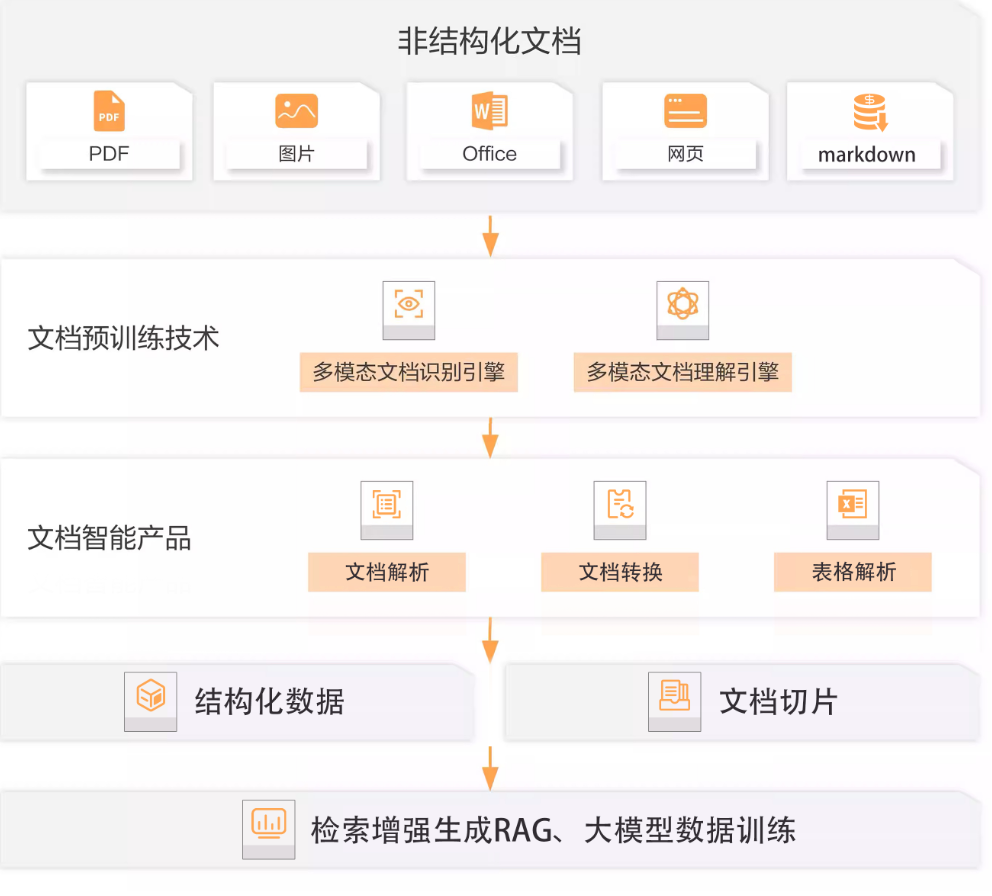
- 利用多模态文档识别+理解引擎,然后文档解析成doc tree,txt。
- RagFlow底层使用OCR技术对pdf识别很好
- 利用智能文档技术提升多模态和复杂结构文档的数据处理效率
5.2. 知识检索阶段
常见问题
- 内容缺失:检索过程未覆盖关键内容,导致系统提供的答案不完整或碎片化,直接拉低 RAG 质量。
- 错过排名靠前的文档:
- 检索时相关文档虽被找到,但排名过低或未被选中(只召回 top k),导致高相关内容未被利用,最终答案无法满足需求。
- 由于 top k 设置依赖经验,理论上应排序全量文档,但实际只用少数文档,增加了漏查风险。
- 不在上下文中:
- 检索到了包含答案的文档,但这些内容未被纳入最终上下文,导致生成答案时遗漏关键信息。
- 常发生在召回文档过多、上下文窗口有限时,需进一步筛选和整合相关片段。
如何提升知识检索阶段的质量?
-
通过查询转换澄清用户意图:明确用户意图,提高检索准确性。
- 场景:用户询问 “如何申请信用卡?”
- 问题:用户意图可能模糊,例如不清楚是申请流程、所需材料还是资格条件。
- 解决方法:通过查询转换明确用户意图。
- 实现步骤:
- 意图识别:使用自然语言处理技术识别用户意图。例如,识别用户是想了解流程、材料还是资格。
- 查询扩展:根据识别结果扩展查询。例如:
- 如果用户想了解流程,查询扩展为“信用卡申请的具体步骤”
- 如果用户想了解材料,查询扩展为“申请信用卡需要哪些材料”
- 如果用户想了解资格,查询扩展为“申请信用卡的资格条件”
- 检索:使用扩展后的查询检索相关文档
- 示例:
1. 用户输入:“如何申请信用卡?”
2. 系统识别意图为流程,扩展查询为信用卡申请的具体步骤
3. 检索结果包含详细的申请步骤文档,系统生成准确答案
-
采用混合检索和重排策略:确保最相关的文档被优先处理,生成更准确的答案。
- 场景:用户询问“信用卡年费是多少?”
- 问题:直接检索可能返回大量文档,部分相关但排名低,导致答案不准确。
- 解决方法:采用混合检索和重排策略。
- 步骤:
- 混合检索:结合关键词检索和语义检索。比如:关键词检索:“信用卡年费”。
- 语义检索:使用嵌入模型检索与“信用卡年费”语义相近的文档。
- 重排:对检索结果进行重排。
- 生成答案:从重排后的文档中生成答案。
- 示例:
- 用户输入:“信用卡年费是多少?”
- 系统进行混合检索,结合关键词和语义检索。
- 重排后,最相关的文档(如“信用卡年费政策”)排名靠前。
- 系统生成准确答案:“信用卡年费根据卡类型不同,普通卡年费为100元,金卡为300元,白金卡为1000元。”
5.3. 答案生成阶段
常见问题
- 未提取:答案与所提供的上下文相符,但大语言模型却无法准确提取。这种情况通常发生在上下文中存在过多噪音或相互冲突的信息时。
- 不完整:尽管能够利用上下文生成答案,但信息缺失会导致对用户查询的答复不完整。格式错误:当prompt中的附加指令格式不正确时,大语言模型可能误解或曲解这些指令,从而导致错误的答案。
- 幻觉:大模型可能会产生误导性或虚假性信息。
如何提升答案生成阶段的质量?
- 改进提示词模板
- 实施动态防护栏
- 改进提示词模板
- 如何对原有的提示词进行优化?
- 可以通过
DeepSeek-R1或QWQ的推理链,对提示词进行优化:- 信息提取:从原始提示词中提取关键信息。
- 需求分析:分析用户的需求,明确用户希望获取的具体信息。
- 提示词优化:根据需求分析的结果,优化提示词,使其更具体、更符合用户的需求。
| 场景 | 原始提示词 | 改进后的提示词 |
|---|---|---|
| 用户询问“如何申请信用卡?” | “根据以下上下文回答问题:如何申请信用卡?” | “根据以下上下文,提取与申请信用卡相关的具体步骤和所需材料:如何申请信用卡?” |
| 用户询问“信用卡的年费是多少?” | “根据以下上下文回答问题:信用卡的年费是多少?” | “根据以下上下文,详细列出不同信用卡的年费信息,并说明是否有减免政策:信用卡的年费是多少?” |
| 用户询问“什么是零存整取?” | “根据以下上下文回答问题:什么是零存整取?” | “根据以下上下文,准确解释零存整取的定义、特点和适用人群,确保信息真实可靠:什么是零存整取?” |
- 实施动态防护栏
- 动态防护栏(Dynamic Guardrails)是一种在生成式AI系统中用于实时监控和调整模型输出的机制,旨在确保生成的内容符合预期、准确且安全。它通过设置规则、约束和反馈机制,动态地干预模型的生成过程,避免生成错误、不完整、不符合格式要求或含有虚假信息(幻觉)的内容。
- 在RAG系统中,动态防护栏的作用尤为重要,因为它可以帮助解决以下问题:
- 未提取:确保模型从上下文中提取了正确的信息。
- 不完整:确保生成的答案覆盖了所有必要的信息。
- 格式错误:确保生成的答案符合指定的格式要求。
- 幻觉:防止模型生成与上下文无关或虚假的信息。
-
场景1:防止未提取
- 用户问题:“如何申请信用卡?”
- 上下文:包含申请信用卡的步骤和所需材料。
- 动态防护栏规则:检查生成的答案是否包含“步骤”和“材料”。如果缺失,提示模型重新生成。
- 示例:
- 错误输出:“申请信用卡需要提供一些材料。”
- 防护栏触发:检测到未提取具体步骤,提示模型补充。
-
场景2:防止不完整
- 用户问题:“信用卡的年费是多少?”
- 上下文:包含不同信用卡的年费信息。
- 动态防护栏规则:检查生成的答案是否列出所有信用卡的年费。如果缺失,提示模型补充。
- 示例:
- 错误输出:“信用卡A的年费是100元。”
- 防护栏触发:检测到未列出所有信用卡的年费,提示模型补充。
-
场景3:防止幻觉
- 用户问题:“什么是零存整取?”
- 上下文:包含零存整取的定义和特点。
- 动态防护栏规则:检查生成的答案是否与上下文一致。如果不一致,提示模型重新生成。
- 示例:
- 错误输出:“零存整取是一种贷款产品。
- 防护栏触发:检测到与上下文不一致,提示模型重新生成。
如何实现动态防护栏技术? 事实性校验规则,在生成阶段,设置规则验证生成内容是否与检索到的知识片段一致。例如,可以使用参考文献验证机制,确保生成内容有可靠来源支持,避免输出矛盾或不合理的回答。
如何制定事实性校验规则?(后置处理)
- 当业务逻辑明确且规则较为固定时,可以人为定义一组规则,比如:
- 规则1:生成的答案必须包含检索到的知识片段中的关键实体(如“年费”、“利率”)。
- 规则2:生成的答案必须符合指定的格式(如步骤列表、表格等)。
- 实施方法:
- 使用正则表达式或关键词匹配来检查生成内容是否符合规则。
- 例如,检查生成内容是否包含“年费”这一关键词,或者是否符合步骤格式(如“1. 登录;2. 设置”)。
6. RAG在不同阶段提升质量的实践
- 数据准备环节,阿里云考虑到文档具有多层标题属性且不同标题之间存在关联性,提出多粒度知识提取方案,按照不同标题级别对文档进行拆分,然后基于 Qwen14B 模型和 RefGPT 训练了一个面向知识提取任务的专属模型,对各个粒度的 chunk 进行知识提取和组合,并通过去重和降噪的过程保证知识不丢失、不冗余。最终将文档知识提取成多个事实型对话,提升检索效果;
- 知识检索环节,哈啰出行采用多路召回的方式,主要是向量召回和搜索召回。其中,向量召回使用了两类,一类是大模型的向量、另一类是传统深度模型向量;搜索召回也是多链路的,包括关键词、ngram等。通过多路召回的方式,可以达到较高的召回查全率。
- 答案生成环节,中国移动为了解决事实性不足或逻辑缺失,采用 FoRAG 两阶段生成策略,首先生成大纲,然后基于大纲扩展生成最终答案。
7. QA
如果LLM可以处理无限上下文了,RAG还有意义吗?
- 效率与成本:LLM处理长上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
- 知识更新:LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
- 可解释性:RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
- 定制化:RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
- 数据隐私:RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
- 结合LLM的生成能力和RAG的检索能力,可以提升整体性能,提供更全面、准确的回答。
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付